Healthchecks.io ping endpoints accept HTTP HEAD, GET, and POST request methods. When using HTTP POST, clients can include an arbitrary payload in the request body. Healthchecks.io stores the first 100kB of the request body. If the request body is tiny, Healthchecks.io stores it in the PostgreSQL database. Otherwise, it stores it in S3-compatible object storage. We recently migrated from a managed to a self-hosted object storage. Our S3 API is now served by Versity S3 Gateway and backed by a plain simple Btrfs filesystem.
The Managed Options
In 2022, while implementing ping request body offloading to object storage, I was evaluating which object storage provider to use.
AWS S3 has per-request pricing, which would make it expensive-ish for Healthchecks.io usage patterns (frequent PutObject S3 operations, one operation per every large-enough ping request). Also, AWS being subject to the CLOUD Act, Healthchecks.io would need to encrypt data before handing it off to AWS, which would add complexity.
OVHcloud is what I picked initially. There are no per-request fees, OVHcloud is an EU company, and the performance seemed good. Unfortunately, over time, I saw an increasing amount of performance and reliability issues. As my experience got worse and worse, I looked for alternatives.
In 2024, I migrated to UpCloud. Same as OVHcloud, it has no per-request fees and is an EU company. There was a clear improvement in the quality of service: the S3 operations were quicker, and there were fewer server errors or timeouts. Unfortunately, over time, the performance of UpCloud object storage deteriorated as well. There were periods where all operations would become slow and hit our timeout limits. The S3 DeleteObjects operations in particular were getting slower and slower over time. So I looked for alternatives again, including self-hosted.
Requirements
Our current (April 2026) object usage is:
- 14 million objects, 119GB
- Object sizes range from 100 bytes to 100’000 bytes. The average object size is 8KB.
- 30 upload operations per second on average, with regular spikes to 150 uploads/second.
- Constant churn of uploaded/deleted objects.
Our candidate object storage system would need to be able to support this usage and have room to grow. Luckily, we are still at the scale where everything can easily fit on a single system, and operations like taking a full backup can be reasonably quick. Everything would be more complicated if we had many-terabyte requirements.
Availability and durability: for the Healthchecks.io use cases, the object storage is not as mission-critical as our primary data store, the PostgreSQL database. If the database goes down, the service is completely broken, and monitoring alerts stop going out. If the object storage goes down, then users cannot inspect ping bodies through the web interface or through the API, but the system otherwise still functions. If some ping bodies get permanently lost, that is bad, but not as bad as losing any data going into the PostgreSQL database.
Latency: the quicker, the better. There are places in code where Healthchecks.io does S3 operations during the HTTP request/response cycle. Individual S3 operations taking multiple seconds could choke the web server processes. While using UpCloud, I had to add some load-shedding logic to prevent slow S3 operations from escalating into bigger issues.
The Self-Hosted Options
I ran local experiments with Minio, SeaweedFS, and Garage. My primary objection to all of them was the operational complexity. It is not too hard to follow the “get started” instructions and get a basic cluster up and running. But, for a production-ready setup, I would need, as a minimum:
- automate the setup of the cluster nodes,
- learn and test the update procedure,
- learn and test the procedure of replacing a failed cluster node,
- set up monitoring and alerting for cluster-specific health issues.
Since I’m a one-person team, and I already run self-hosted Postgres, self-hosted HAProxy load balancers, and self-hosted email, I would really like to avoid taking up the responsibility of running another non-trivial system. Something simple would be much preferred.
Versity S3 Gateway
Versity S3 Gateway turns your local filesystem into an S3 server. An S3 PutObject operation creates a regular file on the filesystem, an S3 GetObject operation reads a regular file from the filesystem, and an S3 DeleteObject operation deletes a file from the filesystem. It does not need a separate database for metadata storage. You can use any backup tool to take backups. The upgrade procedure is: replace a single binary and restart a systemd service. It is written in Go, and is being actively developed. The one bug I found and reported was fixed in just a few days.
The big obvious caveat with Versity S3 Gateway and the filesystem as the backing store is, of course, availability and durability. The objects live on a single system, which can fail at any point of time without any prior warning. I need to be ready for this scenario.
The Setup
In March 2026, I migrated to self-hosted object storage powered by Versity S3 Gateway.
- S3 API runs on a dedicated server. It listens on a private IP address. Application servers talk to it over Wireguard tunnels.
- Objects are stored on the server’s local drives (two NVMe drives in RAID 1 configuration).
- Objects are stored on a Btrfs filesystem. With Btrfs, unlike ext4, there is no risk of running out of inodes when storing lots of tiny files.
- Every two hours, a rsync process synchronizes the added and deleted files to a backup server.
- Every day, the backup server takes a full backup, encrypts it, and stores it off-site. We keep full daily backups for the last 30 days.
With this setup, if both drives on the object storage server fail at the same time, the system could lose up to 2 hours of not yet backed-up ping request bodies. This can be improved, as usual, with the cost of extra complexity.
The Results
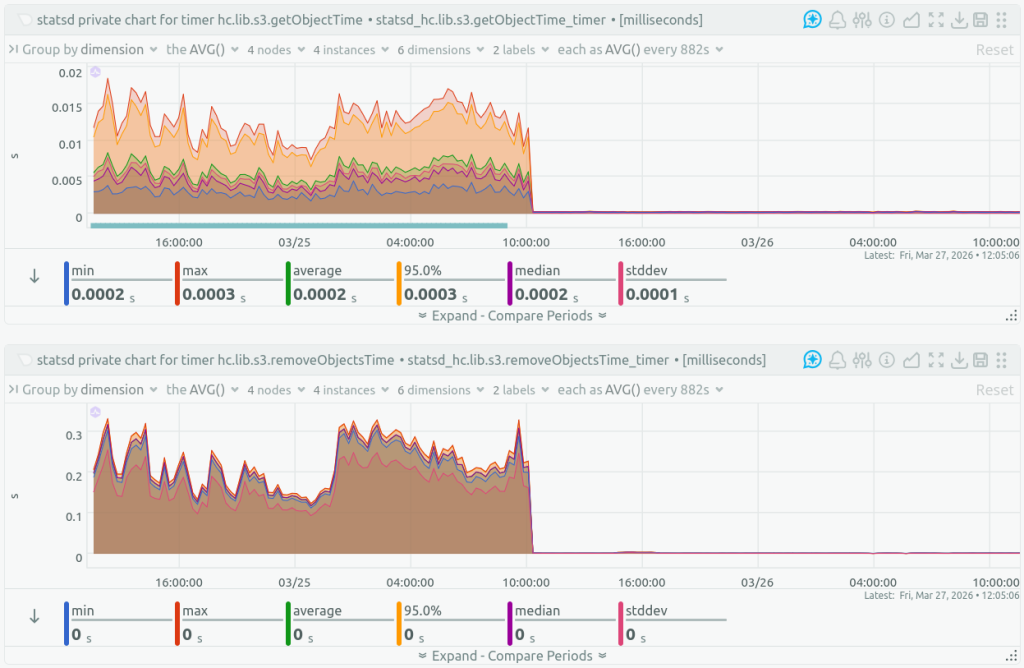
After switching to self-hosted object storage, the S3 operation latencies dropped:

The queue of ping bodies waiting to be uploaded to object storage shrank:

There have been no availability issues yet, but the new system has been live for only a couple of weeks.
The list of our data sub-processors now has one less entry.
The costs have increased: renting an additional dedicated server costs more than storing ~100GB at a managed object storage service. But the improved performance and reliability are worth it.
I am cautiously optimistic about the new system, and I think it is an improvement over the old one. But I am also open to migrating again if I find a system with better tradeoffs.
Thanks for reading, and happy monitoring,
–Pēteris