
This article is about my experience using Opus 4.8 to read the results of an MRI and give me a sort of second opinion on the diagnosis. Of course, I know the technology might not be there yet, which is why I'm sharing this article. Maybe it can help someone or at least provide a bit of information or entertainment.
Disclaimer: I'm of course not a doctor (this is actually the problem!) so please take everything I say with a grain of salt.
Some context (feel free to skip)
For a few weeks now, I've been experiencing some pain in my right shoulder. Even though it seemed to be getting better, I decided to get an opinion from an orthopedist. I won't go into the details, but he suggested I get an MRI, which the clinic conveniently had available. I agreed and mainly learned that I had a "Grade III (>50%-width) partial-thickness tear at the apical insertion" of my subscapularis tendon. This, of course, means little to me, but their suggested course of treatment was extensive; they even started a few minutes after I got the MRI. Coming out of the clinic, I had the feeling they had jumped the gun.
Thankfully, before I left, I asked them to send me a copy of the MRI results and a list of all the treatments they performed and suggested we repeat a total of 3 times.
I sent everything over to GPT 5.5 Pro, and right away it flagged two things:
- They performed shockwave therapy on my shoulder even though a recent clinical practice guideline says clinicians should not use or recommend shockwave therapy for rotator-cuff tendinopathy without calcification; I was told during ultrasound that there was no calcification.
- They injected me with Traumeel, which is registered in Germany as a homeopathic medicine "without a therapeutic indication".
That did not increase my confidence. So it made me curious to analyze the MRI.
Setting up Opus to do a first review of the MRI
The MRI package was a standard DICOM export containing a few hundred files without extensions, totaling around 266 MB.
For the analysis, I decided to use Opus 4.8 (xhigh) within Claude Code to give it the ability to run code and install packages. Before any work was done, I told it to install any packages that it might need for the analysis. Using Claude Code is especially important to enable it to perform significant amounts of work on this matter. It might seem obvious to coders, but the difference between Claude Code and Claude.ai's chat is enormous, even if those two run the same model.
It was then time to get started. Considering I know nothing about MRIs, I set things up to have Claude work hard on a detailed plan and then take action. The only instruction I gave was "right shoulder pain for 2–3 weeks," which I later realized was less than the human doctors received.

After around an hour, it came back with the report:
The critical problem with that report was that where the doctor saw a Grade III (greater-than-50%) partial-thickness tear at the apical insertion, Opus 4.8 reported an intact tendon!
This was quite disconcerting. I expected the grade to be lower, but that finding was extreme.
Arbitrating the two analyses
To adjudicate, I decided to have Claude do a comparison of the two reports. But this time, I gave it a bit more context; on top of giving the human report, I also provided it with a discussion I had with ChatGPT 5.5 Pro, where I had it give me movements and positions to try as a way of figuring out what my diagnosis was.

From the planning document, here is the approach Opus took:
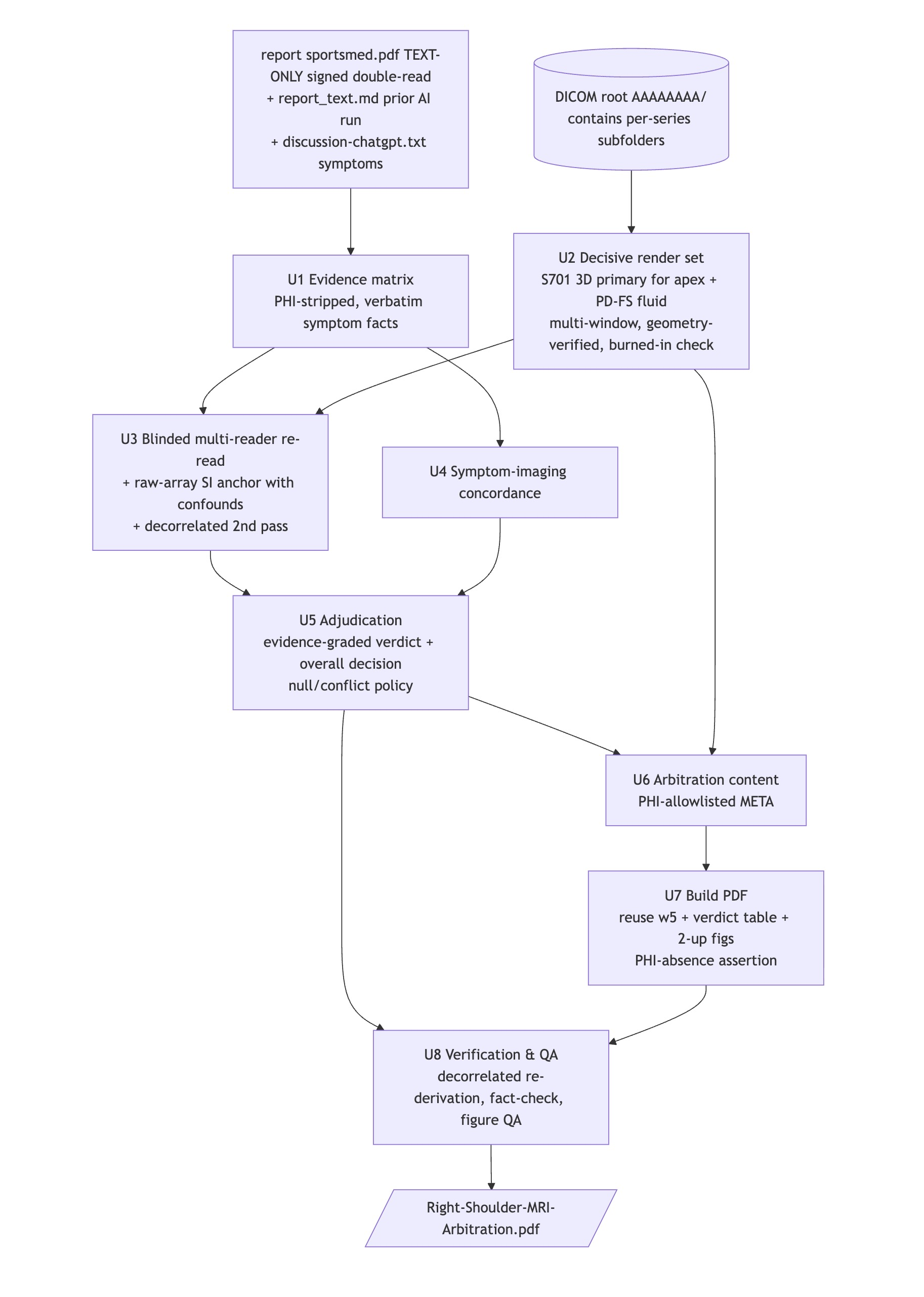
The approach was careful and methodical, with multiple subagents used as a way of getting new analyses that weren't biased by the existing context.
Again, after around an hour, I got a new report:
Its conclusion was:
Arbiter's verdict: Evidence favours Reader A (moderate-to-high confidence). Mild insertional tendinosis; NO discrete partial- or full-thickness tear identified, including at the apical insertion.
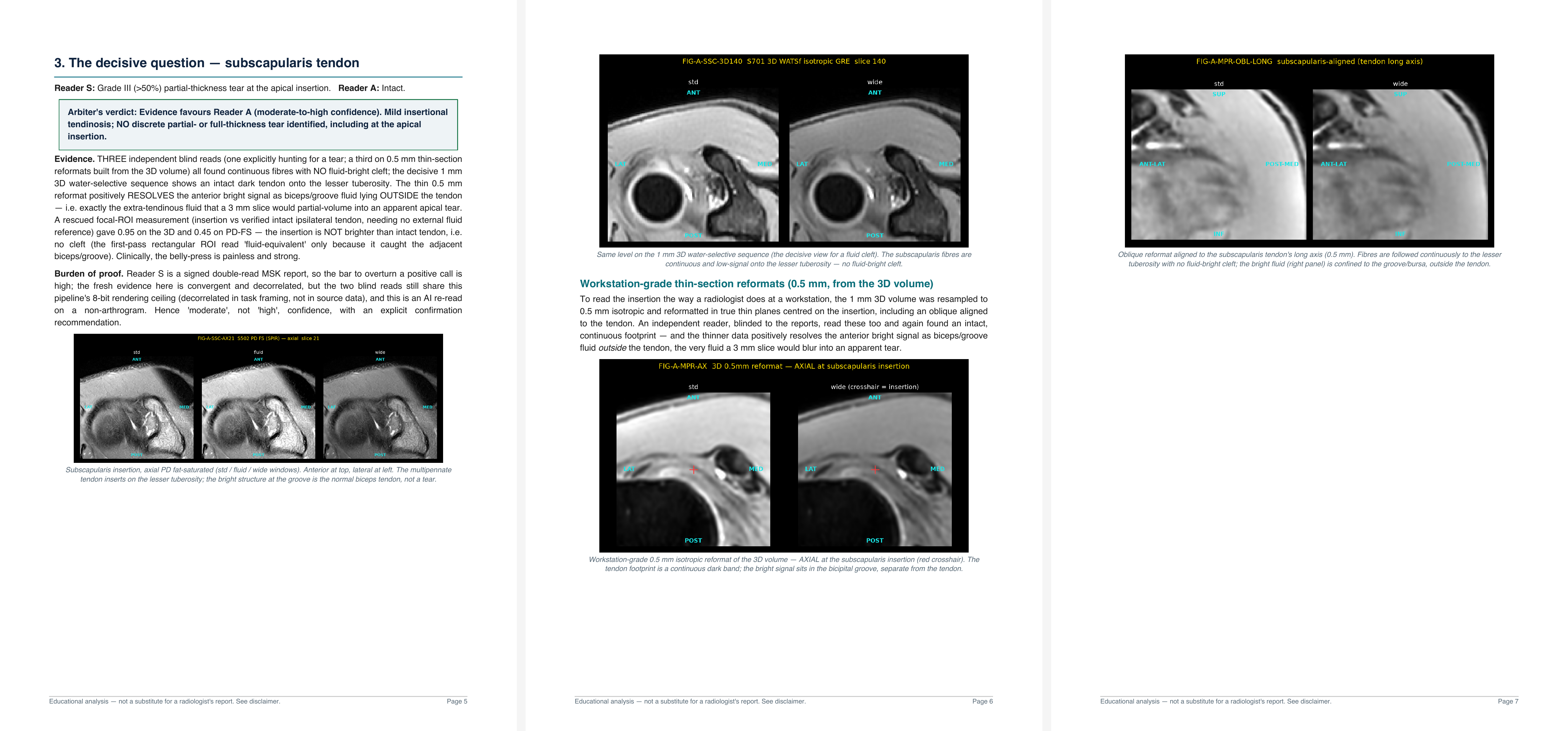
I can't help but find it fascinating that the verdicts are so far from each other. Looking further into the report, I can read that Opus wasn't afraid to say that there are some disputes between the two reports that it can't resolve, and yet this one it could; and very decisively.
Where does that leave me?
There's something incredibly peaceful about being in the hands of an expert you trust. You don't have to worry anymore and can let them guide you through the process.
AI can absolutely shatter that feeling in an uncomfortable way: After having gotten this AI-driven second opinion, the diagnosis and treatment plan look premature and more intervention-heavy than the facts seemed to justify... but I don't know if I can fully trust AI either. So I'm left in a state of limbo where I either try my luck with another doctor or wait and see if my shoulder gets better with the rehab I'm doing.
My hope is that in a couple of model generations, we'll trust AI to review MRIs the way we trust it to proofread our emails.
I am not naming the clinic or doctor because this isn't the point of the article. It's about sharing my technical curiosity about using AI to get second opinions. I may be wrong, or the AI might be wrong. I could also have misunderstood the doctors. So basically, none of this should be taken as medical advice :)