TLDR; get a list of 21,864 domains from the former Yugoslavia’s “.yu” top level domain: download the .CSV
In 2010 the entire domain space of Yugoslavia (.yu) was taken off the internet. After all, the country didn’t exist anymore.
I heard about this from an interview with Kaloyan Kolev on Agnes Bytes’ “Archiving the Web”. Kaloyan had several interesting insights:
- We’ve baked the concept of “countries” into the Internet domain system. And that makes domain names tied to real-world territorial conflicts, countries splitting apart and countries going underwater (like Tuvalu)
- .yu is an early example of something that will happen more and more often.
- It is unfortunate that we didn’t preserve the .yu domain space like a nostalgic Internet memorial to the country. Instead, the sites became unmoored and unreachable.
Kaloyan referred to the research paper “What does the Web remember of its deleted past? An archival reconstruction of the former Yugoslav top-level domain” by Anat Ben-David. In that paper, Ms. Ben-David reconstructed a network graph of .yu domains from the Internet Archive’s Wayback Machine.
Ben-David’s paper used the below sources as seed lists:
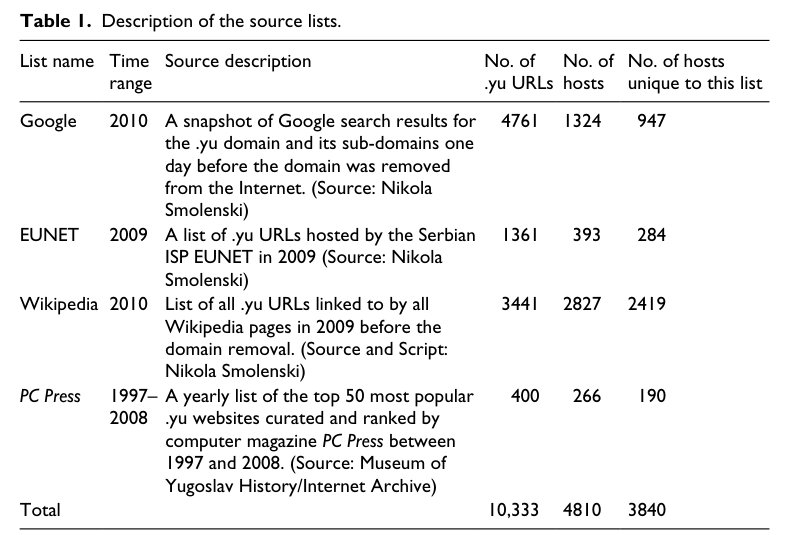
By crawling links from these pages to other .yu URLs, she eventually found 17,460 unique websites in the .yu domain.
The adventure begins
Dear Reader: after hearing all this, I bellowed out a mighty
Akshuallyyyyyyyy!
I dropped my bag of mini M&Ms onto the house robe I was wearing. Unshaven and red eyed, I yelled up from the basement: “MOM, fire up the router! I’m going on an Internet Adventure!!!!”.
You see, I figured I was good enough to discover all the archived domains under the .yu TLD. After all, last time I had an akshually moment, good things happened!
At first I tried doing a wildcard search for all *.yu domains at the Wayback Machine. That didn’t work.
The CDX API – a dead(ish) end
Then, I discovered that the Wayback Machine has a “CDX Server” API that can tell us if a page is archived or not.
Here is the documentation for the CDX API.
Below is an example of a CDX query that grabs all the unique file paths at the domain “jacobfilipp.com”, filters them down only to HTML files that were successfully fetched (status starts with a 2), and shows you only the first 10 that are archived at the Wayback Machine.
https://web.archive.org/cdx/search/cdx?url=jacobfilipp.com&matchType=host&collapse=urlkey&filter=mimetype:text/html&filter=statuscode:^2&limit=10Unfortunately you can’t easily fetch all archived URLs under the TLD “.yu”.
However, if you try, you get a message that says “Forbidden: This type of CDX query requires authorization.” Which tells me that you could do this if you politely ask the staff at the Internet Archive.
What does work is fetching all the files under the Yugoslavian subdomains like *.co.yu and *.org.yu and *.ac.yu.
Here is an example of fetching all the URLs under *.co.yu:
https://web.archive.org/cdx/search/cdx?url=*.co.yu&collapse=urlkey&filter=mimetype:text/html&limit=1000You’d need to paginate through all the results, and it’s slow.
WWW.YU to the rescue
While tinkering with the CDX API, I landed by mistake on the site “www.yu”. I believe this site was run by Yugoslavian ISP “Memodata”.
What’s special about it, is it has a list of just about every registered .yu domain:
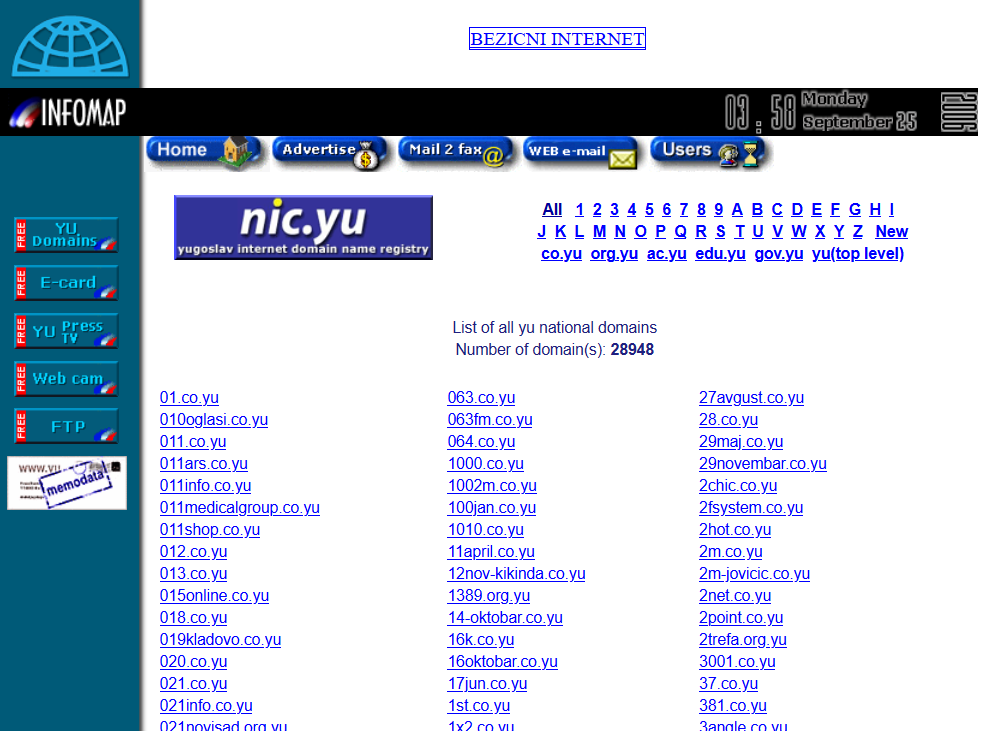
I went ahead and used my newfound CDX skills to download a list of all indexed “domain listing” pages. Not all of them are in the Wayback Machine: most listings stop at “page 20” of each letter.
Then, I downloaded all those pages locally using wget (use the id_ URL trick to get a page with un-altered URLs), and extracted all the .yu domain names from the links inside.
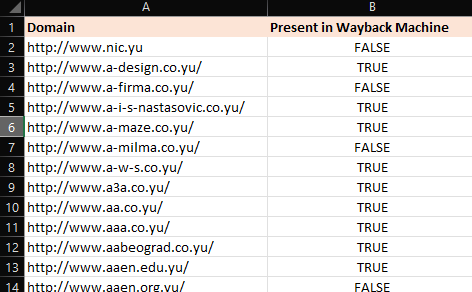
Finally, looping through each domain name, I used the CDX endpoint to check whether the domain is in the Archive or not.
End result:
21,864 domains with 13,292 of them having an archived copy in the Wayback Machine.
Download the entire list as .CSV below:
An exercise for the reader
While writing this post, I realized that the parent of www.yu – memodata.net – also has a list of domains. Theoretically it is the same list of domains. But, practically, the Wayback Machine might have indexed alphabetical listing pages that it didn’t index for www.yu. You’d have to grab all the listings pages using the CDX API and extract the domains.
If you really need more .yu domains, Nikola Smolenski and Anat Ben-David are easy to find online. You should ask them nicely – I bet they have their lists saved somewhere.