Humanizers are a class of adversarial tools designed to modify AI-generated text in a manner that evades AI detectors. To see where humanized text sits relative to human and AI text in activation space, we created a separate humanizers dataset, which consists of roughly 1,900 samples, roughly balanced across three generative models (Claude Sonnet 4.5, Gemini 2.5 Pro, and GPT-5), ten different humanizer services, and the same source domains as the original interpretability dataset. Because of the adversarial risks, we do not disclose which services we use.
How the Model Reads Out Humanizers
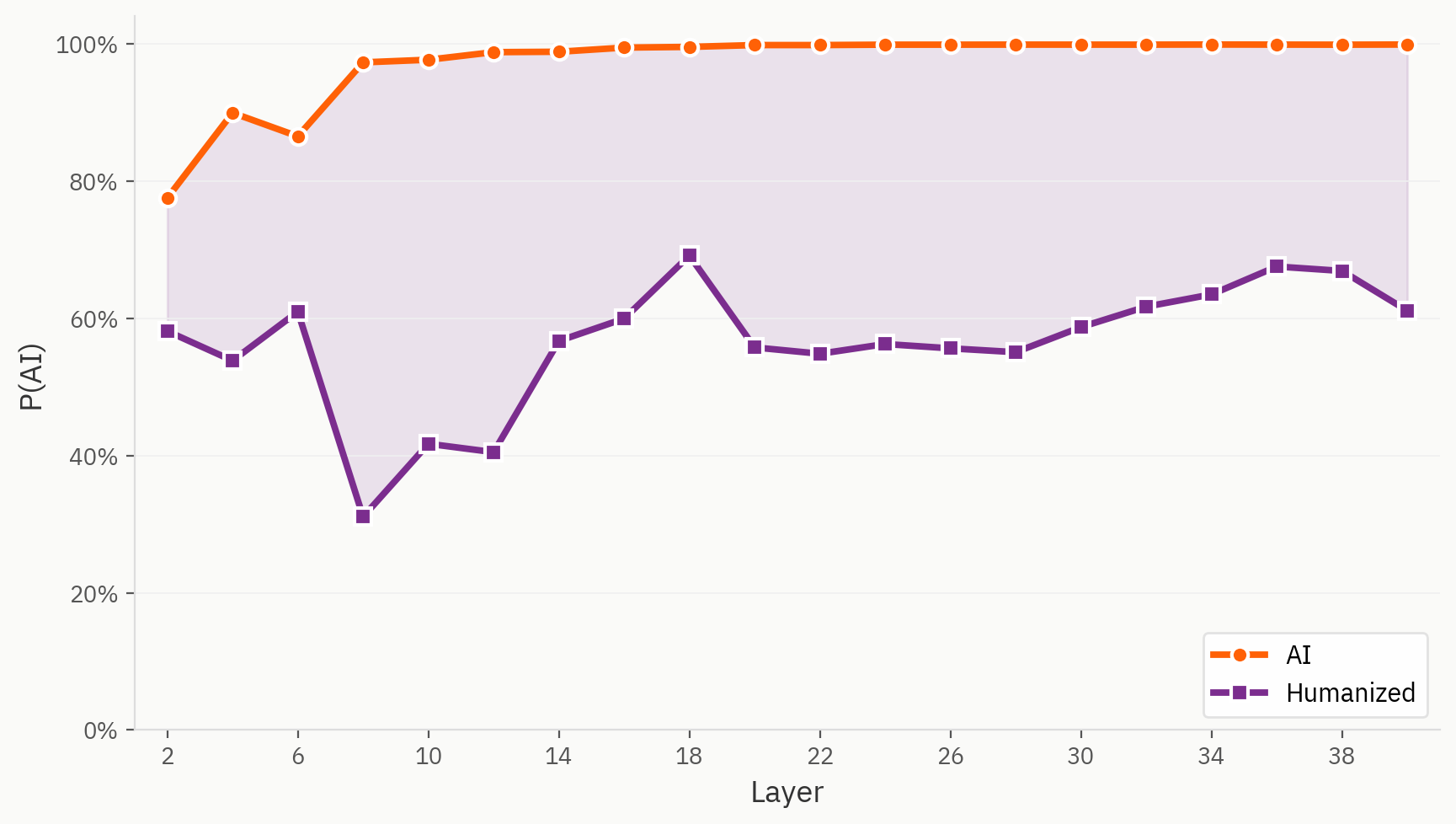
Certain samples from our humanizer dataset are indeed challenging for our model to detect. Here, we use the same linear probe for the human/AI task, except with humanized text labelled as AI, as we do in the original training setup. We see that even from the first layer, humanized text is consistently read out as more human than its direct AI counterpart.
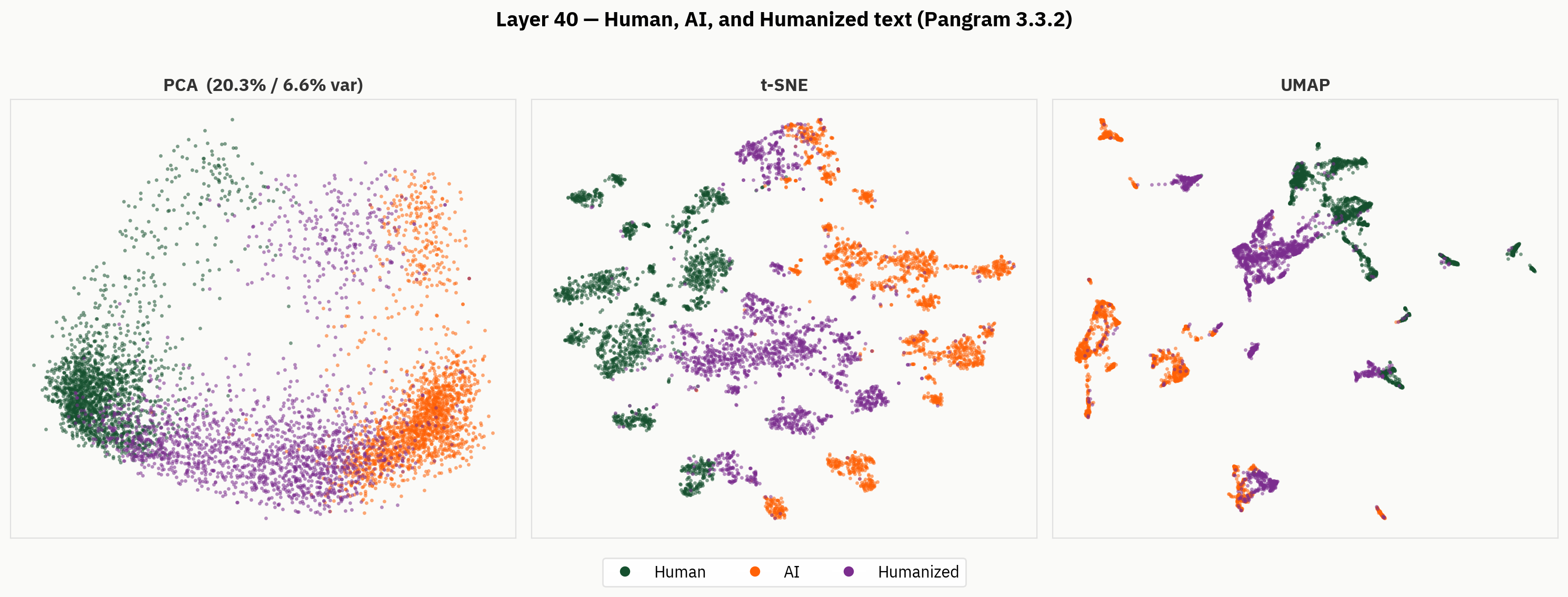
Where Humanizers Exist in Embedding Space
However, when we look beneath the final readout, we find a much richer representation of humanized text. Below, we apply our dimensionality reduction methods to the human, AI, and humanized texts. Qualitatively, we can observe that humanizers tend to occupy separate parts of activation space, and form clusters outside of the human and AI regions.
Our hypothesis is that despite not having labels for humanized text, the model is capable of distinguishing between humanized, human, and AI text. However, in the final readout, the model is forced to collapse that signal and does so inconsistently.
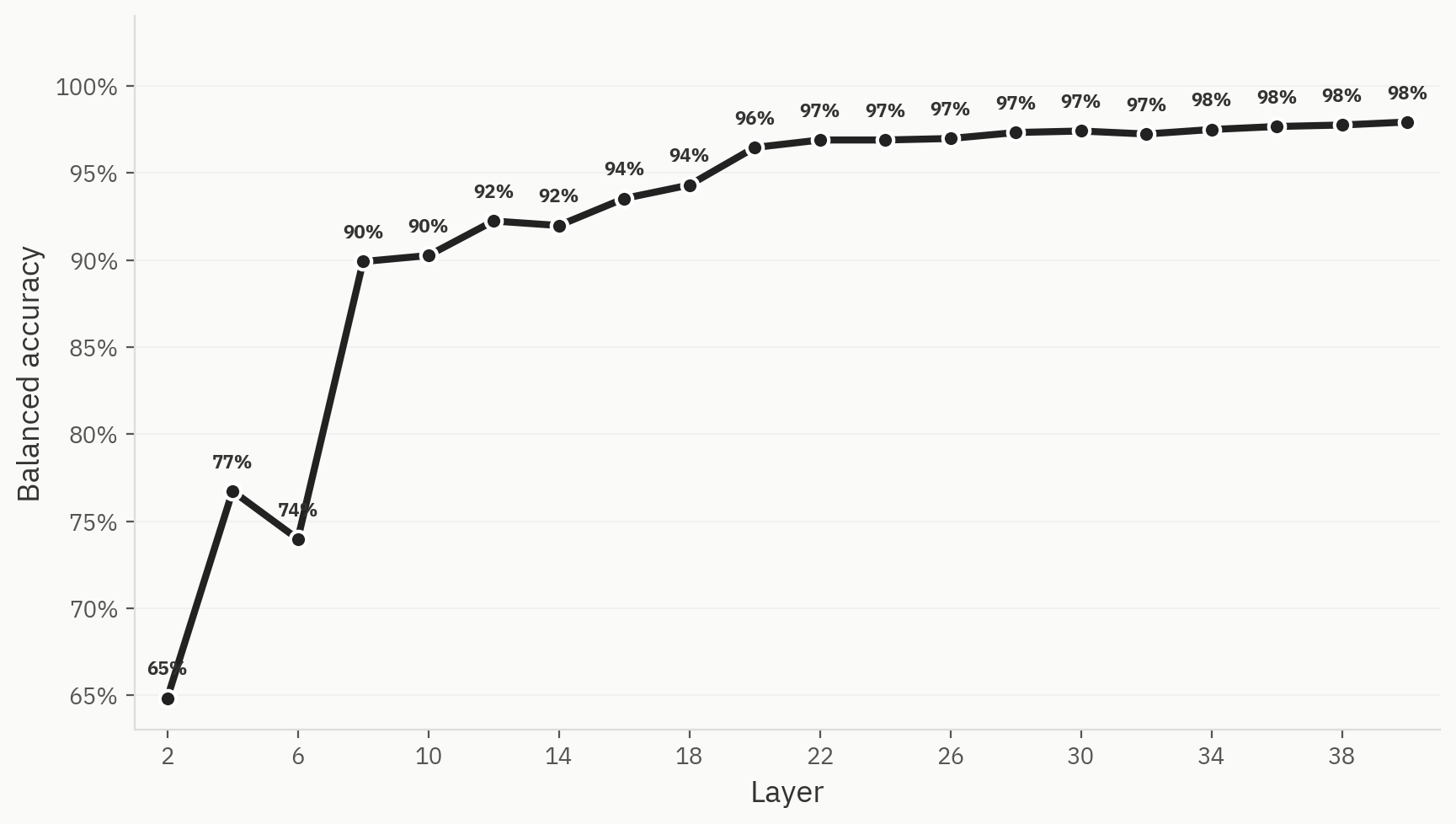
Probe
To validate this hypothesis, we train a three-way linear probe with labels for AI, human, and humanized text. The probe reaches high top-1 accuracy early in the network and eventually flattens out at 98%.