getting 20x speedup by removing code.
February 2, 2026 · 2 min read · tech, performance
I love working at oxen because we strive to be the fastest data versioning tool in the market. Which is why we often do multi terabyte benchmarks on each commands that we support , (add, commit, etc.)
All staged files, their location and the file hashes get stored in a rocksdb
when oxen add command is used, then during oxen commit we create new nodes for new files/dirs and commit.
I was noting that our add times were pretty quick. ~1 minute for 1M files. But, commit was taking >50 minutes. This was interesting to me because commit is an O(n) algorithm with n = number of directories. we create n directory nodes and 1 commit node, that is all. even with a million files that is not that many directories.
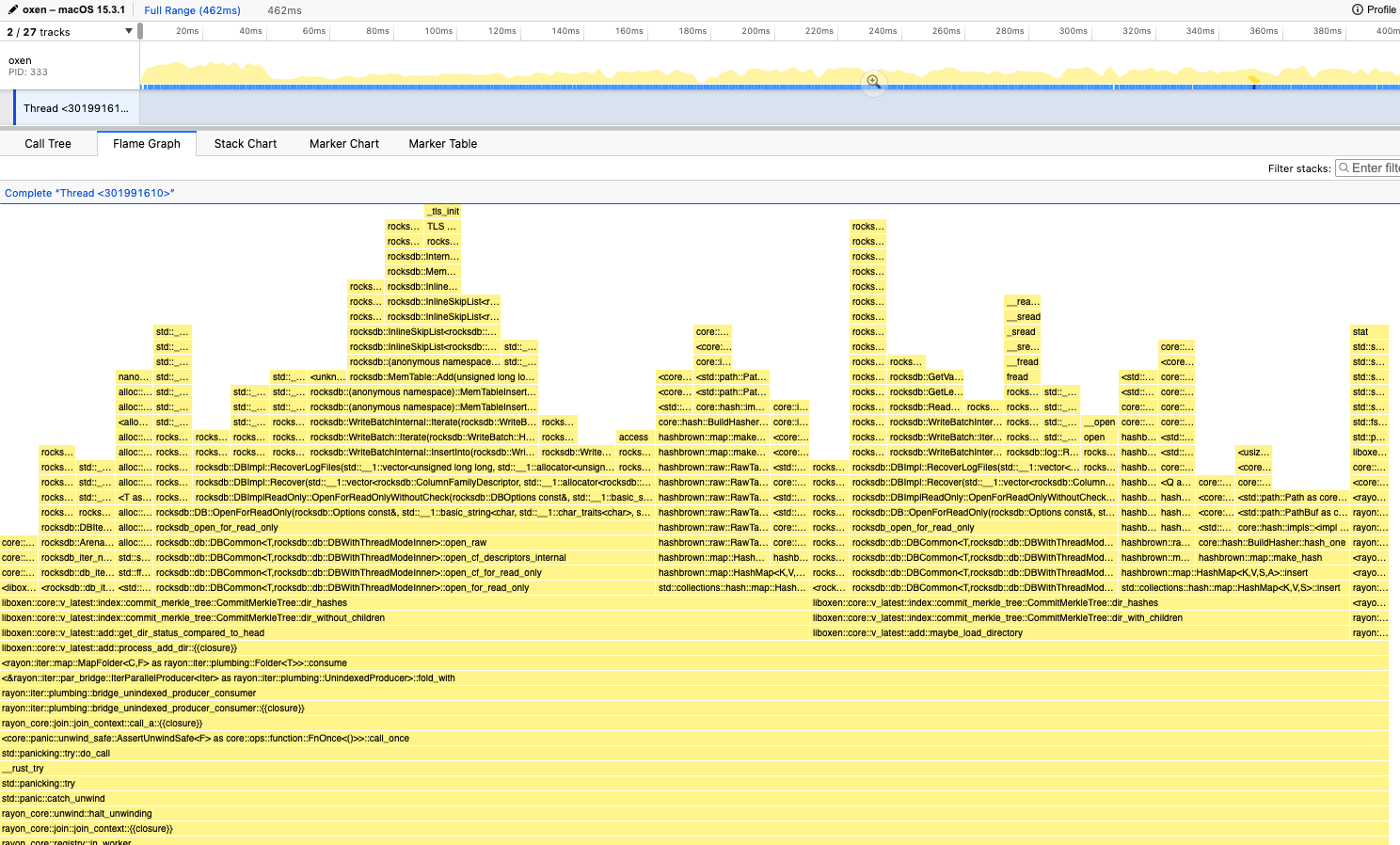
As is usual for all performance work. I profiled the commit command with, samply
which is a wildly convenient tool to profile binaries and view it on a nice UI.

If you notice closely, >90% of the time was being spent just getting the lock on the staging RocksDB. This was because all our parallel workers are graduating the files from staged to committed by creating the respective nodes for the directories and creating a complete view of the repository at that commit.
but because we have this data (file name, etc.) passed back and forth between different layers in the code. we were doing lots of .clone() and db.open() at different layers to fetch the same data. The interesting part for me was that, this change reduced our
The final PR looked like this to improve performance by 20X

With performance sensitive application. Often less is more and simple is better.
I often think about this quote from Fabien .

In this case, it was true. In good software engineering fashion, all our layers had clear separation of concerns. Which lead to repeated context retrieval for each thread / async operation leading to thread contention for the same resource. Personally this was a lesson for me on thinking about the Design and impact of the whole system even when adding a seemingly isolated feature.
As an aside it is interesting that, rocksdb is not the ideal candidate for our “parallel reads” use case, because rocksdb is designed for parllel writes. which is why we see this unexpected overhead.