Maybe you started with a modest CLAUDE.md or AGENTS.md, which you meaningfully crafted over time. Then you adding some core docs (which was best practice anyway), like ARCHITECTURE.md. Before you knew it, you were writing massive specs and generating full-blown features. A lot of those specs shared a lot of context. Never one to miss an optimization, you yanked out the boilerplate and made some Markdown files.
Thus, your /docs directory was born. Not from some strategic plan, but as a natural response to your need for more context. As /docs filled up, you may have even created sub-directories, or a table of context. If you have taken things this far, you are in good company - this is the exact approach OpenAI uses internally.
How we think about and manage context has evolved quite a bit in a few short months. Every step forward has been reasonable and natural, but recognize that your /docs directory is a temporary solution. As you add more docs while changing code, subtle inconsistencies are beginning to pile up. Over time, the context your LLM need to generate code is degrading and there is no easy way to add observability.
Some looming issues to consider if you have a growing /docs directory of Markdown:
- Discoverability: How does an LLM know it should read a specific document? Will it be referenced at the right time, during planning and generation?
- Ownership and domain expertise: If context docs are part of the codebase, who writes and maintains them? If you have a mid-sized company, you probably don't want engineers maintaining docs about DevOps or design patterns. But what if there is a code change that adjusts timeouts or revises a frontend theme. How do you manage this?
- Doc rot: Even well-maintained documentation devolves over time as small mistakes, repetitions and inconsistencies occur between docs. LLMs can help, but if LLMs manage consistency blindly our docs start to lose the plot. "Vibe documenting" might not crash the server, but we have no observability when a doc is wrong. If our context is wrong, code generation degrades with no smoking gun and no clear path to resolve it.
- Velocity mismatch: Context changes at different speeds. Codebase context can change with every commit, but a high-level architecture doc might not change for months. If we have 200 docs, how should we manage docs at different rates?
- Lack of hierarchy: There is no inherent structure connecting or orienting context documents. Documents may be linked conceptually or sorted into directories, but LLMs lack a clear way to navigate documents.
- Bespoke doc structure: Everyone writes context docs in their own way. Your docs may be well structured, but it is unclear if your structure is useful for how an LLM navigates and consumes information.
These are thorny issues. Larger companies may have internal solutions for some of these, but they are non-trivial.
LLMs Won't Save Us
It is easy to turn passive and think the next model might solve context management for us. They are certainly trying to do just that. But context is only adjacent to code generation. LLMs can get better at inferring context from code or using it effectively, but producing and managing context is an entirely different problem.
Context is a blueprint that defines how our product exists (or should exist) in the world. It isn't something a model can generate without us, because the context we give an LLM describe intent or usage, and sets real world boundaries. "Context" is an amalgam of concepts that leads to the code, not something that can be extracted from it. This begs the question:
If context is so important, why are we managing it with a solution straight out of 1985?
Steps to a Better Context
We have been stumbling down (or dragged along) a path to better context management, but have only done enough to get our LLMs past the next context hurdle. We are now at the point where our meager context is the biggest blocker to progress. We can see this clearly when comparing how much we can accomplish in greenfield projects vs. established projects, which have significantly more real world context to navigate.
If we prioritize writing and managing context as a primary objective, we can dramatically improve our LLM effectiveness. Writing the docs themselves is the easy part. Injecting that context appropriately and managing that context reliably are much trickier challenges.
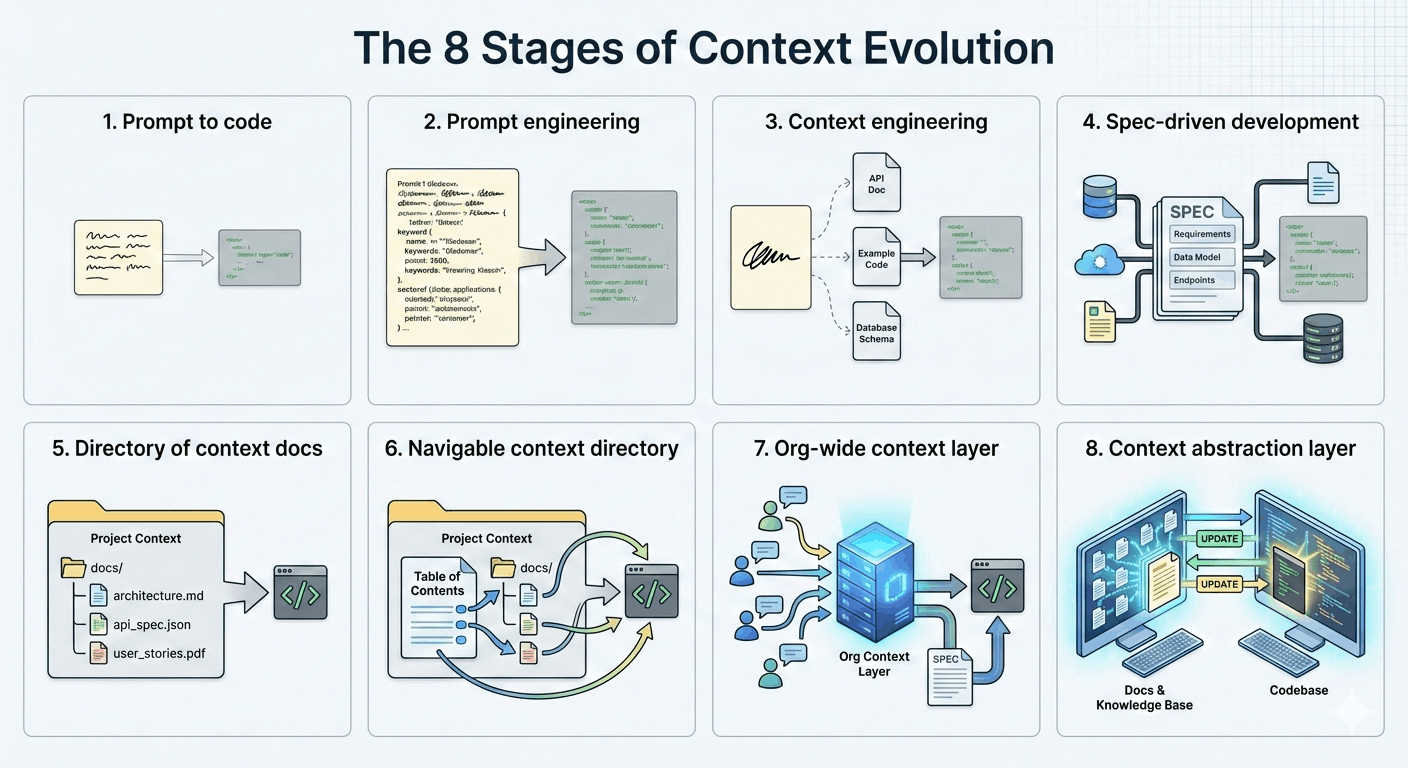
Most of us are somewhere around Stage 5 - pretty good! But to get to Stage 8, we need to dramatically revise how we think about context:
Context should be owned by the organization. We use context documents for code generation and store them in our codebase, but they are not really a part of our codebase. Most meaningful context that engineers pass to an LLM is cribbed from project details and is the result of decisions made by individuals who are not engineers. Instead of passing around and distilling things haphazardly, domain experts should manage their context directly. This is the barrier for Stage 7, which is an organizational shift more than a technical one.
Context must be navigable. Context needs its own architecture and internal relationships, so LLMs and humans can discover and manage context as an interconnected web of information, not as isolated documents.
Context must be composable. Context needs a hierarchy to clarify the relationships between its parts. We build processes from concepts, and likewise should build process context on top of concept context. This creates a hierarchical relationship that lets LLMs navigate in a deterministic way.
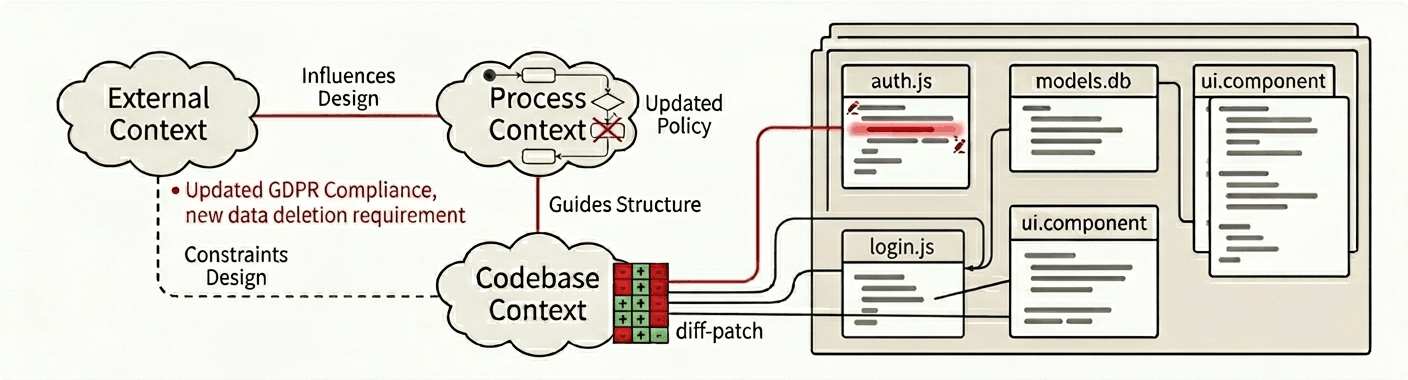
Context must be code-aware. "Doc rot" is a major problem because there are no obvious triggers when a doc is out of date. Codebase context is most vulnerable, because every commit can change the underlying context in subtle ways. To manage this, we can directly map context about the codeebase to the code itself. This creates a feedback loop that keeps our code and context in sync.
Context-Driven Development (CDD)
Focusing on context instead of code may seem like a "nice to have" approach that hinders velocity, but it leads to some interesting outcomes.
"Code-aware" documentation creates a bidirectional relationship that turns context into a true abstraction layer that sits on top of the code. This has huge implications for how we are able to understand, navigate and modify our product.
Once our docs are linked directly to code, LLMs can recognize and manage inconsistencies between the two. Beyond that, this link can be used to generate automatic updates that dynamically resolve changes in the docs or changes in code.
Editing context docs to produce code may sound like vibe coding, but it is almost the antithesis. When you vibe code, you:
- Describe what you want to build
- Review the output / interact with the app
- Iterate
You advance your product in steps based on your personal understanding of the product's current state. If you lose sight of how the code works under the hood, you can ask the LLM to describe its state. This is an ad-hoc arrangement that will eventually overwhelm your mental model, because you are building without a clear source of truth.
With CDD, context is tightly coupled to your codebase. Every detail or abstraction can be examined in either the docs or the code. Context docs are not just summaries of behavior, but functional tools that define and connect intent to implementation. Context docs become a source of truth for the decisions and external factors behind your product's design.
By linking context to code, we always maintain sight the codebase structure and can always "drop in" to edit or review the code manually. Human understanding becomes the priority.