If you tuned in to Monster Scale Summit this year, you may have seen our talk on migrating the American Express Payments Network - not once, but twice — with zero customer-impacting downtime — meaning no transactions were interrupted and no planned maintenance windows were required during either migration. The session focused on how we moved live payments traffic reliably under strict operational constraints. If you missed it, the talk is available to watch on the Monster Scale Summit website.
This article expands on the conference talk and dives deeper into the engineering decisions, tradeoffs, and lessons learned across both migrations.
Context: The Payments Network
The payments network is a mission-critical distributed system responsible for processing critical payments traffic, including live card authorization. It serves as the bridge between American Express merchants, acquirers, and issuers globally.
This platform must be continuously available, operate at low latency, and handle large volumes of critical traffic.
Migration Constraints
In 2018, American Express began a multi-year modernization of our payments network, including migrating from a legacy platform to a new microservices-based architecture.
A migration of this scale had to operate within several non-negotiable constraints:
- The migration had to be performed online, with no planned or unplanned downtime.
- The new platform had to reimplement existing payment processing logic; regressions in functionality were not acceptable.
- Latency, throughput, and resiliency characteristics had to remain consistent, and in some cases improve.
- Payment requests could not be dropped, delayed, or left unanswered.
Not only did we need to migrate under these constraints once - we needed to do it twice.
Migration #1: From the Legacy Payments Network to the New Platform
The first migration involved transitioning live card authorization traffic from the legacy payments network to a new, modernized platform.
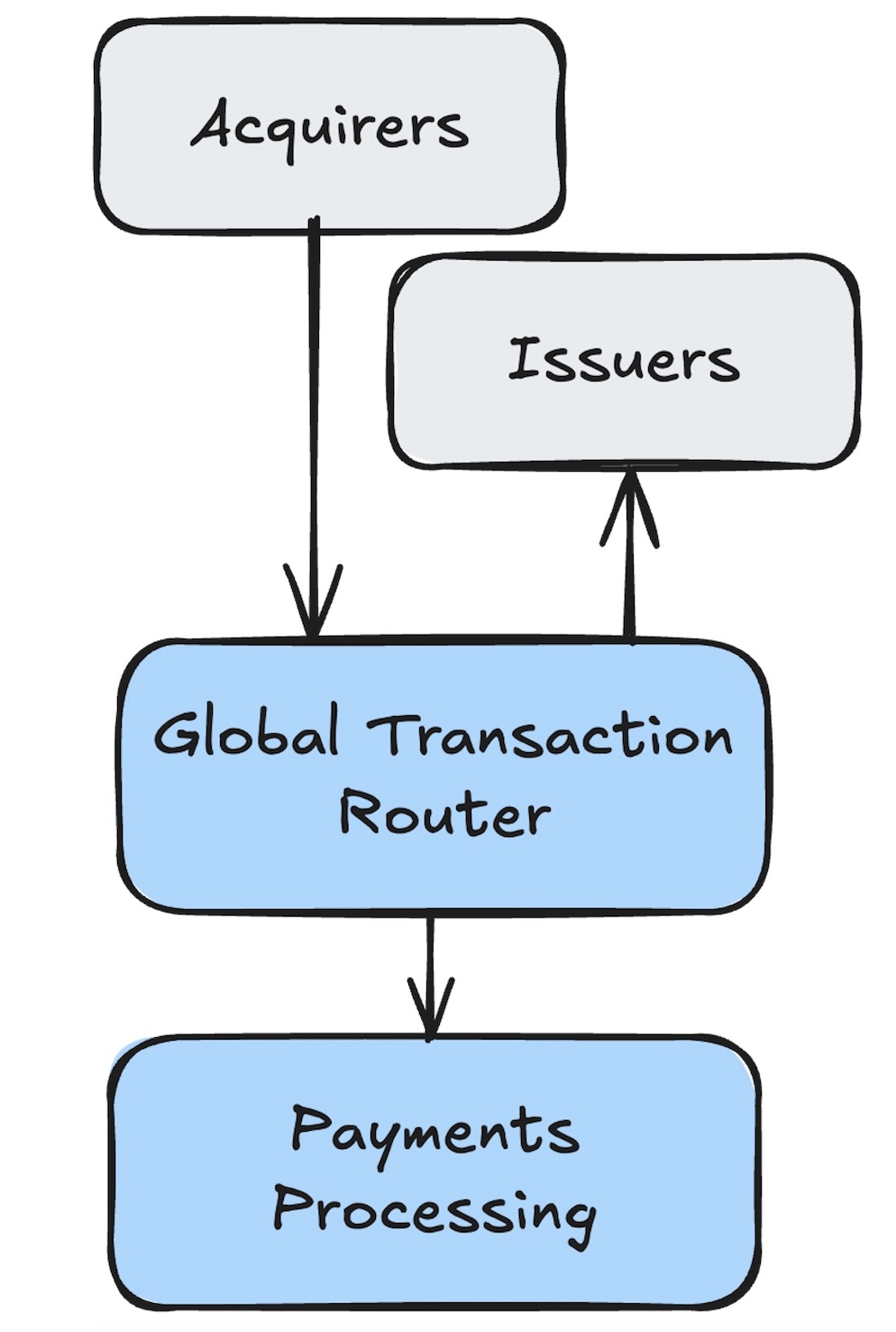
While the payments network is large and complex, real-time card authorization traffic is primarily handled by two subsystems: a routing layer (which we’ll refer to as the “Global Transaction Router” or “GTR”, for simplicity) and the payments processing platform.

Understanding these two subsystems is key to understanding how we approached the migration.
Global Transaction Router (GTR)
The GTR acts as the gateway into the payments network. Unlike typical backend platforms, card authorization traffic is primarily sent over long-lived TCP connections carrying ISO8583 messages, a message format specific to payments.
The GTR manages these long-lived connections from acquirers and issuers and routes incoming transactions to the payments processing platform. It is also responsible for routing responses from the payments processing platform to network participants.
The router intentionally implements a minimal understanding of payment protocols - just enough to make routing decisions. Its primary role is to make routing, failover, and traffic-shaping decisions without owning payment processing logic.
Acting as the gateway, the GTR also provides centralized traffic control and resiliency for the payments network. It sits at the edge of the payments network and is highly specialized, optimized for low latency and high throughput.
Payments Processing Platform
The payments processing platform is where the complex, business-critical payment processing logic lives.
This platform is implemented as a microservices-based architecture, consisting of numerous services and databases. As transactions flow through the payments network, the payments processing platform validates, enriches, and transforms them.
This logic has been developed and refined over many years. Rebuilding this logic was a significant undertaking, and ensuring parity with the legacy system was critical.
Migration Strategy
Rebuilding the full payments network from scratch was a significant, multi-year effort. It involves complex processing logic, extensive edge cases, and exception handling. Waiting for full platform completion before migrating live traffic was not an option. Building new functionality would require building in both the legacy and new systems, leading to duplicated effort and increased risk of functionality drift.
Instead, we broke the migration into three stages:
- Stage 1: Connection Migration
- Stage 2: Shadow Traffic
- Stage 3: Canary Routing
Stage 1: Connection Migration
In the first stage, we wanted to introduce the GTR into the flow of transactions. This was the most critical stage of the migration - it enabled every other stage and was the first time a new component was inserted into the live traffic path.

When new connections landed on the GTR, it routed all traffic to the legacy payments network. This allowed us to introduce the GTR without requiring processing logic parity.
For each incoming connection, the GTR established a corresponding connection to the legacy payments network. Any transaction received on the incoming connection was forwarded to the legacy payments network over the downstream connection. No logic, no message parsing, just simple forwarding.
This approach allowed us to insert centralized traffic control and resiliency into the payments network with minimal risk. To reduce risk further, we migrated connections in small batches, monitoring system health and performance closely. Observability and metrics from the GTR were critical during this stage.
Stage 2: Shadow Traffic
With the GTR in place, we were able to introduce shadow traffic to the new payments processing platform.
Shadow traffic is, at its core, a replay of live production traffic. We deployed a dedicated production instance of the new payments processing platform and replayed a copy of live traffic to it.

If there were any functional discrepancies between the legacy and new payments processing platform, they would show up here.
This shadow traffic capability allowed us to validate payment processing logic in a production-like environment without impacting live traffic. It did not replace traditional unit and functional testing, but rather it provided a final validation step before routing live traffic to the new platform.
Stage 3: Canary Routing
With processing logic validated via shadow traffic and the GTR in place, we were ready to route live traffic to the new payments processing platform.
We applied canary deployment principles to the platform migration. We extended the GTR with just enough understanding of payment protocols to make routing decisions based on transaction attributes.

This allowed us to take small percentages of live traffic and route them to the new payments processing platform. As functionality was ready, we identified customer segments and transaction types that could be routed to the new platform.
The GTR took care of routing these transactions to the appropriate backend platform based on the canary configurations. All canary decisions were enforced centrally by the GTR, before transactions reached the payments processing platform. This canary routing capability was implemented as custom logic within the GTR to support this migration and has since become a critical component of the Payments Network architecture.
We started with 1%; when everything looked good, we increased to 5%, then 10%, and so on.
If anomalies were detected, we immediately reverted all routing back to the legacy payments network. This gradual approach allowed us to migrate live traffic with minimal risk. We avoided any big-bang cutovers or customer impacts.
In addition to reducing risk, this approach reduced duplicated development effort. It allowed the platform to evolve with real traffic without needing to maintain two separate codebases for an extended period.
Migration #2: Kubernetes Infrastructure Migration
After the new payments processing platform was operational, we faced a second major migration that reused the same traffic control patterns established during the platform migration. We needed to move from a legacy Kubernetes infrastructure to a new Kubernetes environment.

Due to significant differences in networking, security, and operational practices between the two environments, an in-place migration was not feasible. This required a full rebuild of the payments network infrastructure in the new Kubernetes environment.
This meant we needed to migrate live traffic again - with zero downtime. Latency, throughput, and resiliency characteristics had to remain consistent as well.
Environment Setup and Validation
The first step in this migration was establishing the new Kubernetes environment in a repeatable and consistent manner. We leveraged infrastructure-as-code to ensure consistency and repeatability across test and production environments.

Existing pod and service configurations were exported from our existing production environment. They were redefined as declarative infrastructure-as-code configurations.
This approach ensured consistency across regions and environments. It took time to get right, but once we had a solid foundation, we could spin up new environments quickly, both for the initial migration and future expansions. Any new infrastructure changes now start with infrastructure-as-code definitions.
Performance and Resiliency Testing
With the new environment established, we validated that it could meet our performance and resiliency requirements. We first established a performance baseline in our existing environment. We then deployed the same application versions into the new environment and ran load tests to compare performance characteristics. The new environment exhibited differences that required tuning.
We implemented those tuning changes via infrastructure-as-code and rolled them out to all environments.
Resiliency testing followed a similar approach. We ran various failure scenarios in the existing environment, documented the results, and then ran the same scenarios in the new environment. Any discrepancies were investigated and resolved via infrastructure-as-code changes.
Before moving any traffic, we ensured the new environment met or exceeded all performance and resiliency requirements.
Canary — Again
With the new environment validated, we were ready to migrate live traffic again - with zero downtime.

We reused the same canary routing strategy from the first migration. This time, we were routing traffic between two identical payments processing platforms. External ISO8583 connectivity continued to terminate at the edge; canary routing was applied only to internal gRPC Remote Procedure Calls (gRPC) traffic between the GTR and the payments processing platform.
As we built the GTR, we implemented canary deployments leveraging Envoy Proxy and a custom control plane. While our initial implementation was focused on routing between different versions within the same region, we extended this capability to route between different regions.
We called this multi-region canary routing. This allowed us to route all traffic from one region to another. With traffic re-routed, it freed us to enable the new Kubernetes environment in the original region.
Once ready, we routed percentages of traffic back to the original region, now running the new Kubernetes environment. We gradually increased traffic back to the original region, monitoring system health and performance closely.
Observability was as critical to this step as the canary routing itself. Our business metrics, application logs, and application health metrics all gave us visibility into how the new environment was performing under live traffic. If issues were detected, we could quickly revert all traffic back to the secondary region.
Lessons Learned
Both migrations were significant undertakings, and we learned a lot along the way.
Traffic Control was Essential
The GTR and Envoy Proxy-based canary routing were essential components of both migrations. They provided the traffic control needed to safely route live traffic between different platforms and environments.
These capabilities were initially developed as glue code, but over time evolved into critical components of our payments network architecture.
Rolling Back is a First-Class Capability
In both migrations, the ability to quickly and safely roll back changes was essential. Designing systems and processes with rollback in mind reduced risk and allowed us to respond quickly to any issues that arose.
Invest in Observability
Observability was critical to the success of both migrations. Having deep visibility into system health, performance, and business metrics allowed us to make informed decisions during the migrations.
Shadow Traffic is Invaluable
The shadow traffic capability provided a final validation step before routing live traffic to the new payments processing platform. This capability was essential in identifying any unknown discrepancies between the legacy and new systems.
We’ve since leveraged this capability for ongoing testing and validation of new features and changes. We are also using this capability to validate other downstream systems migrations.
Infrastructure-as-Code is Non-Negotiable
Leveraging infrastructure-as-code for the Kubernetes migration ensured consistency and repeatability. It allowed us to manage complex infrastructure changes with confidence, and it set the foundation for future expansions.
The Most Important Lesson
The most important lesson was patience and discipline. In payments, success is measured in reliability, even if it takes longer to get there.