Background
Playtesting is one of the most important processes in game development. It helps with finding bugs, evaluating the game's UX, balancing the game, and, most importantly, assessing how fun it is. This is where a developer determines whether a game idea is good and discovers flaws to fix in their game. It is an iterative process that needs to be ongoing throughout the project, but it can be very time-consuming, and there are no reliable tools that automate some of this process.
PEAK aims to help with that problem, but by no means does it aim to replace playtesters. The idea behind the project is to develop a game engine with integrated deep reinforcement learning (DRL) agents that a designer can dispatch to test their game at any point.
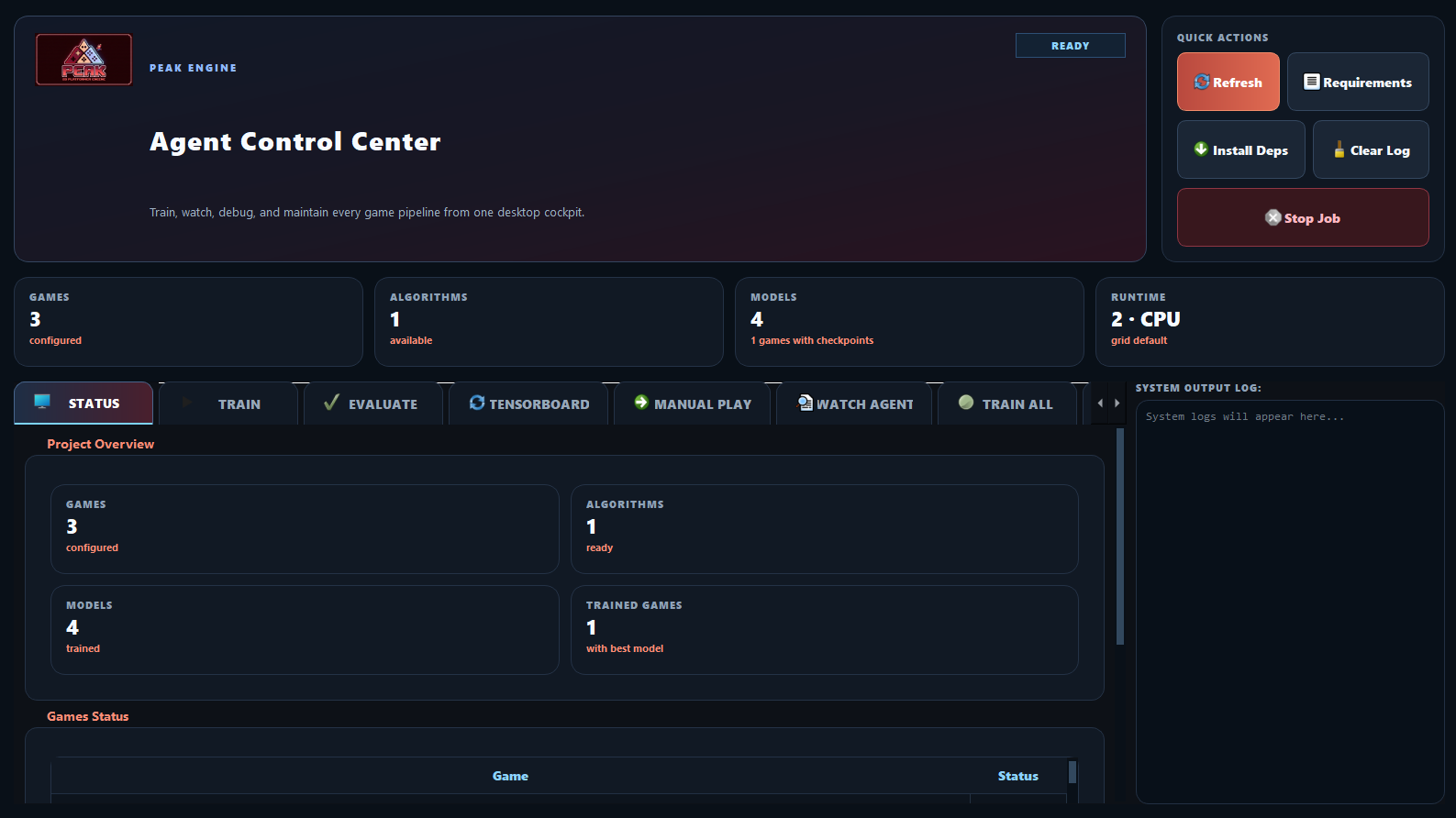
The workflow of a designer using PEAK would be:
- Design a new level using the level editor within PEAK.
- Train DRL agents on that level, choosing the agent playstyle you want to test with.
- The agent would gather data, and based on your defined thresholds, it would tell you how balanced the level is and point out if there are issues within it, such as a difficulty spike on one of the platforms.
PEAK is developed by Cristiano Politowski, Al Shifan, and Kevin Chua at Ontario Tech University. I only joined this project at a later stage. It currently only handles 2D platformer games, maybe even Metroidvanias, since they share many similarities. That scope can be expanded later on, but for now, 2D platformers are used as a proof of concept.
The Problem
My focus on this project is on data collection, aggregation, and visualization for the user. Basically, I am responsible for the step where an agent collects data while playing and uses that data to tell whether a game is balanced or not (just as an example).
Sounds easy, right? If the number of jumps is part of the criteria, I can just add a tracked_jumps variable and add processing to it in the jump method in the module that has it, right?
Well, some requirements and issues make it not so simple:
1- This is not a mature project yet. In the first few months I worked on it, it went through 2 major refactors.
2- This is an engine that supports multiple games with no architecture that ties them together, so the way I collect data should be independent of any game. Otherwise, we will end up with a lot of repeated code.
3- Adding new data to track and process should involve minimal changes to the codebase. Otherwise, there will be no separation between core game code and data collection code.
Adding variables directly violates all requirements! To solve that, I use the Observer Pattern and Aspect-Oriented Programming.
But What is Aspect-Oriented Programming?
Before this project, I knew about Object Oriented Programming, and a little bit of Data Oriented as well as Functional Programming, but I did not know what an aspect even is, and how to orient programming to it.
Don't worry, I did not know I was using AOP while I was using it! I only knew later when the professor pointed it out in a meeting. An aspect is the functionality we want to add to the code, but cannot directly add to it; otherwise, we tangle multiple responsibilities in the same module. So for this specific project, the data I want to collect and process are the aspects. In AOP, we specify the parts of the project we want to add our aspects to. This specification is called a pointcut, and the points of the code where aspects can be applied are called join points. A developer would only be concerned with what to run, when to run it, and how to specify the join points in AOP.
The textbook example for using AOP is loggers. You don't want those into your core files; you either violate the single responsibility principle or end up with high coupling.
Using Decorators
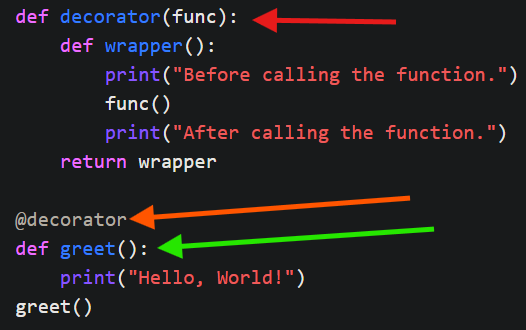
Python 2.4 introduced this really cool feature where you can define wrappers for a method that can be applied by just annotating the target method(s).
The image below shows an example of a decorator. Here, the green arrow points to the original function, the red arrow points to the decorator, and the orange arrow points to the annotation. With this simple definition, we can define what to do before and after the function call by just annotating it.
The way I used decorators is as follows:
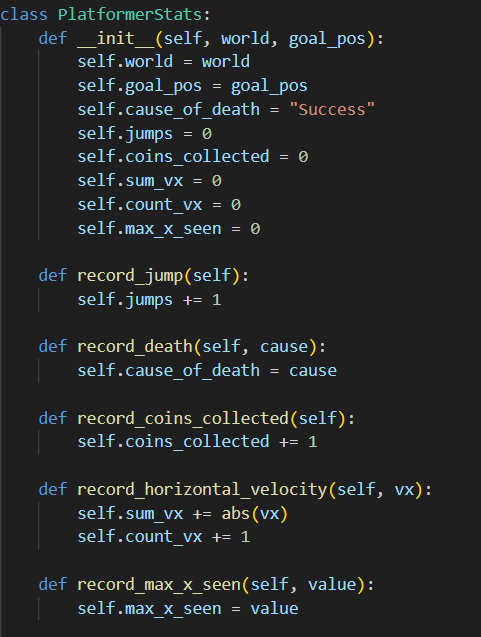
1- I created a class called stats_observer that holds the variables of the data of interest, with a record method for each variable to determine how we are recording them (is it a simple increment or do we need to do other checks?).
2- I defined a generic track decorator that takes the record method name as a parameter, and through reflection calls that method after the annotated method call.
3- With that, all you have to do is define record_something in stats_observer, and add @track("something") to the methods that should track that something.
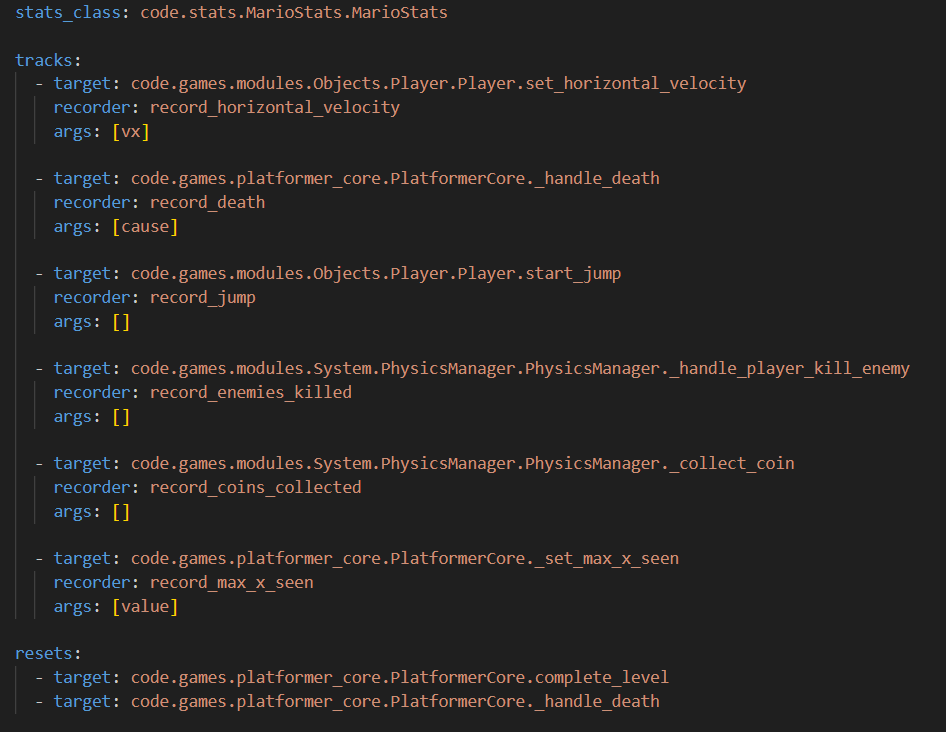
A sample of how I record data is given in the image below:
Using Config Files
Decorators are nice and all, but they still require editing the core game files. I can't have that. Instead, I decided to use YAML files to inject the recorder methods into the game methods of interest through reflection.
Let’s say you want to track how many jumps an agent performed. All you will need to do is set the target in the YAML file to the start_jump method, the recorder as the record_jump method, and that’s it, you have an observer on the jump method set up. This is a sample of how the YAML looks: the challenge is just to find the methods you want to record:
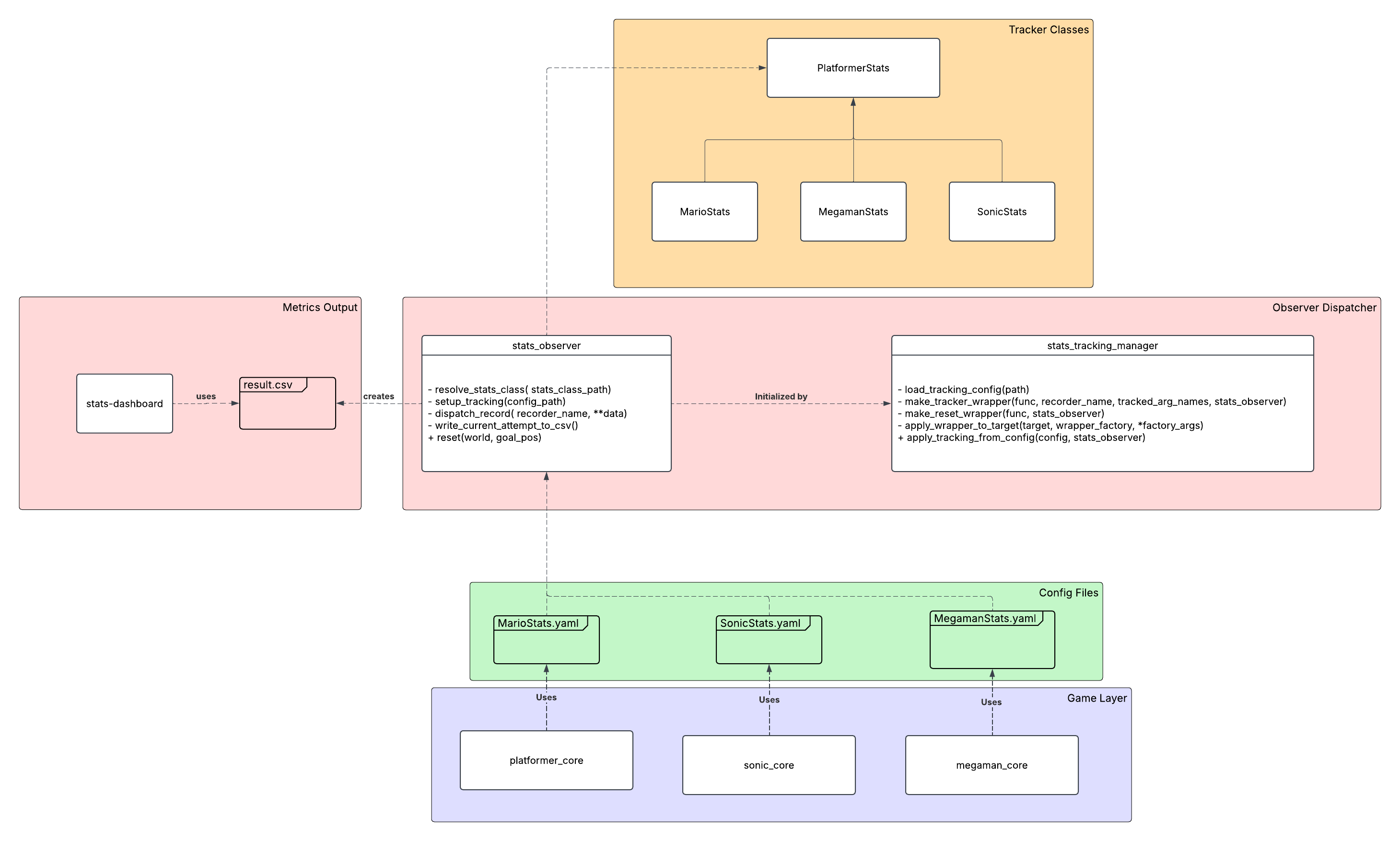
I created a simple diagram on how everything works together at the end:
Dashboard
Using the sample data I was collecting, I created a simple Streamlit dashboard that should be similar to what a designer would see when they run their agents loose.
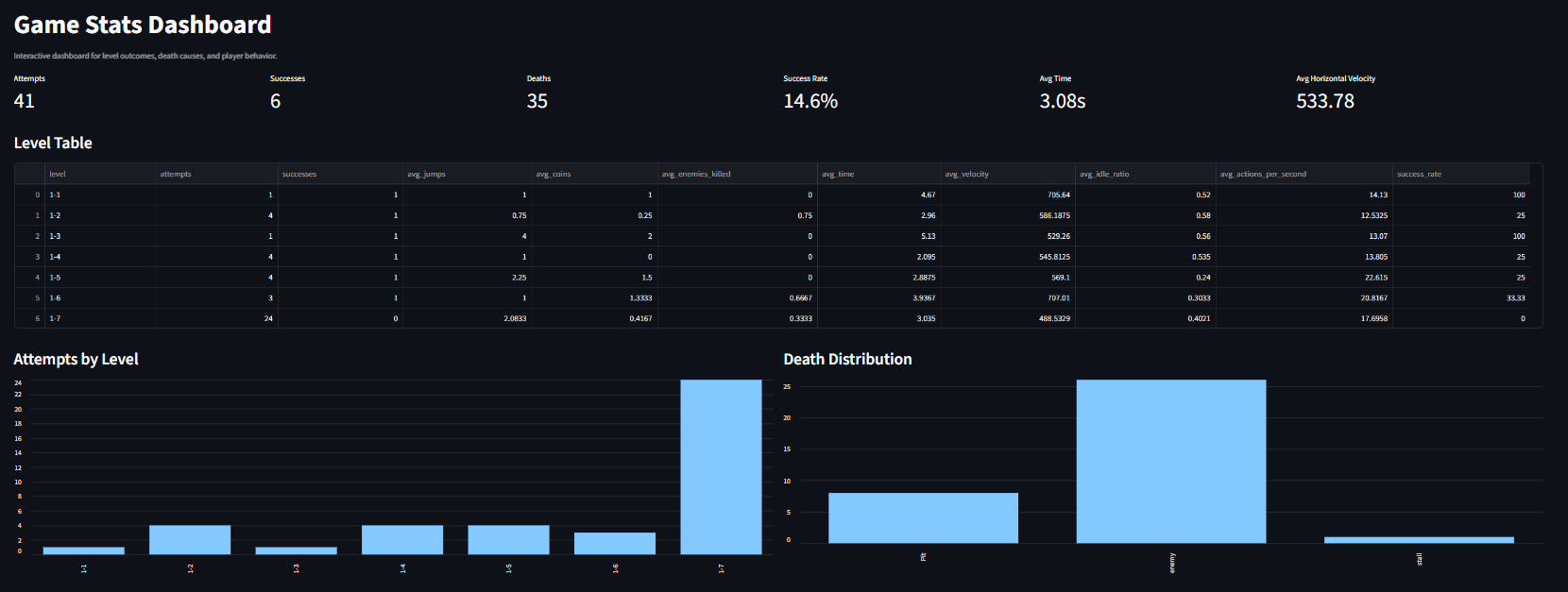
Of course, this is not very useful right now; after all, it doesn't give insightful information, but this is a start.
Future Work
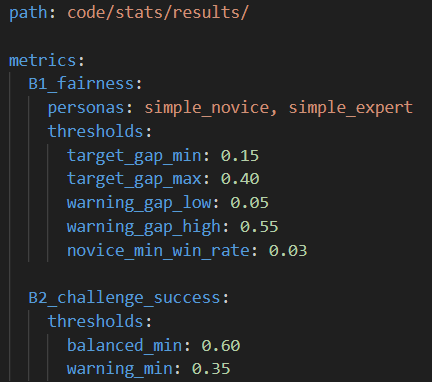
We are currently in the process of defining actually useful data and figuring out how a designer would define thresholds. An idea of threshold definition is another config file where a designer specifies target personas (which are agent behaviors and skills), required maximum and minimum values, and possibly required gaps among agents. This is an idea of how it could look:
For metrics, we brainstormed using Claude with references to The Art of Game Design book to come up with case study metrics that a designer might actually find useful. We came up with that list of metrics and challenges for collecting those metrics:
- Completion Rate: how many attempts it takes to win a level.
- Mean Completion Time: average time of successful runs.
- Progress: When do agents die at each attempt?
- Death Cluster: How spread out are deaths? This is challenging because we don't know how to measure that.
- Number of different paths agents take: This is challenging because we don't know how to specify that.
- Coin Time Cost: difference in time between runs that collect coins and runs that go directly for the goal.
We will see how this goes. We are still not sure how useful and easy to use designers would find this tool, but this is why we experiment!