I’m sorry. This is a rant. Which you’ve probably guessed by the title, duh!
The straw that broke my back was the lead I saw:
“Sweden built smart machines where crows trade trash for food, turning clever birds into unexpected city cleaners.”

A clearly AI-generated image didn’t help the credibility (a three-legged crow is quite telling), yet it’s the headline that made me do the search. “Search” is such a big word, though. It was literally one query.
Not Sweden, but one Swedish startup. Not built, but run a one-time pilot. And it didn’t get anywhere close to turning crows into city cleaners as the project was abandoned with zero follow-up. Fact check here.
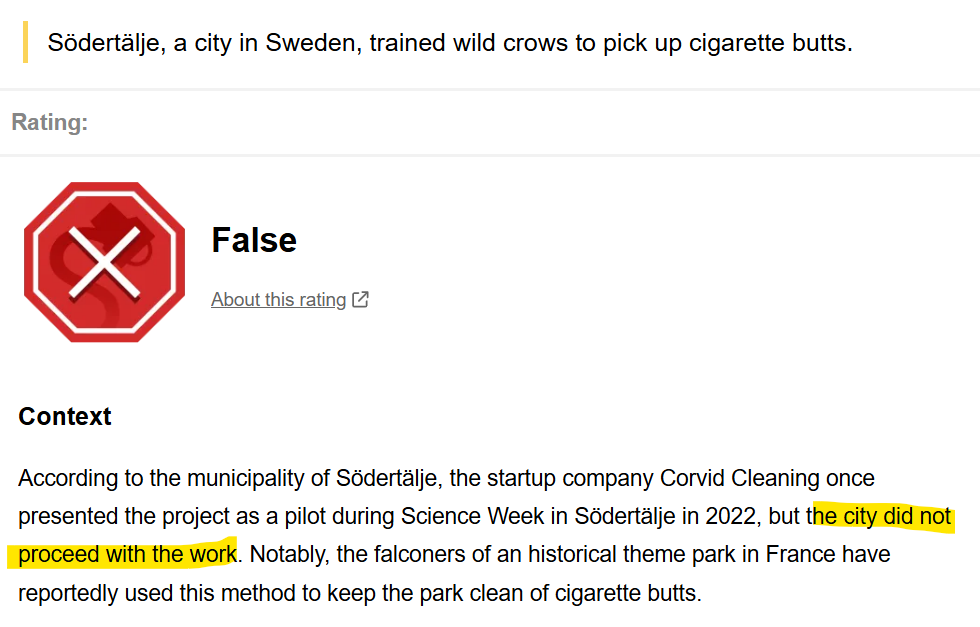
Yet it sure works as eye candy if you want to glue someone’s attention to your clearly AI-generated LinkedIn post that tries to sell something (I don’t know what exactly; I’m incentivized to stop reading once I see an AI-generated graphic).
Links No Longer Mean Credibility
Crow cleaners’ story, as amusing as it might have been, wouldn’t get me to write a post, though. In fact, fake references have been a pet peeve for quite some time already, so it was just “another one of these.”
Here’s a more interesting case. Recently, I read a story about AI in coding, full of data backing the author’s claims. One particular fact was the following:
“The SmartBear/Cisco study established numbers everyone ignores: defect detection drops from 87% for PRs under 100 lines to 28% for PRs over 1,000 lines.”
Cool. That’s something I’m researching right now. Let’s take a look at the study and see what I can learn from the data. Ops, the link doesn’t lead to the study, but to another article. But that article, in turn, has a link of its own. Which leads to yet another article that doesn’t even mention the study anymore.
By the way, neither of the websites in the link chain mentioned the numbers from the original quote. I bet they were AI-generated with no human validation whatsoever.
Even a mildly competent human would spot the inconsistency. And the author clearly aspires to a higher expertise league than just “mildly competent.”
Source Data Is the Usual Suspect for Hallucination
Now, the SmartBear/Cisco study is easily googlable, so ultimately the link chain was a minor nuisance. Reading the paper was, however, an enlightening experience.
There isn’t a single place in the research where it claims 87% or 28% detection rates for specific pull request sizes. Across the entire data sample, there are scarcely any data points with a PR size over 1,000 lines of code. Finally, the paper does not explicitly measure defect detection as an analyzed parameter (it uses defect density and draws some conclusions about detection rates).
In other words, the whole claim in the original article must have been hallucinated.
In the author’s defense, the SmartBear/Cisco study infers that longer PRs may lead to worse defect detection. But it makes the claim neither explicitly nor directly.
“Inspection rates less than 300 LOC/hour result in best defect detection. Rates under 500 are still good; expect to miss significant percentage of defects if faster than that.”
The angle is the number of lines reviewed per hour, not the PR size. The inference is that larger PRs take longer, and there was an observable tendency for reviewers to speed up the process when it takes more time. The pace of the review, in turn, is inversely correlated with the defect density.
That’s pretty far from “defect detection drops from 87% to 28%.”
AI Fails at the Fringes
That’s a perfect example of AI unreliability at the fringes. There isn’t a particularly huge data sample of “SmartBear/Cisco studies” or research showing specific code review dynamics. For an LLM, this already means the fringes.
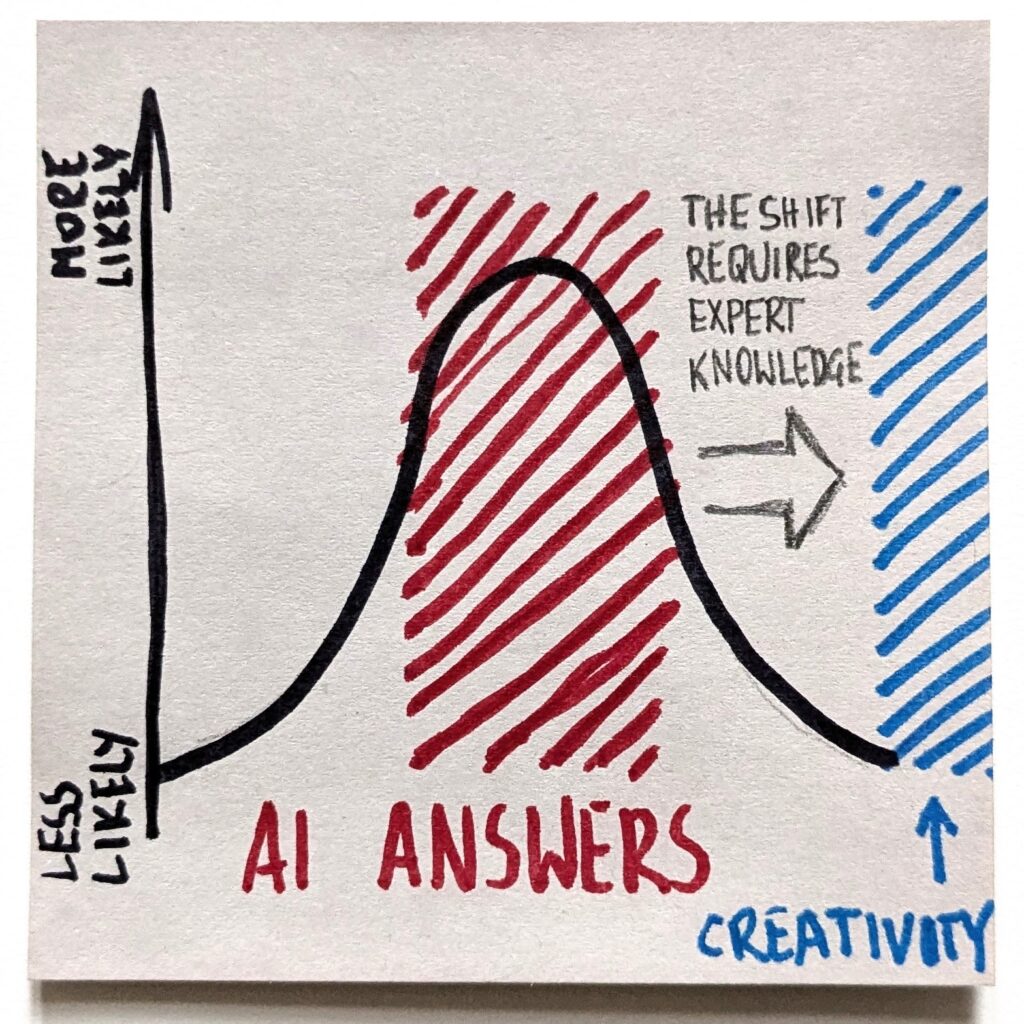
If we run AI on autopilot, it will certainly deliver a result. In a likely case, when an LLM doesn’t find a relevant answer, it will hallucinate something. It will gladly make up the numbers. They will look fine. Specific. Sound. With a bit of luck, they may even be (somewhat) in line with what the source actually said. But will it actually be what the study reported?
As we all know, “73.6% of all statistics are made up.“ I recommend adding: “Since wide AI adoption, that percentage went up to 86.9%.”
Sadly, the more we outsource the data research to AI, the more spot-on my irony might be. And it will only get worse. The original piece with made-up numbers will soon be used by another LLM as a credible article. After all, it looks like one. The length of the link chain will go up by one, adding even more self-reinforcing noise to future AI queries. Good f**cking job, everyone!
Credibility Is Our Currency
OK, I know. I won’t turn the tide. AI slop is there to stay. Algorithms reward it. Writing a piece takes me around a couple of hours. More if I need to research background facts. Add some time for post-editing.
ChatGPT could have done that for me in minutes. While I’m sipping coffee and enjoying the sun. With plenty of outgoing links and a shitton of reference data. No sweat. And the result? Save for some personal vibe, it may look just as good as mine.
The only price to pay would be my credibility. The data pulled by an LLM might be misinterpreted (if I’m lucky) or entirely fake (if I’m not). The reference links would lead to whichever posts rank best at Generative Engine Optimization (which is SEO A.D. 2026). These pages, coincidentally, tend to be awful to read for a human. The end result would be something I wouldn’t consciously sign my name to.
I’d basically be my cheap, anonymous version of Elon Musk, passing a seemingly hilarious (also fake) joke about a major AWS outage.

I’d be trading my trustworthiness and credibility. The exact tools that are critical to navigate professional relationships in the AI era.
Check Your Sources, People!
With a shrinking attention span, we don’t want to spend time reading the actual research paper to back up our brainfart claim. I get it. I go through the pain myself.
5 years ago, we needed to be pretty precise with our Google-Fu to find a fitting research paper to back [insert any statement here]. Now? Explain that in plain English to ChatGPT or Gemini, and voila! Here’s a freshly baked link for you.
It’s probably shit, but how would you know? That is, unless you do your f**cking homework and read the thing for yourself. And then apply at least a minimum judgment.
I mean, as writers, we necessarily are readers, too. Making the data up is like shitting on your own doorstep. Why would you believe any stuff you read if you get AI to make the shit up in your “writing” unattended? Ultimately, why would you expect anyone to care more than you do?
So, be so kind and do check your f**cking sources, people!
I actually read the sources I link here. Including the SmartBear/Cisco study. I know, weird, right?
웃 https://okhuman.com/M0eKWQ
Thank you for reading. I appreciate if you sign-up for getting new articles to your email.
I also publish on Pre-Pre-Seed substack, where I focus more narrowly on anything related to early-stage product development.