When I started at AWS in 2008, we ran the EC2 control plane on a tree of MySQL databases: a primary to handle writes, a secondary to take over from the primary, a handful of read replicas to scale reads, and some extra replicas for doing latency-insensitive reporting stuff. All of thing was linked together with MySQL’s statement-based replication. It worked pretty well day to day, but two major areas of pain have stuck with me ever since: operations were costly, and eventual consistency made things weird.
Since then, managed databases like Aurora MySQL have made relational database operations orders of magnitude easier. Which is great. But eventual consistency is still a feature of most database architectures that try scale reads. Today, I want to talk about why eventual consistency is a pain, and why we invested heavily in making all reads strongly consistent in Aurora DSQL.
Eventual Consistency is a Pain for Customers
Consider the following piece of code, running against an API exposed by a database-backed service:
id = create_resource(...)
get_resource_state(id, ...)In the world of read replicas, the latter statement can do something a little baffling: reply ‘id does not exist’. The reason for this is simple: get_resource_state is a read-only call, likely routed to a read replica, and is racing the write from create_resource. If replication wins, this code works as expected. If the client wins, it has to handle to weird sensation of time moving backwards.
Application programmers don’t really have a principled way to work around this, so they end up writing code like this:
id = create_resource(...)
while True:
try:
get_resource_state(id, ...)
return
except ResourceDoesNotExist:
sleep(100)Which fixes the problem. Kinda. Other times, especially if ResourceDoesNotExist can be thrown if id is deleted, it causes an infinite loop. It also creates more work for client and server, adds latency, and requires the programmer to choose a magic number for sleep that balances between the two. Ugly.
But that’s not all. Marc Bowes pointed out that this problem is even more insidious:
def wait_for_resource(id):
try:
get_resource_state(id, ...)
return
except ResourceDoesNotExist:
sleep(100)
id = create_resource(...)
wait_for_resource(id)
get_resource_state(id) Could still fail, because the second get_resource_state call could go to an entirely different read replica that hasn’t heard the news yet3.
Strong consistency avoids this whole problem1, ensuring that the first code snippet works as expected.
Eventual Consistency is a Pain for Application Builders
The folks building the service behind that API run into exactly the same problems. To get the benefits of read replicas, application builders need to route as much read traffic as possible to those read replicas. But consider the following code:
block_attachment_changes(id, ...)
for attachment in get_attachments_to_thing(id):
remove_attachment(id, attachment)
assert_is_empty(get_attachments_to_thing(id))This is a fairly common code pattern inside microservices. A kind a little workflow that cleans something up. But, in the wild world of eventual consistency, it has at least three possible bugs:
- The
assertcould trigger because the secondget_attachments_to_thinghasn’t heard the news of all theremove_attachments. - The
remove_attachmentcould fail because it hasn’t heard of one of the attachments listed byget_attachments_to_thing. - The first
get_attachments_to_thingcould have an incomplete list because it read stale data, leading to incomplete clean up.
And there are a couple more. The application builder has to avoid these problems by making sure that all reads that are used to trigger later writes are sent to the primary. This requires more logic around routing (a simple “this API is read-only” is not sufficient), and reduces the effectiveness of scaling by reducing traffic that can be sent to replicas.
Eventual Consistency Makes Scaling Harder
Which brings us to our third point: read-modify-write is the canonical transactional workload. That applies to explicit transactions (anything that does an UPDATE or SELECT followed by a write in a transaction), but also things that do implicit transactions (like the example above). Eventual consistency makes read replicas less effective, because the reads used for read-modify-write can’t, in general, be used for writes without having weird effects.
Consider the following code:
UPDATE dogs SET goodness = goodness + 1 WHERE name = 'sophie'If the read for that read-modify-write is read from a read replica, then the value of goodness may not be changed in the way you expect. Now, the database could internally do something like this:
SELECT goodness AS g, version AS v FROM dogs WHERE name = 'sophie'; -- To read replica
UPDATE sophie SET goodness = g + 1, version = v + 1 WHERE name = 'sophie' AND version = v; -- To primaryAnd then checking it actually updated a row2, but that adds a ton of work.
The nice thing about making scale-out reads strongly consistent is that the query processor can read from any replica, even in read-write transactions. It also doesn’t need to know up-front whether a transaction is read-write or read-only to pick a replica.
How Aurora DSQL Does Consistent Reads with Read Scaling
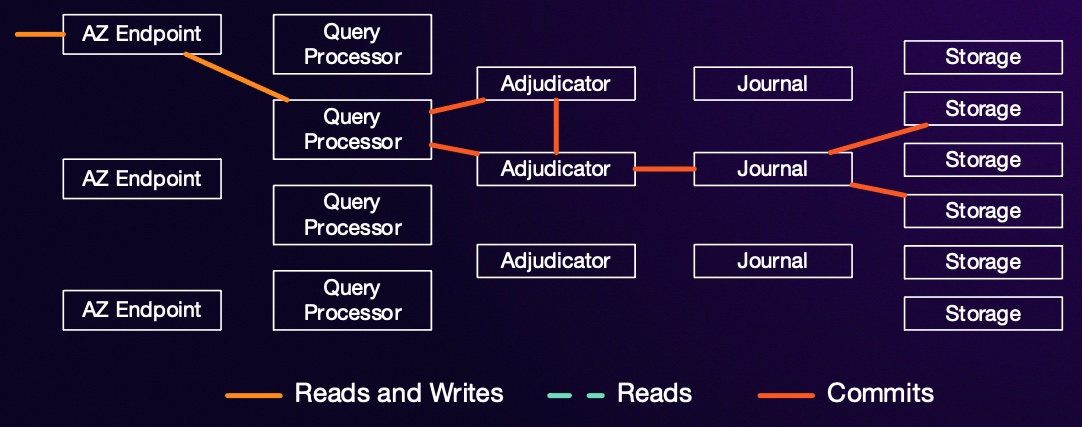
As I said above, in Aurora DSQL all reads are strongly consistent. DSQL can also scale out reads by adding additional replicas of any hot shards. So how does it ensure that all reads are strongly consistent? Let’s remind ourselves about the basics of the DSQL architecture.

Each storage replica gets its updates from one or more journals. Writes on each journal are strictly monotonic, so once a storage node has seen an update from time $\tau$ it knows it has seen all updates for times $t \leq \tau$. Once it has seen $t \geq \tau$ from all the journals it has subscribed to, it knows that it can return data for time $\tau$ without missing any updates. When a query processor starts a transaction, it picks a time stamp $\tau_{start}$, and every time it does a read from a replica it says to the replica “give me data as of $\tau_{start}$”. If the replica has seen higher timestamps from all journals, its good to go. If it hasn’t yet, it blocks the read until the write streams catch up.
I go into some detail on how $\tau_{start}$ is picked here:
Conclusion
Strong consistency sounds like a complex topic for distributed systems nerds, but is a real thing that applications built on traditional database replication architectures need to start dealing with at modest scale - or even at very small scale if they’re trying to offer high availability. DSQL goes to some internal lengths to make all reads consistent - with the aim of saving application builders and end users from having to deal with this complexity.
I don’t mean to say that eventual consistency is always bad. Latency and connectivity trade-offs do exist (although the choose-two framing of CAP is bunk), and eventual consistency has its place. However, that place is probably not in your services or API.
Footnotes
- You might point out that this particular problem can be fixed with a weaker set of guarantees, like Read Your Writes, provided by client stickiness. However, this falls down pretty quickly in more complex data models, and cases like IaC where ‘your writes’ is less well defined.
- Yes, I know there are other ways to do this.
- If we want to get technical, this is because the typical database read replica pattern doesn’t offer monotonic reads, where the set of writes a reader sees is increasing over time. Instead, writes at the tip can appear to come and go arbitrarily, as requests are routed to different replicas. See Doug Terry’s Replicated Data Consistency Explained Through Baseball for an easy introduction into these terms.