At Cerebrium, we frequently work with teams building latency-sensitive AI systems, such as voice agents, realtime video avatars and many other interactive AI applications. Many of them arrive after running into the same issue in their own infrastructure: containers that take far too long to start.
The pattern is familiar. A new model version ships, traffic spikes, and the autoscaler spins up new GPU nodes. The cluster has capacity and the workload schedules correctly. But the container still takes seconds, sometimes minutes, to become ready.
The bottleneck is almost always the container image pull time. Modern ML containers routinely exceed 10GB once you include model weights, CUDA libraries, Python dependencies, and serving code. With today’s container image format, every byte must be downloaded and unpacked before the process can begin.
For applications like voice systems, that delay is unacceptable. If a model cannot start quickly enough, the user experiences silence or lag and the interaction often fails.
This is one of the most common cold start problems we see in ML infrastructure. There are many strategies to achieving low-latency ML inference (model optimization, batching strategies, hardware selection, orchestration) but before any of that matters, your container has to actually be running, and right now, the image pull is often the biggest bottleneck in that chain.
So let's start with how we got here: how a tool designed for magnetic tape in 1979 ended up at the center of modern ML infrastructure, and why it's choking on your 11GB image.
A format designed for magnetic tape
The tar utility (short for "tape archive") was written in 1979 for Unix V7 at Bell Labs. Its job was straightforward: concatenate files into a single sequential stream that could be written to magnetic tape. No index, no random access, no seek support. You wrote files to the tape in order, and you read them back in order. That was the whole point; Tape heads move in one direction.
In 1992, the GNU project released gzip as a free replacement for Unix compress (which relied on a patented LZW algorithm). gzip wraps the DEFLATE compression algorithm into a streaming format. Like tar, it's sequential: you compress from the beginning of the file and decompress from the beginning of the file. There's no way to jump into the middle of a gzip archive and start decompressing from an arbitrary offset.
Combine them, and you get tar.gz: a compressed archive format where you must decompress the entire file sequentially to access any individual file. This was a perfectly reasonable design for 1992. Disks were small, networks were slow, and the typical use case was distributing source code tarballs.
Fast forward to March 2013. Solomon Hykes demos Docker at PyCon, and the container revolution begins. Docker needed a format to package filesystem layers (snapshots of a Linux filesystem at a point in time) and tar.gz was the obvious, pragmatic choice. It was universally available, well-understood, and worked. Every Docker image layer became a gzip-compressed tar archive.
In June 2015 the Open Container Initiative (OCI) was founded under the Linux Foundation to standardize the container image format. The OCI image spec formalized what Docker had already built: images are a JSON document (called a manifest) referencing an ordered list of layers, and each layer is a tar.gz archive identified by its sha256 digest.
That decision to standardize on a format designed for sequential tape access is one we’re still living with. In 2026, 20GB+ machine learning images are still packaged as tar+gzip layers. It is no wonder then, that cold starts for these images take seconds, if not minutes to pull.
How OCI image pulling actually works
Here's what happens when a runtime like containerd pulls an image. It follows a fixed sequence:
Resolve the tag: A
HEADrequest to the registry resolvesllama-inference:latestto a content-addressablesha256digest.Fetch the manifest: The manifest is a JSON document listing the image config and an ordered array of layer descriptors, each with a digest, media type, and size.
Download every layer: Each layer is a gzip-compressed tar archive.
containerddownloads layers in parallel (good), but unpacks them sequentially, one at a time (not so good).Verify and unpack: Each blob is verified against its
sha256digest, then decompressed and extracted onto disk.Stack the layers: The extracted layers are mounted via a union filesystem (usually OverlayFS), with a writable upper layer.
Start the container: Only now, after all of the above is complete, can the container process actually begin.
That last point is the key constraint: the container cannot start until every byte of every layer has been downloaded, verified, and unpacked. There's no partial loading, no "start with what you have," no streaming. It's all or nothing.
For a 500MB web application image, this is annoying. For a 10GB PyTorch + CUDA image, it's a real problem.
The problem isn't the spec, it's the format
It is clear that the layer format has clear structural issues, it was never designed for the access patterns containers actually need. This creates several compounding problems:
No random access. A gzip stream must be decompressed sequentially from the beginning. If your application needs one 4KB config file that lives at the end of a 200MB layer, you still decompress the full 200MB. There's no index, no seek table, no way to jump to a specific file.
Layer-granularity deduplication only. OCI images deduplicate at the layer level: if two images share the same base layer (same sha256 digest), it's stored once on disk. That's useful. But if even a single byte changes in a layer, the entire hash changes and the whole layer must be re-downloaded. As Aleksa Sarai put it in his "Road to OCIv2" post: "if only a single byte in a single package has changed, that's tough, you just have to re-download and store another 50MB."
No cross-layer deduplication. Identical files living in different layers are invisible to the distribution system. Compression makes it worse: the same file content compressed in different tar contexts produces different bytes, so content-addressing can't detect the overlap.
Deleted files aren't free. When a layer deletes a file from a lower layer, it doesn't reclaim space. It instead creates a whiteout marker (.wh.<filename>) in the upper layer. The original data still sits in the lower layer, still gets pulled, and still takes up disk space.
Sequential extraction. containerd unpacks layers one at a time. A containerd proposal demonstrated that just parallelizing the unpack step on a 5.4GB image dropped pull time from 120 seconds to 40 seconds, a marked 3x improvement.
How much of the image actually matters?
In 2016, researchers at the University of Wisconsin-Madison published a paper at USENIX FAST called "Slacker: Fast Distribution with Lazy Docker Containers." Their key finding:
Pulling packages accounts for 76% of container start time, but only 6.4% of that data is read.
Three-quarters of container startup is spent on the pull, and the container only touches a tiny fraction of what is downloaded. The median image in their study was 117MB compressed, but containers typically read around 20MB during startup. The rest just sits there, on disk, waiting for access patterns that may never come.
The problem is getting worse, not better
The Slacker study was done in 2016 when images were smaller. Apply the same ratio to a 10GB ML image: you're potentially downloading 10GB so the container can read ~640MB at startup. Even on a fast network that's still minutes of pull time. Minutes where your instance isn't serving requests.
When Docker popularized container images in 2013, a typical image was tens of megabytes. Today, the landscape looks different:
Image type | Typical size |
|---|---|
Alpine base | ~5 MB |
Ubuntu base | ~29 MB compressed |
Typical web app | 200 MB – 1 GB |
PyTorch + CUDA | 7 – 13 GB |
Full ML training stack (NVIDIA NGC) | 4.5+ GB compressed |
What Cerebrium did to fix this
The Slacker paper pointed directly at the fix: if containers only read 6.4% of image data at startup, why are we requiring 100% to be present before starting?
An ideal container image distribution system would:
Start the container before the full image is downloaded. Fetch a lightweight metadata index first, then pull actual file data on-demand as the container accesses it.
Operate at finer granularity than whole layers. Fetch individual chunks or files, not entire compressed tarballs.
Deduplicate across layers and images. At the chunk or file level, not just at the layer level.
Verify data integrity continuously. Not just once at download time, but on every read, so partial fetches are still trustworthy.
Not require a completely new registry infrastructure. Work with the registries and tooling that already exist.
None of these properties are impossible. Several projects in the container ecosystem have been tackling them from different angles: lazy-loading, seekable archives, chunk-based filesystems, kernel-level image mounting. The approaches differ, but they all start from the same observation: the tar+gzip layer model was designed for a simpler era, and ML-scale images have exposed its limits.
To make this work in practice, you have to untangle something OCI layers bundle together: filesystem metadata and file content.
A table of contents for your image
In a standard OCI image, metadata and data are tangled together inside tar archives. The directory structure, file permissions, timestamps; all of it is interleaved with the actual file content inside each compressed layer. To learn anything about what files exist, you have to download and decompress the layer.
The fix is to split the image into two distinct parts:
A metadata index: a small binary file containing the complete filesystem tree. Every directory, every file name, every permission bit, and every symlink target, as well as a mapping of where each file's data lives. It's everything a container needs to know about its filesystem without any of the actual file content. For a real-world image, this index is typically in the hundreds of kilobytes.
Data blobs: the actual file content, split into fixed-size chunks. No filesystem metadata, no directory structure. Just content, chunked and compressed.
The metadata index is small enough to pull in milliseconds. Once you have it, you have a complete picture of the filesystem: you know every file, every directory, every chunk of data and where to find it. The container can start immediately. Actual file content gets fetched on-demand, chunk by chunk, only when the container reads it.
How do we build this type of image?
A container image is just a filesystem, packaged up. Normally, you write a Dockerfile (a sequence of instructions like FROM, RUN, COPY) and run docker build. Each instruction produces a layer: a tar+gzip archive of the filesystem changes that instruction made. Stack the layers, and you have a filesystem a container can be pointed at.
Building this type of image starts the same way. You write the same Dockerfile, run the same build. But then a conversion step takes that standard OCI image and restructures it. The layers are unpacked, and the files inside are walked and split into small chunks, usually 1MB each. Each chunk is independently compressed with zstd. A 4.5MB file becomes 5 chunks. A 200KB file fits in a single chunk. The chunks from all files in a layer are packed sequentially into a data blob.
Every chunk is then hashed. The SHA-256 digest of its uncompressed content becomes its identity. Two chunks with the same bytes produce the same digest, regardless of which file, layer, or image they came from. This is what makes the format content-addressable: chunks aren't identified by where they are, but by what they contain.
That identity is what enables deduplication. If two layers (or two entirely different images) contain an identical 1MB chunk, it's stored once and referenced by its digest. Think about how many container images share the same base OS packages, the same Python runtime, the same system libraries. In the OCI model, a single byte change anywhere in a layer invalidates the entire layer hash, and the whole thing gets re-downloaded and re-stored. With chunk-level content addressing, only the chunks that actually changed are new. Everything else is already present and already verified.
The metadata index ties it all together. For each chunk, it records the digest, which blob it lives in, at what byte offset, and how large it is when compressed. Given a chunk's digest, the runtime can issue a precise HTTP Range request for exactly the bytes it needs.
Containers aren't magic
A container is just a Linux process. The kernel uses a syscall pivot_root to point it at a directory and say "this is your root filesystem now." The process makes standard syscalls (open(), read(), stat()). It doesn't know or care where the files actually come from.
Which means as long as something answers those syscalls correctly, the container works. The files could be on a local disk, or they could be fetched on-demand from a registry on the other side of the world.
Two ways to serve the filesystem
Once you have a metadata index and chunked data blobs, you need something to actually serve filesystem requests from the container. There are two common approaches.
FUSE: userspace daemon
On Linux, FUSE (Filesystem in Userspace) is a kernel interface that forwards filesystem operations to a userspace process (if you haven't come across FUSE before, it's a rabbit hole worth going down).
The kernel side is thin: it just queues requests and passes them along. The actual logic (looking up the chunk map, checking the local cache, and fetching from the registry on a miss) lives in a daemon process defined in userspace.
A FUSE-based daemon intercepts filesystem calls via the kernel's FUSE driver and translates them into chunk fetches. Here's the full I/O path:
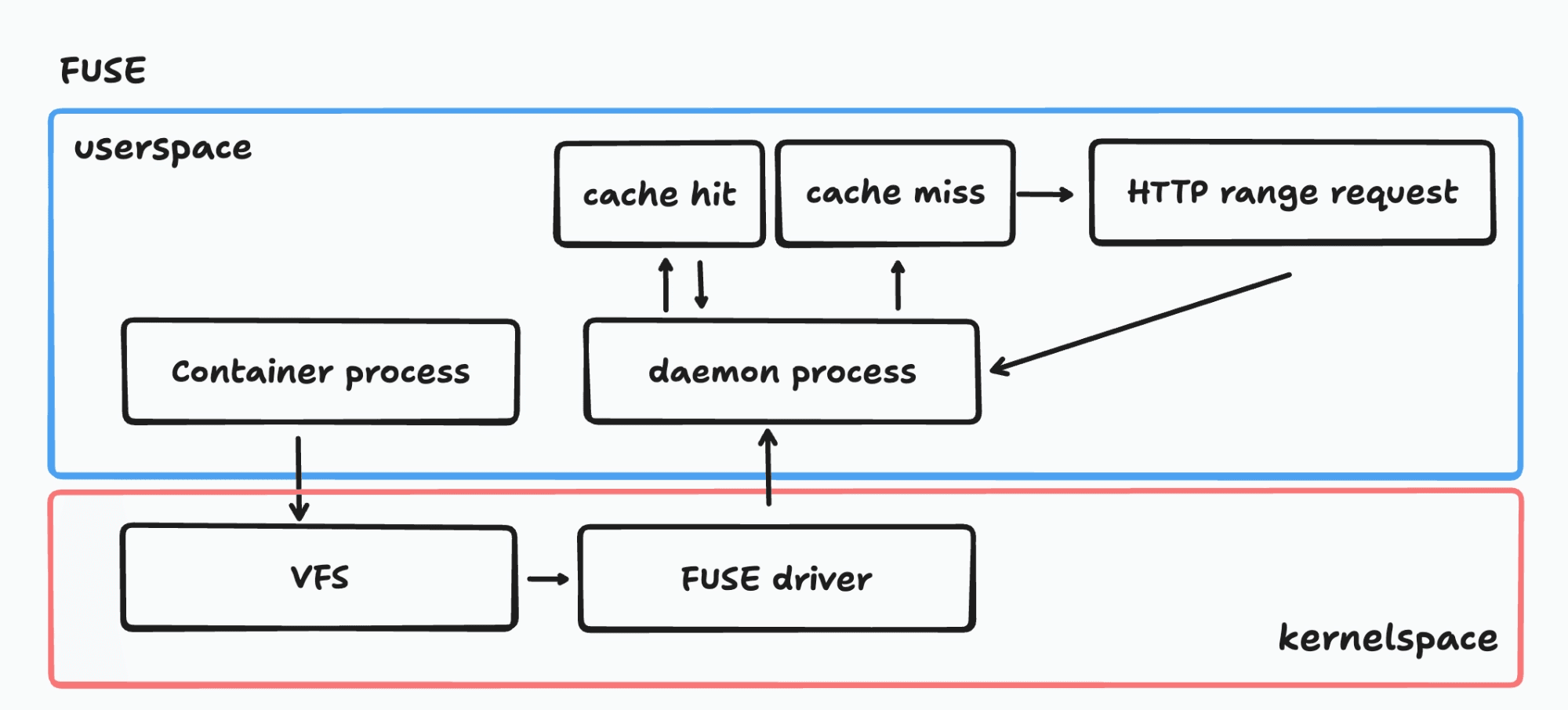
Every file read (even on a cache hit) requires two context switches between kernel and userspace. This works on any Linux kernel with FUSE support, and it's the simpler operational model. But those context switches add up: benchmarks show FUSE-based approaches at roughly 70-76% of native ext4 performance for I/O-bound workloads.
In-kernel: EROFS + fscache
The higher-performance path. Instead of FUSE, you can use the in-kernel EROFS (Enhanced Read-Only File System) driver with Linux's fscache subsystem for on-demand data loading. EROFS was merged into Linux 5.19.
On a cache hit, the path is entirely in-kernel:
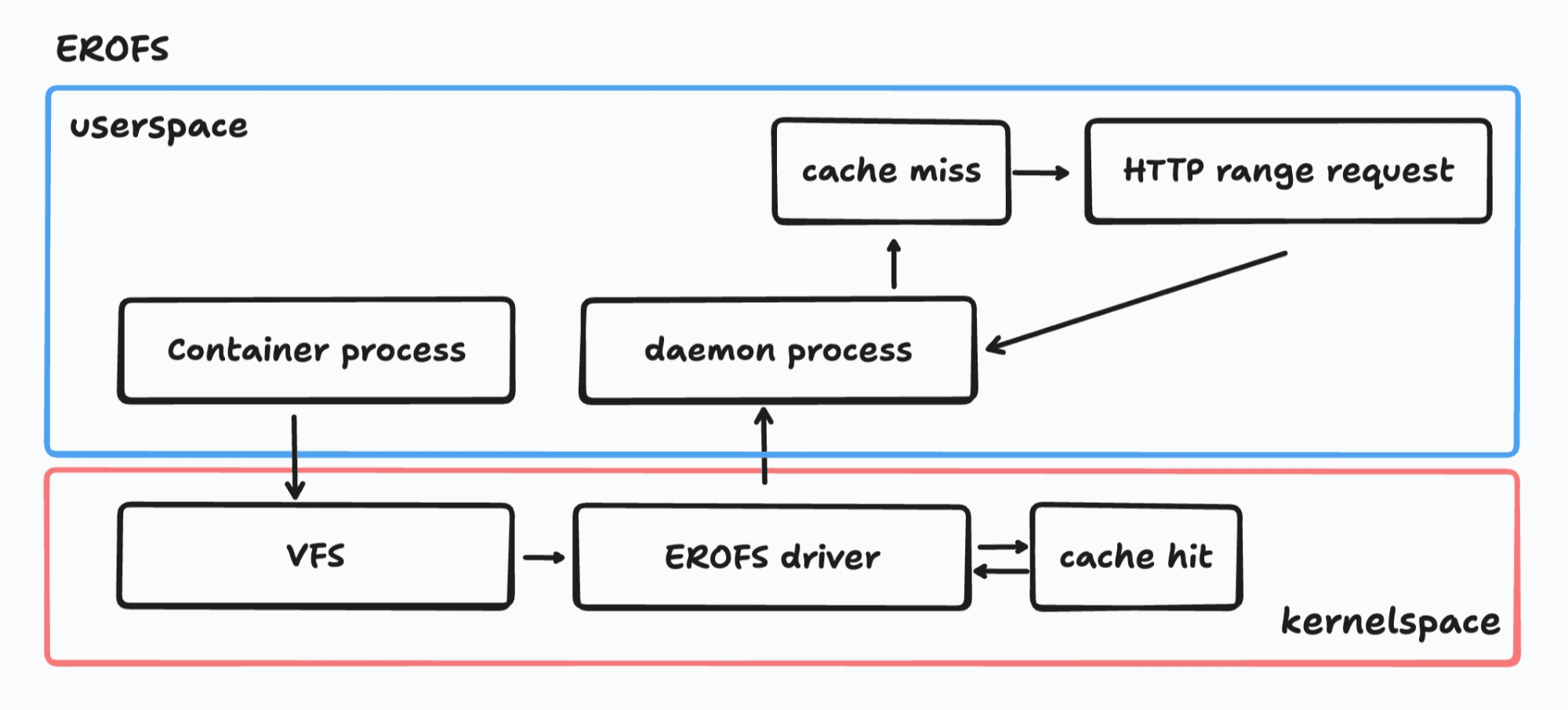
No context switches. No userspace daemon in the hot path. The data goes straight from the page cache to the process.
On a cache miss, the fscache subsystem sends an on-demand request to a userspace daemon, which fetches the chunk from the remote registry, writes it to the cache, and wakes the sleeping process. From that point on, the chunk is served from cache (the kernel path).
The performance difference is significant. The EROFS path reaches 85-93% of native ext4 performance on I/O benchmarks, and achieves full parity with ext4 on real workloads like Linux kernel compilation. Metadata operations (stat, readdir on many small files) are actually faster than ext4 (roughly 1.8x) because EROFS uses a more compact on-disk layout than ext4's general-purpose design.
What was the performance difference
At Cerebrium we measured three modes of startup on the same workload:
Traditional OCI pull (download + unpack the image before the container starts)
Lazy pulling (fetch metadata first and load file data on-demand)
Lazy pulling + background prefetch (data on-demand plus prefetch to warm rest of the image)
The test image was 4.87GB, based on nvidia/cuda:12.1.1-runtime-ubuntu22.04. Each experiment was run five times and averaged.
To eliminate network variability, the registry was running locally on the same machine. Tests were performed on an AWS g6.12xlarge instance with 10 background prefetch threads enabled for the prefetch case.
The workload measured time to first inference by loading the stabilityai/stable-diffusion-2-1 model from network storage and generating an image.
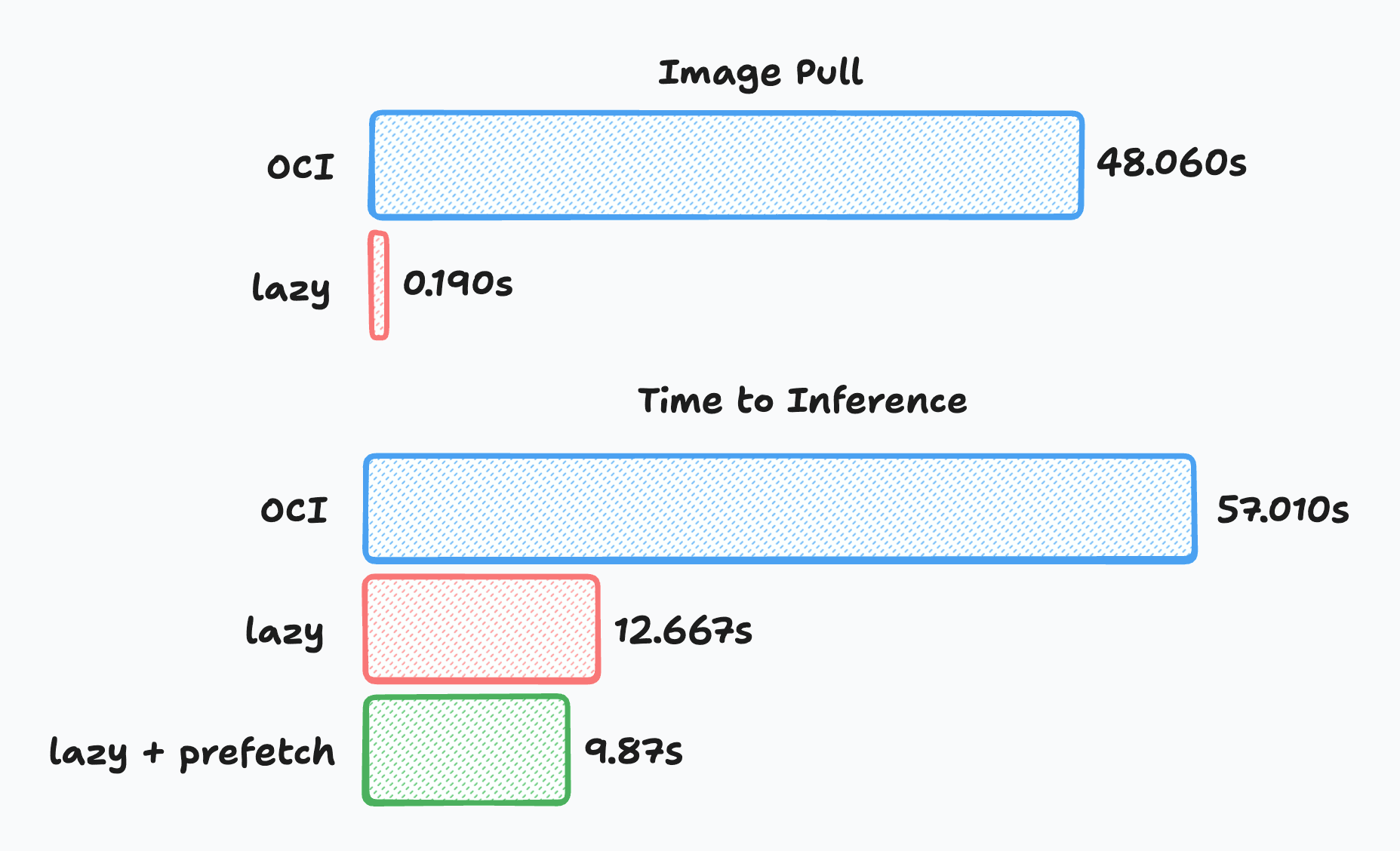
The container start time comparison is somewhat misleading on its own. A traditional pull must download and unpack the entire 4.87GB image, while the lazy-loading path only downloads a ~15MB metadata bootstrap before the container can start.
The more meaningful metric is time to first inference.
Lazy-loaded containers take slightly longer between container start → model inference because some file reads trigger on-demand fetches. However, that overhead is small compared to the time saved by avoiding the full image pull.
Even though the lazy path performs some network reads during startup, the container begins executing far earlier, which significantly reduces overall time to serving the first request.
Adding background prefetching further reduces the penalty of on-demand reads by warming the remaining image data while the application is initializing.
These results come from a deliberately simple setup with minimal tuning. For production workloads at Cerebrium we apply additional optimizations on top of lazy loading, including smarter prefetching, file caching, and image layout improvements, which further reduce cold start times for large ML workloads.
Putting it all together
Many of our customers run extremely demanding workloads - they have low latency requirements, spiky demand with sharp peaks and troughs and container images in the 10’s of gigabytes. In order for them to provide a consistent user experience to handle these situations while keeping costs low we needed to rethink the stack in order to maximize utilization. ie: Spin up capacity up fast, serve requests, and spin it down again without paying the tax of slow pulls and making sure our customers only pay for usage.
Fixing those problems required rethinking multiple layers of the stack: how images are packaged, how file data is fetched, how the filesystem serves reads, and how caching works across NVMe disks and registries. In this article, we covered some of the foundational implementations we have done as as a team at Cerebrium in order to achieve this and have many more optimizations across the stack around the storage layer, networking layer and routing layer in order to achieve the results we do.
If you're building on GPUs and tired of waiting for containers to pull, come check us out.