Essay
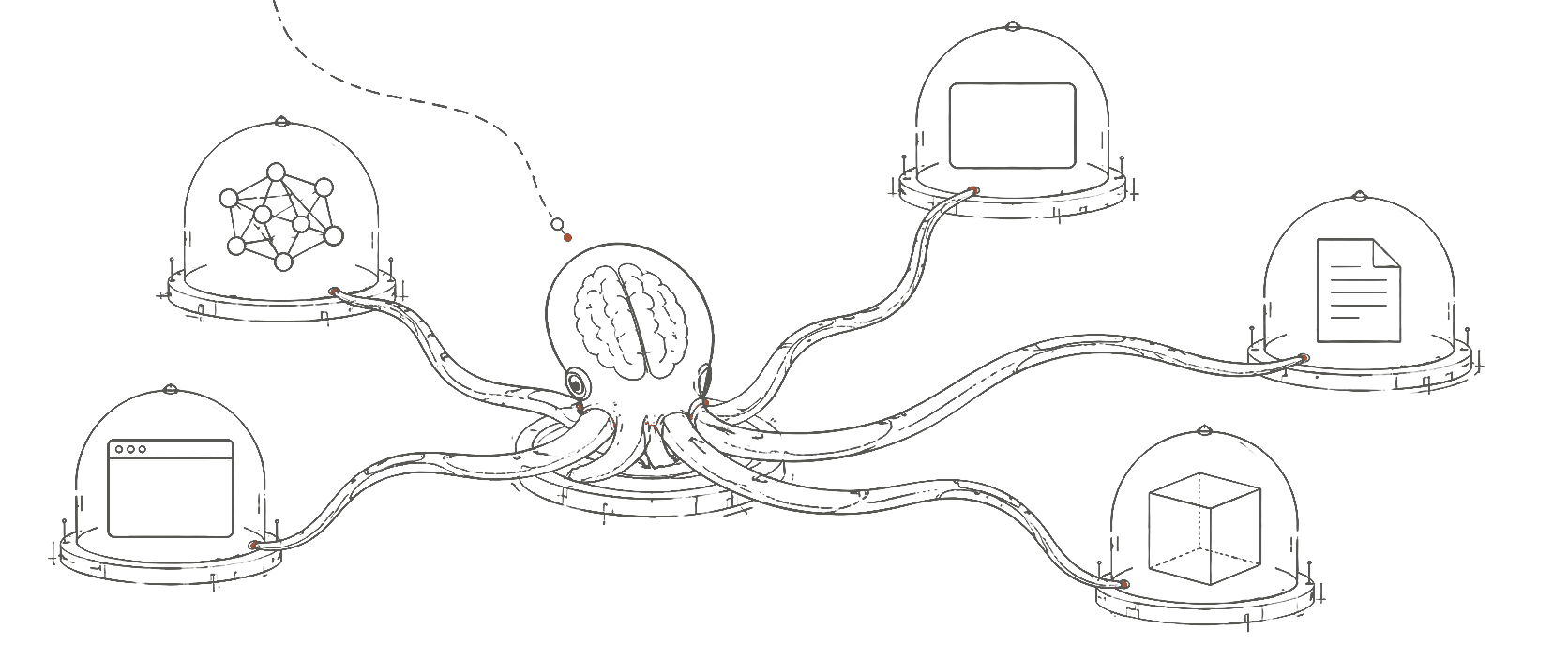
The octopus architecture describes a system with a central coordinating brain that dispatches to semi-autonomous sub-brains.

TorkBot is designed a bit like an octopus. This architecture was born from a series of dead-ends and iterative improvement. When I say octopus, what I mean is that TorkBot has a centralized “brain” directing many semi-autonomous appendages, each with their own brains, reporting back to the central dispatcher.

Static lanes are the long-lived appendages. Curator is one. Plugins can contribute others, like the Google Workspace lane. Lane templates are different. A template is a capability that can be instantiated for a bounded purpose. A sandbox snapshot is different again: it is not a collaborator at all, just a saved filesystem starting point for a future sandbox-backed lane.
Interaction vs capability
Several competing pressures are at play that pushed me into this architecture.
- Responsiveness to surface interactions — The agent requires a design in which its turns are more or less bounded in complexity and can avoid I/O entirely. This allows the agent to interact quickly even when tasks or work may take quite some time.
- Capability — The agent shouldn’t be limited in what it can accomplish just to keep turns efficient. It needs mechanisms to pursue complex tasks through delegation and be able to observe and steer those tasks close to real-time.
- Continuity — The agent should maintain a continuous perspective and personality. The best continuity comes from a single LLM conversation that is continually curated. In this way, the personality and short-term memory don’t need to be “added in”; instead they’re a side effect of the architecture.
These pressures pushed me into a design with multiple “lanes”, as you can see in the diagram above. The “foreground” lane is the LLM conversation users interact with through surface activity. But here, I have made a bet that is likely controversial: all activity across all surfaces goes through the same foreground conversation. Threads, channels, and even platforms are all collapsed. Right now, that cognitive complexity is perhaps beyond the ability of most models and perhaps even beyond the frontier. But I’m certain that will not be the case for long.
All activity across all surfaces goes through the same foreground conversation.
Part of my thesis with TorkBot is to bet on emergent behaviour and emergent intelligence. Coming up with systems that split LLM conversations across arbitrary platform-defined boundaries is antithetical to the continuity goal. I want my agent to make links across threads and even across surfaces. I want the agent to be able to trivially continue work started in Slack and continued on GitHub. If we’re not there yet in model intelligence, I bet we will soon be and the agentic system designed for that world will stand above the competition in terms of intuitiveness and power.
How the octopus works
The octopus idea is doing actual work here. It is the shape of the harness problem.
This is not jumping on the sub-agent bandwagon for the sake of clout. This is a design that emerged and earned its existence. After all, it comes back to context management. Each appendage gets its own context.
The foreground hands off work to other lanes by ‘talking’ to them. Inter-lane communication is just text, betting on the idea that pre- and post-training skew heavily towards prose as the carrier of intent. The foreground picks a lane template — and if it is a sandbox lane, a VM snapshot — and passes an initial message to that lane about what it wants. For lanes that are already spawned, a simple message is sent.
Lanes can own the messy work of doing a bunch of tool calls, hitting dead-ends, doing I/O and any number of more complex sandbox-enabled workflows. That mess stays contained in the lane’s context. Lanes communicate between each other via two mechanisms:
- Chat, as described above; and
- References to virtual filesystem artifacts via the lane’s
./sharedfolder.
The foreground conversation can stay continuous across surfaces, which is what I want for personality and cross-thread intuition, without becoming the place where every intermediate artifact goes to die. The appendage can carry the local working memory for the task. The foreground can carry the relationship, the current intent, and the synthesis.
This also makes compaction pretty obvious. Each lane is continuously compacted asynchronously at a certain threshold and synchronously if, through some strange turn of events, it exceeds another higher threshold.
Benefits that fall out of this design
Mean-time-to-interaction is the prize.
Completion can take a while. It is okay for a lane to read docs, wait on I/O, run tests, hit a wall and try again. It is not okay for the foreground to go dark because one appendage is busy.
So the foreground lane has to stay small and boring: stable prompt, current intent, recent surface activity, compact summaries and references to evidence. Keep the churn in the appendages. That is both a context-efficiency story and a cache-efficiency story. A stable foreground prompt means better LLM API cache hits. Less junk means faster first tokens and less cognitive drag.
Curation makes that possible. Compaction keeps lane context from swelling forever. Curator can promote durable bits into memory or skills. Artifacts can stay artifacts. Transcripts can remain inspectable without being stuffed back into the foreground.
The arms can be busy. The head needs to stay available.