I've been trying to think through what happens to programming languages and tooling if humans are increasingly no longer writing it. I wrote about how good agents are at porting code recently, and it got me thinking a bit more about what constraints LLMs have vs humans.
One of the biggest constraints LLMs have is on context length. This is a difficult problem to solve, as memory usage rises significantly with longer context window in current transformer architectures. And with the current memory shortages, I don't think the world is drowning in memory right now.
As such, for software development agents, how 'token efficient' a programming language actually could make a big difference and I wonder if it starts becoming a factor in language selection in the future. Given a significant amount of a coding agents context window is going to be code, a more token efficient language should allow longer sessions and require fewer resources to deliver.
We've seen TOON (an encoding of JSON to be more token efficient), but what about programming languages?
Methodology
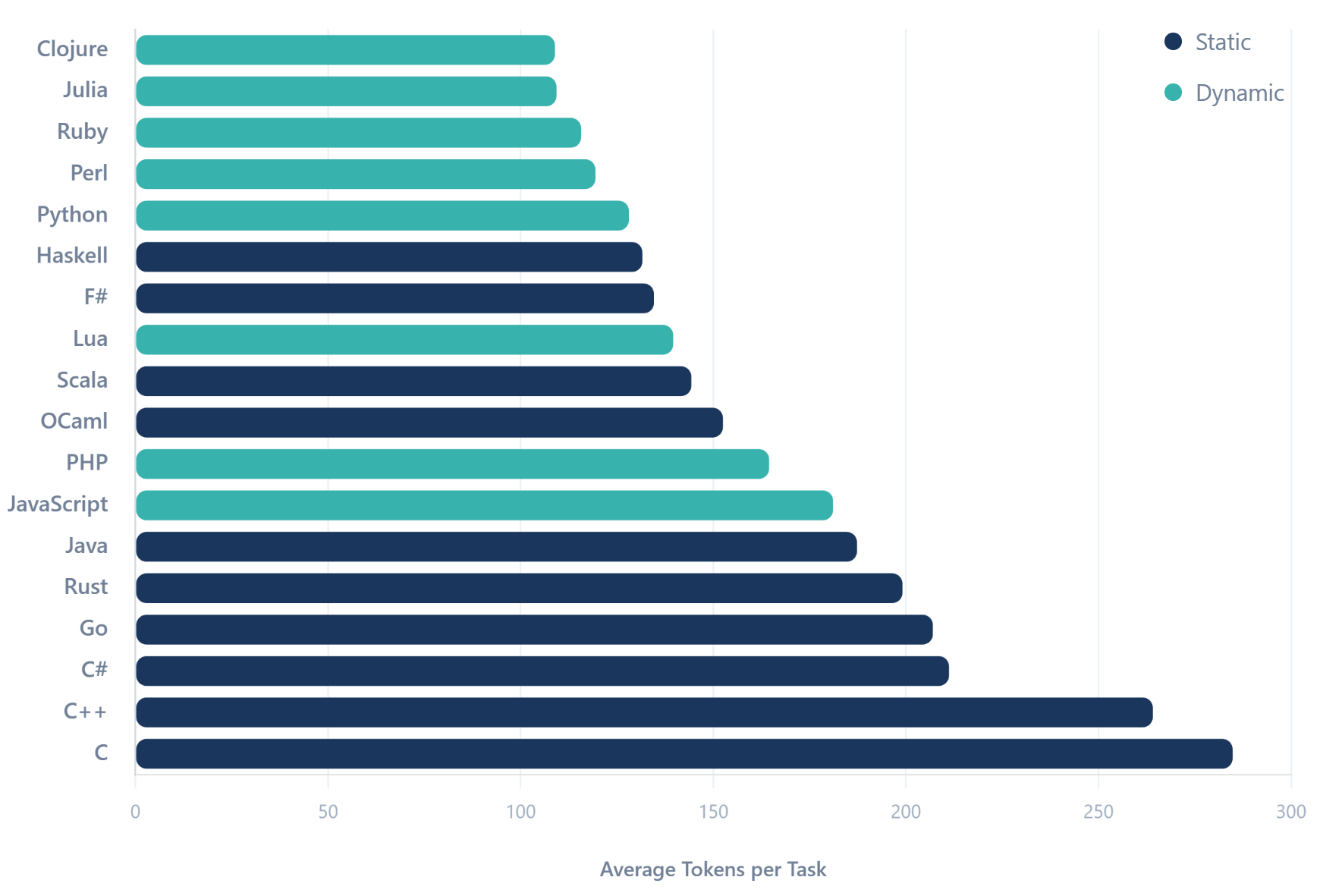
I came across the RosettaCode project while doing some research thinking around this. It describes itself a programming chrestomathy site (which I love, by the way). It has over a thousand programming 'tasks' that people build in various languages. It has contributions in nearly 1,000 different programming languages.
I found a GitHub mirror of the dataset, so grabbed Claude Code and asked it to make a comparison of them, using the Xenova/gpt-4 tokenizer from Hugging Face - which is a community port of OpenAI's GPT4 tokenizer.
I then told Claude Code to suggest a selection of the most popular programming languages, which roughly matches my experience, and then find tasks that had solutions contributed in all 19 of these languages, and then ran them through the tokenizer. I didn't include TypeScript because there were very few tasks in the Rosetta Code dataset.
There are many, many potential limits and biases involved in this dataset and approach! It's meant as a interesting look at somewhat like-for-like solutions to some programming tasks, not a scientific study.
Results

Update: A lot of people asked about APL. I reran on a smaller set of like-for-like coding tasks - it came 4th at 110 tokens. Turns out APL's famous terseness isn't a plus for LLMs: the tokenizer is badly optimised for its symbol set, so all those unique glyphs (⍳, ⍴, ⌽, etc.) end up as multiple tokens each.
Update 2: A reader reached out about J - a language I'd never heard of. It's an array language like APL but uses ASCII instead of special symbols. It dominates at just 70 tokens average, nearly half of Clojure (109 tokens). Array languages can be extremely token-efficient when they avoid exotic symbol sets. If token efficiency turns out to be a key driver, this is perhaps a very interesting way for languages to evolve.
There was a very meaningful gap of 2.6x between C (the least token efficient language I compared) and Clojure (the most efficient).
Unsurprisingly, dynamic languages were much more token efficient (not having to declare any types saves a lot of tokens) - though JavaScript was the most verbose of the dynamic languages analysed.
What did surprise me though was just how token efficient some of the functional languages like Haskell and F# were - barely less efficient than the most efficient dynamic languages. This is no doubt to their very efficient type inference systems. I think using typed languages for LLMs has an awful lot of benefits - not least because it can compile and get rapid feedback on any syntax errors or method hallucinations. With LSP it becomes even more helpful.
Assuming 80% of your context window is code reads, edits and diffs, using Haskell or F# would potentially result in a significantly longer development session than using Go or C#.
It's really interesting to me that we are in this strange future where we have petaflops of compute but code verbosity of our 'small' context windows actually might matter. LLMs continue to break my mental model of how we should be looking at software engineering.