Or: how to learn about clip/siglip and vector encoding images
tl;dr: I built a meme search engine using siglip/CLIP and vector encoding images. It was fun and I learned a lot.
I have been building a lot of applied AI tools for a while. One of the components that always seemed the most magical has always been vector embeddings. Word2Vec and the like have straight blown my mind. It is like magic.
I saw a simple app on hacker news that was super impressive. Someone crawled a bunch of Tumblr images and used siglip to get the embeddings and then made a simple “click the image and see similar images” app. It was like magic. I had no idea how to achieve this, but it seemed accessible.
I decided to use my sudden motivation as an opportunity to learn how “all this works.”
wut
If you have never ran into vector embeddings, clip/siglip, vector databases, and the like - never fear.
Before I saw the hack on hn I really didn’t think much about vector embeddings, multi modal embeddings or vector datastores. I had used faiss (facebooks simple vector store), and Pinecone ($$) for some hacks, but didn’t really dig in. Just got it to work and then was like “yep. Tests pass.”
I still barely know what vectors are. Lol. Before I dug in and built this, I really didn’t understand how I would use it outside of RAG or another LLM process.
I learn by building. It helps if the results are really intriguing, and in this case kind of magical.
WTF terms
I had a few friends read this over before publishing and a couple were like “wtf is X?” Here is a short list of terms that were largely new to me:
- Vector Embeddings - Vector embeddings convert your text of images into numerical representations, allowing you to find similar pics and search your library effectively.
- Vector Database - A vector database is a way to store and search through encoded items, enabling you to find similar items.
- Word2Vec - Word2Vec is a groundbreaking technique that converts words into numerical vectors, enabling you to perform tasks like finding similar words and exploring relationships between them.
- CLIP - CLIP is OpenAI’s model that encodes images and text into numerical vectors.
- OpenCLIP - OpenCLIP is an open-source implementation of OpenAI’s CLIP model, allowing anyone to use and build upon this powerful image and text encoding technology without the need for special access or permissions.
- FAISS - FAISS is an efficient library for managing and searching through large collections of image vectors, making it fast and easy to find the images you’re looking for.
- ChromaDB - ChromaDB is a database that stores and retrieves your image and text vectors, quickly returning similar results for your searches.
Keep it simple, harper.
This is a pretty straight forward hack. I am just fucking around so I wasn’t super interested in making it scalable. I did have an interest in making it replicable. I wanted to make something that you could run without a lot of work.
One of my goals was to make sure everything runs locally to my laptop. We have these fancy Mac GPUs - let’s heat them up.
The first step was building out a simple crawler that would crawl a directory of images. I use Apple Photos, so I didn’t have a directory full of my photos laying around. I did, however, have a giant bucket of memes from my precious and very secret meme chat group (don’t tell anyone). I exported the chat, moved the images to a directory and BAM - I had my test image set.
The Crawler
I created the world’s worst crawler. Well. I should be honest: Claude created the world’s worst crawler with my instructions.
It is a bit complicated but here are the steps:
- It gets the file list of the target directory
- It stores the list in a msgpack file
- I reference the msgpack file and then iterate through every image and store it in a sqlite db. Grabing some metadata about the file
- I iterate through that sqlite db and then use CLIP to get the vector encoding of every image.
- Then I store those vectors back in the sqlite db
- Then I iterate through the sqlite db and insert the vectors and image path into chroma vector db
- Then we are done
This is a lot of wasted work. You could iterate through the images, grab the embeddings and slam it into chroma (I chose chroma cuz it is easy, free, and no infra).
I have built it this way because:
- After the memes, I crawled 140k images and wanted it to be resilient to crashing.
- I needed it to be able to resume building out the databases in case it crashed, power went out, etc
- I really like loops
Regardless of the extra complexity, it worked flawlessly. I have crawled over 200k images without a blip.
An embedding system
Encoding the images was fun.
I started with siglip and created a simple web service where we could upload the image and get the vectors back. This ran on one of our GPU boxes at the studio and worked well. It wasn’t fast, but it was way faster than running open clip locally.
I still wanted to run it locally. I remembered that the ml-explore repo from apple had some neat examples that could help. And BAM they had a clip implementation that was fast af. Even using the larger model, it was faster than the 4090. Wildstyle.
I just needed to make it easy to use in my script.
MLX_CLIP
Claude and I were able to coerce the example script from apple into a fun lil python class that you can use locally on any of your machines. It will download the models if they don’t exist, convert them, and then use them in flight with your script.
You can check it out here: https://github.com/harperreed/mlx_clip
I am pretty chuffed with how well it turned out. I know most people know this, but the apple silicon is fast af.
It turned out to be rather simple to use:
import mlx_clip
# Initialize the mlx_clip model with the given model name.
clip = mlx_clip.mlx_clip("openai/clip-vit-base-patch32")
# Encode the image from the specified file path and obtain the image embeddings.
image_embeddings = clip.image_encoder("assets/cat.jpeg")
# Print the image embeddings to the console.
print(image_embeddings)
# Encode the text description and obtain the text embeddings.
text_embeddings = clip.text_encoder("a photo of a cat")
# Print the text embeddings to the console.
print(text_embeddings)
I would love to get this to work with siglip, as I prefer that model (it is way better than CLIP). However, this is a POC more than a product I want to maintain. If anyone has any hints on how to get it working with siglip - hmu. I don’t want to reinvent open clip - which should theoretically run well on apple silicon, and is very good.
Now what
Now that we had all the image vectors slammed into the vector datastore we could get started with the interface. I used the built in query functionality of chromadb to show similar images.
Grab the vectors of the image you are starting with. Query those vectors with chromadb. Chromed returns a list of image ids that are similar in declining similarity.
I then wrapped it all up in a tailwind/flask app. This was incredible.
I can’t imagine the amount of work we would have done in 2015 to build this. I spent maybe 10 hours total on this and it was trivial.
The results are akin to magic.
Memes concept search
Now remember, I used memes as my initial set of images. I had 12000 memes to search through.
Start with this:

Encode it, pass it to chroma to return similar results.
And then similar images that return are like this:

Another example:

Gives you results like:

It is really fun to click around.
Namespaces?
The magic isn’t clicking on an image and getting a similar image. That is cool, but wasn’t “holy shit” for me.
What blew my mind was using the same model to encode the search text into vectors and finding images similar to the text.
For whatever reason, this screws up my brain. It is one thing to have a neat semantic like search for images based on another images. Being able to have a nice multi modal interface really made it like a magic trick.
Here are some examples:
Searching for money. I grab the encoding for money and pass the vectors to chroma. The results for money are:
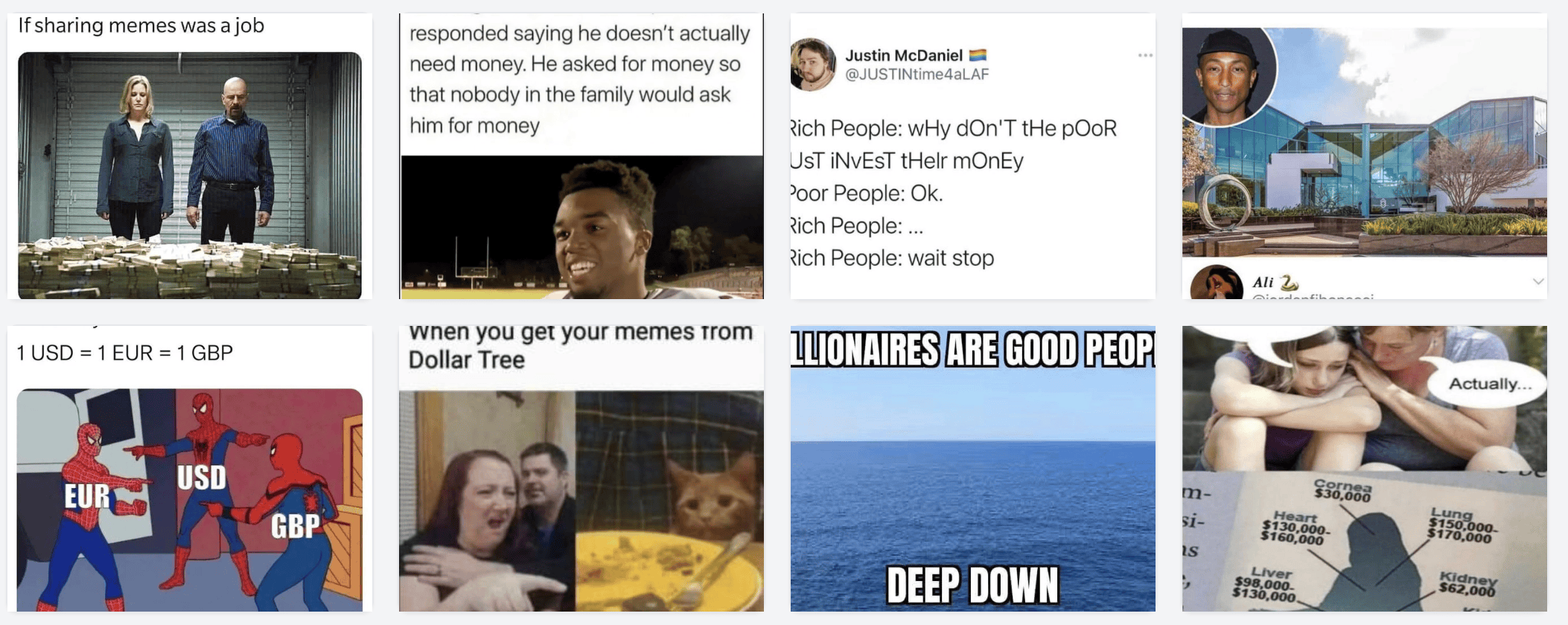
Searching for AI
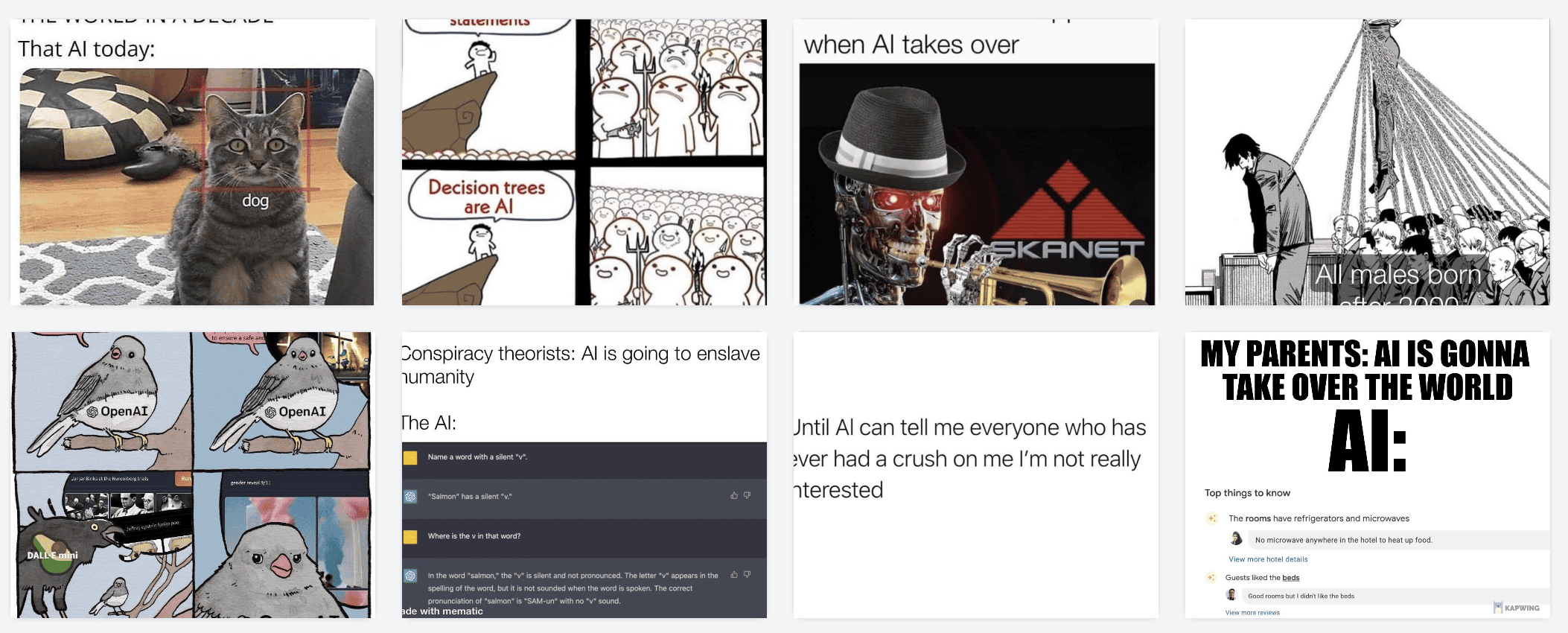
Searching for red (a dozy! Is it a color? Is a lifestyle? Is it Russia?)
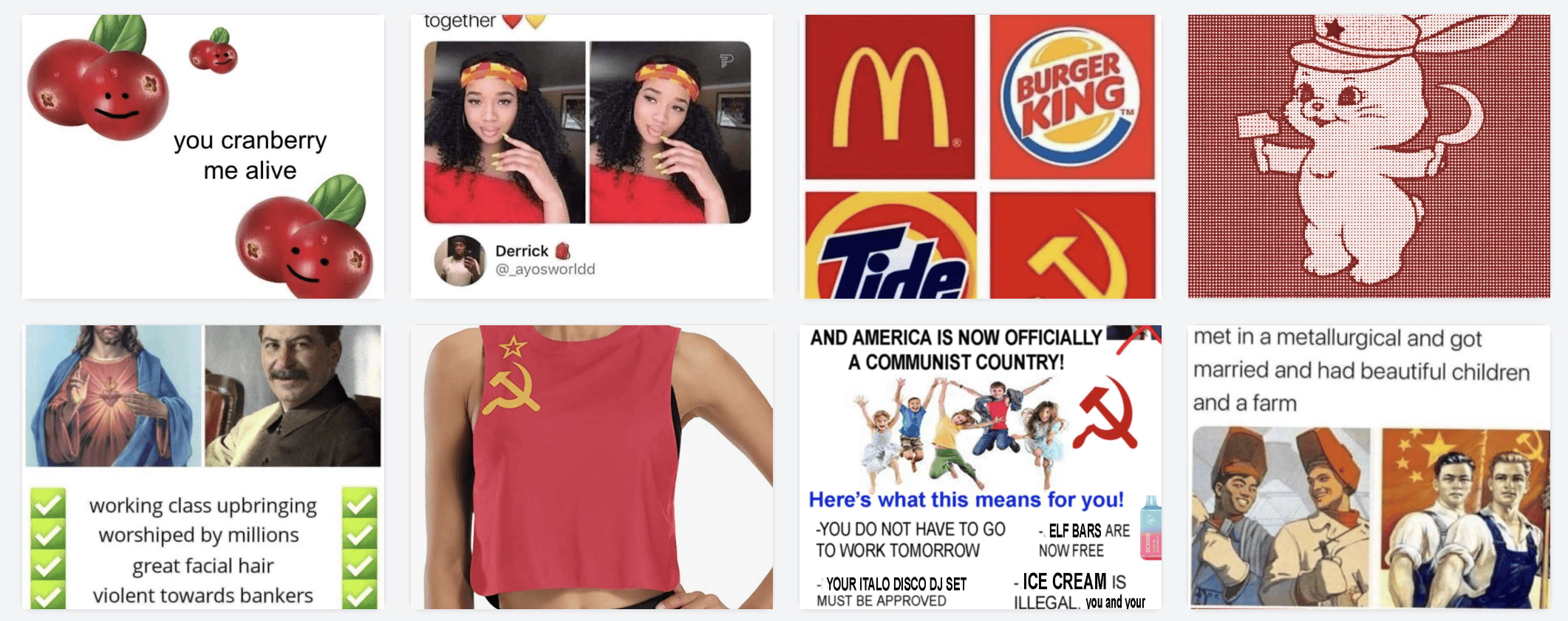
So on and so forth. Forever. It is magical. You can find all sorts of gems you forgot about. Oh shit I need a meme about writing a blog post:

(I am self aware, I just don’t care - lol)
How does it work with a photo library?
It works super well.
I highly recommend running this against your photo library. To get started, I downloaded my google photos takeout archive. Extracted it onto an external disk. I had to run a few scripts against it to make it usable (Whoever designed the google photos takeout is very excited about duplicate data). I then pointed the script at that directory instead of my memes folder and let ’er rip.
I had about 140k photos and it took about 6 hours to run through. Not so bad. The results are incredible.
Here are some fun examples:
Obviously these are similar (I also have a dupe problem in google photos)

We have had a lot of poodles. Here are some

You can search for landmarks. I had no idea I had taken a photo of fuji-san from a plane!

And then find similar images of Mt Fuji.

It is pretty easy to search for places.

Or emotions. I am apparently surprising so I have a lot of surprised photos.

Also niche things like low riders. (These are from Shibuya!)

And you can use it to find things that are not easy to find or search for. Like bokeh.

It’s wonderful, because I can click through and find great images I had forgotten about. Like this great photo of Baratunde that I took in 2017:

This will be everywhere
I imagine that we will see this tech rolled into all the various photo apps shortly. Google Photos probably already does this, but they have googled it so much that nobody notices.
This is too good to not roll into whatever photo app you use. If I had any large scale product that used photos or images, I would immediately set up a pipeline to start encoding the images to see what kind of weird features this unlocks.
YOU CAN USE THIS FOR THE LOW PRICE OF FREE
I put the source here: harperreed/photo-similarity-search.
Please check it out.
It is pretty straight forward to get going. It is a bit hacky. lol.
I would use conda or something similar to keep things clean. The interface is simple tailwind. The web is flask. The code is python. I am your host, harper reed.
My challenge for you!
Please build an app that I can use to catalog my photo library in a nice way. I don’t want to upload to another destination. I want to have a simple Mac app that I can point to my photo library and say “crawl this.” I imagine a lot of neat stuff could be added:
- Llava/Moondream auto captioning
- Keywords / Tags
- Vector similarity
- etc
It should run locally. Be a native app. Be simple, and effective. Maybe plug into Lightroom, capture one, or apple photos.
I want this. Build it. Let’s discover all the amazing photos we have taken through the magic of AI.
My hacking buddy Ivan was around while I was building this. He immediately saw the magic of what a person could discover by using this on their photo library. He wanted to use it immediately.
His photo catalog is on an external hard drive - but he had his Lightroom preview file locally. He wrote a quick script to extract the thumbnails and metadata from the preview file and save it to an external disk.
We then ran the image vector crawler and BAM - he could see similar images and what not. Worked perfectly.
Recover your Lightroom photos. Or at least the thumbnails.
Ivan’s simple script to extract the images from the preview file is really awesome. If you have ever lost your real photo library (corrupt harddrive, or whatever) and you still have the lrpreview file - this script can help you extract at least the lower res version.
A super handy script to keep around.
You can check it out here: LR Preview JPEG Extractor.
Thanks for reading.
As always, hmu and let’s hang out. I am thinking a lot about AI, Ecommerce, photos, hifi, hacking and other shit.
If you are in Chicago come hang out.