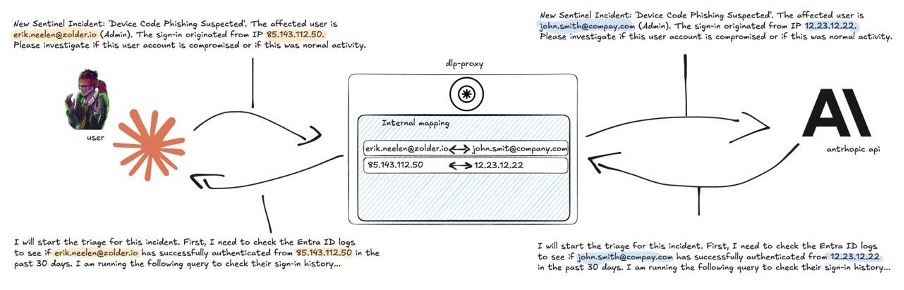
We have been building a Ghost Analyst on top of Anthropic’s Claude to triage Microsoft Sentinel and Defender incidents. The flow is straightforward:
- An alert fires.
- The agent pulls the relevant Entra ID logs.
- The agent writes the KQL queries it needs.
- An analyst gets a clean triage report on the other side.
The catch is that triage data contains client IPs, usernames, internal hostnames and corporate domains. Sending all of that to a cloud model is not something we want to do without a filter in front of it. Running a local model would solve the privacy problem, but no open-source model we tested came close to Claude Opus on this kind of reasoning. We needed a middle ground: keep using a frontier model, keep client data out of it.
So we built a Data Loss Prevention layer.

Our approach
The proxy sits between the agent and the Anthropic API:
- It pseudonymizes sensitive data on the way out.
- It restores the originals on the way back.
- The LLM never sees real data. The analyst never sees fake data.
That is the easy version of the story. In practice, hiding data from an LLM completely broke its reasoning, and getting the proxy from a regex eraser to a context-aware translator took three iterations. This post is the long version of how we got there, and why we are open-sourcing the result.
V1: regex and the “Sarah Kowalski” hallucination
The first version was naive. Regex matched email addresses and replaced them with bracketed tags, so [email protected] became [User_Email_1]. Two problems showed up immediately.
Syntactic hallucinations. Forced to work with bracketed tags, Claude pushed back. LLMs are next-token predictors trained on real code and real data, so a query like where UserPrincipalName == "[User_Email_1]" is a statistical anomaly. To “fix” the syntax, Claude invented a realistic-looking user named sarah.kowalski and started querying for her. We had asked for a triage report and got fan fiction.
Entity fragmentation. The next try used plausible fake names like [email protected]. Claude immediately spotted the email structure and started writing queries against just john.smith. Our proxy was looking for the full email string to translate back, missed the partial match, and the queries returned nothing.
Prompt engineering could have forced the model to comply, but the architectural goal was a transparent proxy. If every tool calling the proxy needs custom prompt rules, the proxy has failed.
V2: NER, structured pseudonyms, and the context void
Two changes: better detection, and replacements that look real.
Detection. A lightweight Named Entity Recognition model (spaCy) running alongside the regex pass. NER picks up natural-language person and organisation names that regex cannot reach.
Replacement. Syntactically valid pseudonyms instead of bracketed tags. [User_1] became [email protected]. Claude accepts that as a real email, stops hallucinating, and writes correct KQL. To handle the fragmentation problem from V1, the proxy now registers both the full email and the bare username when it sees something like [email protected], so a later reference to just rik still gets translated back.
The V2 detection pipeline ran in three passes:
- Regex for emails, IPs, domains, and known-entity patterns from config.
- spaCy NER for person and organisation names.
- Username extraction from the local part of detected emails.
V2 also revealed the next problem. Pseudonymization stripped out the characteristics the LLM needs to reason about a security incident.
- Impossible travel. When a user logs in from the Netherlands and then from Russia, Claude usually flags it. After masking, both IPs become arbitrary placeholders like
198.51.100.1and198.51.100.2. The model has no way to know they sit on different continents. - Typosquatting. A real attacker domain like
miicrosoft.comis a giveaway to a model that has seen a billion domain names. Masked asdomain-external-005.net, the threat signal is gone. - Internal vs external. With every domain rewritten to
domain-external-NNN.net, Claude cannot tell corporate infrastructure apart from attacker infrastructure.
V3: context-preserving pseudonymization
A token proxy for the SOC cannot be a dumb eraser. It has to be a translator: strip the PII, keep the metadata the LLM needs to reason.
ASN-aware IP replacement. The proxy looks up each IP’s ASN and network using the MaxMind GeoLite2 database, then replaces it with a different IP from the same ASN and subnet. A Hetzner IP in Germany becomes a different Hetzner IP in Germany. A Cloudflare IP stays Cloudflare.
Real input: "[email protected] logged in from 95.216.246.66"
LLM sees: "[email protected] logged in from 95.216.201.14"
(different Hetzner IP, same /16 prefix)
Analyst gets: "[email protected] logged in from 95.216.246.66"The model can still run whois, spot impossible travel, and flag suspicious hosting, all without ever seeing the real address.
Internal, partner, and external classification. Entities are categorised in config: internal pseudonyms for corporate domains, partner for known partners, external for the rest. The model now understands that [email protected] talking to domain-external-003.net is an insider talking to an outsider, which is exactly the kind of context triage depends on.
Optional domain pseudonymization. Sometimes the analyst needs to know whether a sender came from outlook.com or protonmail.com. Domain pseudonymization can be turned off independently while emails, IPs and names stay masked.
The false positive battle
Building the detection pipeline was only half the work. The other half was teaching the proxy what not to redact, because the Microsoft ecosystem is full of strings that look like sensitive data but are not.
Graph API permission scopes like Policy.ReadWrite.All look like domain names. Our V1 proxy happily pseudonymized everything with dots and TLDs, so Mail.ReadWrite became domain-external-042.net and the LLM had no idea what API it was calling. Same story for Azure property paths like ConsentContext.IsAdminConsent, KQL table names like SecurityEvent and SigninLogs, and .NET exception class names.
In our first measured session, 82% of the pseudonym mappings were false positives: 65 out of 79 were Graph permissions or dotted property paths.
The fix was layered:
- A dotted-property detector that recognises PascalCase plus verb patterns (covers all 700+ Graph scopes).
- A configurable tech skiplist with 8,000+ KQL table and column names.
- A domain allowlist for things like mitre.org and virustotal.com.
- CamelCase detection that skips code identifiers like
TimeGeneratedandUserPrincipalName.
False positive rate dropped from 82% to near zero.
Streaming: the tail-buffer problem
Server-sent event streaming surprised us. When Claude streams token-by-token, a pseudonym can split across two chunks: domain-inter arrives in one, nal-001.com in the next. A naive find-and-replace misses the split entirely.
The fix is a tail buffer that holds the last 80 characters of each chunk, joins them with the next, runs replacement, and emits only the safe portion. The latency cost is small enough that we cannot measure it reliably, and pseudonyms never slip through unrestored.
A note on residual risk
The token proxy is a safety net, not a guarantee. It catches the common patterns (API keys, credentials, personal data), but no filter is perfect. Novel formats, obfuscated data, and context-dependent secrets can all slip through. If a local model can do the job, a local model is still the safer choice. Hosting a frontier model inside AWS Bedrock or Microsoft Foundry is another option where the proxy adds value as defence in depth rather than as the only line.
Try it yourself
Pseudonymization for cloud LLMs is useful well beyond the SOC use case. Anywhere you want frontier-model reasoning over data you cannot ship to a cloud provider, the same pattern applies.
Clone and run the proxy:
git clone https://github.com/zolderio/token-proxy.git
cd token-proxy
cp config.json.example config.json
# Edit config.json with your internal domains, known entities, etc.
docker build -t llm-token-proxy .
docker run -p 8090:8080 -v ./config.json:/app/config.json llm-token-proxyPoint Claude Code at the proxy:
export ANTHROPIC_BASE_URL=http://localhost:8090/session/my-session/The proxy ships with an empty config. No assumptions about your environment. For security operations specifically, config.json.example includes 8,000+ KQL terms and full Graph API coverage out of the box.
We currently ship an Anthropic Messages API adapter, but the proxy uses a provider adapter pattern: adding OpenAI, Google Gemini, or any other provider is one protocol class. The core pseudonymization engine is provider-agnostic.
GitHub: github.com/zolderio/token-proxy
Open an issue or send a PR if you find a use case we have not thought of.