When you render HTML on the backend — e.g. with Phlex — how do you get it to the browser? One way is to have the user click a link, submit a form or reload the page. Alternatively, in response to some user interaction or push event, you could have JavaScript fetch new HTML and replace the DOM locally.
myElement.outerHTML = newHTMLThe problem with these approaches is they lose state. Form inputs lose focus, text selection and scroll positions reset, event listeners and observers are detached, popovers and dialogs disappear, iframes reload and CSS animations are interrupted.
DOM Morphing attempts to solve this by carefully comparing the original DOM tree to the new DOM tree and “morphing” the original tree to match the new tree.
There are a number of established morphing libraries to choose from. To name just a few, there’s:
Today, I’m introducing my own take on DOM morphing, Morphlex 1.0.
The node identity problem
The biggest problem in DOM morphing is node identity. How do you determine that one node in the original DOM is the same as another node in the new DOM? It could have been moved, removed or updated or a new node could have been inserted in its place.
One solution is to depend on id attributes. If a node in the new DOM has the same id as a node in the original DOM, you can assume that this is the same node, even if its content has changed.
The unfortunate reality is most DOM is lacking in id attributes. Idiomorph pioneered an interesting technique to improve on this.
Since id attributes are unique on a page and since elements can have only one parent node, the ids of child nodes can be used to uniquely identify their parent nodes at any given depth level.
This works becuase the set of ids of any node’s children is unique at any level.
Essentially what Idiomorph does is scan the DOM for elements with ids and then walk up each element’s ancestors adding that element’s id to the the ancestor’s id set.
Say you have some DOM that looks like this.
<section>
<article id="article-1">
<div>
<h1 id="heading-1">Hello!</h1>
</div>
</article>
</section>If we picture the computed id sets as pseudo HTML attributes, they would look like this.
<section id-set="article-1 heading-1">
<article id="article-1" id-set="article-1 heading-1">
<div id-set="heading-1">
<h1 id="heading-1" id-set="heading-1">Hello!</h1>
</div>
</article>
</section>You can see how even though the <section> element never had an id, it can still be uniquely identified amongst its peers at its level by the set of ids of its children.
While this definitely improves things, its still not perfect. When there are no ids around, most DOM morphing libraries fall back to selecting the next element with the same tag name.
Unfortunately, this often leads to unnecessary cascading morphs in many realistic scenarios.
Inserting items
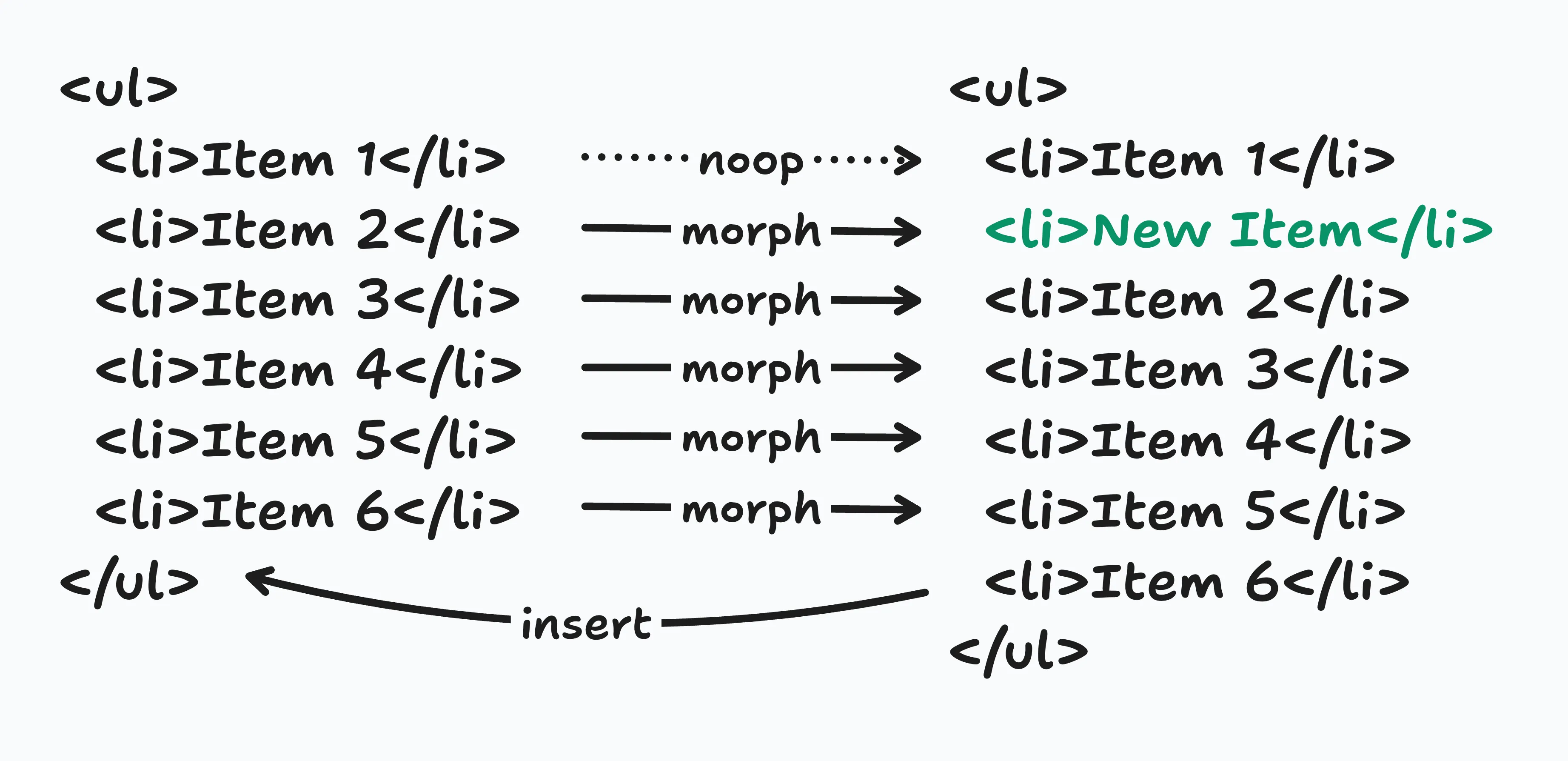
One common scenario is morphing to a new tree that’s exactly the same as the original tree except there’s one new node in a list.
In this example, when there are no ids, the algorithm selects the next element with the same tag name and converts that to match the corresponding element in the new DOM.

Item 1 is the same on both sides but since Item 2 was converted to New Item, Item 3 now has to be converted to Item 4, and Item 4 needs to become Item 5, and so on…
Ideally, the algorithm would be able to look ahead and see that there is a corresponding element in the original tree for all but one of the elements in the new tree. It could then just insert the new element into the correct position.

It’s essentialy the same when removing nodes. Item 2 is morphed into Item 3 which means Item 3 needs to be morphed into Item 4 and Item 4 into Item 5. After we morph Item 5 into Item 6, we’re left with a final node which needs to be removed.

Ideally, the algorithm would instead look ahead and see that the original DOM already has a copy of all the items in the new DOM and so the only thing left to do is remove Item 2.

Sorting items is just as bad. In this example, we’re only moving Item 3 up two places, but we have to do four morphs to get there.

Ideally, we would find the longest increasing subsequence — in this case, 1, 2, 4, 5, 6 and 7 and ignore these nodes since they’re in the right position already. Then we could just move the remaining item into place in one step.

How Morphlex solves these problems
At each level of the tree, Morphex has a matching algorithm that tries to find the best match between elements in the original tree and the new tree.
First, it creates a set of elements on the left and another set of elements on the right. It also creates array of matches.
It iterates over each element on the left, comparing them to each element on the right. The initial comparison uses isEqualNode to see if the nodes are exactly the same already. If it finds a perfect match, it removes the elements from their corresponding sets and writes them into the correct index on the matches array.
Then it iterates again, matching by exact id, and again by id set, then by tag name and the attributes name, href or src, and finally by tag name alone — or if it’s an input, by tag name and input type.
It removes the matched elements from their corresponding sets as it goes, so the iterations become cheaper and cheaper on each pass.
After matching, we’re left with a set of elements from the old tree to remove, a set of elements from the new tree to insert, and an array that maps old elements to matching new elements.
This array of matches is then used to calculate the longest increasing subsequence for optimal sorting.
Finally, everything is moved into place using moveBefore which maintains all the original state. If moveBefore isn’t available, insertBefore is used instead.
You might be wondering how we can get away with using isEqualNode, since isEqualNode can’t tell, for example, if you have changed the value of an input element.
To get around this, we first iterate over all form inputs in the original tree and add a special attribute if the current value is different to the default value (if the value has been changed by a user). This special attribute allows isEqualNode to detect the change, then we can quietly remove the special attribute later on in the process.
Having said that, my preference is to leave modified input values in place, since they were likely intended by the user. Morphlex provides the configuration option preserveChanges for this.
Performance
It’s difficult to say how Morphlex compares to Morphdom / Idiomorph because they do effectively do different things. For example, there are scenarios where Morphdom will just replace what Morphlex will spend time matching and moving.
However Morphlex typically ends up doing significantly less work than other DOM morphing libraries in real world scenarios due to its design, so it’s very fast. The performance and accuracy are good enough to do whole document morphs in my limited experience.
Morphlex is released under an MIT license. Please let me know if you find any bugs.
Enjoy ❤️