arXivLabs 是一个允许合作者直接在我们的网站上开发和共享 arXiv 新功能的框架。与 arXivLabs 合作的个人和组织都认同并接受了我们对开放、社区、卓越和用户数据隐私的价值观。arXiv 致力于秉持这些价值观,并仅与遵守这些价值观的合作伙伴进行合作。如果您有能为 arXiv 社区增值的项目创意,请了解更多关于 arXivLabs 的信息。
每日HackerNews RSS
极致防护 Maxproof
17 天前
抱歉。
大卫·霍克尼去世,享年 88 岁,他曾将人体形态重新带回艺术领域 David Hockney, Who Restored the Human Form to Art, Dies at 88
17 天前
请启用 JavaScript 并关闭所有广告拦截器。
艺术界正为大卫·霍克尼(David Hockney)的离世而哀悼,享年 88 岁。霍克尼以其宏大、生动的画作和细腻的素描而闻名,作为一位高产的创新者,他在漫长的职业生涯中不断演进,备受赞誉。
Hacker News 的用户们不仅铭记他在人体形态上的技术造诣,更推崇他那开放且对技术终身保持热忱的精神。从他开创性地研究古典大师所使用的光学辅助设备(即“霍克尼-法尔科”理论),到晚年尝试 iPad 绘画,霍克尼始终是一位具有前瞻性的媒介探索者。
除了艺术上的贡献,评论者们还分享了他的作品对个人产生的深远影响。一位用户表示,正是霍克尼关于艺术与科学交叉的理论,帮助他们度过了个人身份危机,并最终走向了职业成功。尽管对于其数字作品与传统画布作品的质量存在争议,但人们普遍认为,他那求知的精神、敏锐的观察力,以及作为“观看”艺术的践行者所留下的遗产,已在当代文化中留下了不可磨灭的印记。
Kimi K2.7-Code:具有更高词元效率的开源编码模型 Kimi K2.7-Code: open-source coding model with better token efficiency
17 天前
**Kimi K2.7 Code** 是一款专为软件工程和复杂编码任务进行优化的先进智能体模型。该模型基于 K2.6 架构构建,采用 1 万亿参数的混合专家(MoE)设计,拥有 320 亿激活参数及 256K 上下文窗口。 主要改进包括: * **性能增强:** 与前代产品相比,在处理现实世界中长周期编码和智能体工作流方面表现更出色。 * **效率提升:** 思维令牌(thinking-token)的使用量减少了 30%。 * **进阶能力:** 原生支持多模态输入(图像和视频),通过强制开启 `preserve_thinking` 模式实现持久化推理,并与 Kimi Code CLI 实现无缝集成。 该模型在包括编码(Kimi Code Bench v2)和智能体工具使用任务(MCP-Atlas)在内的行业基准测试中表现极具竞争力。它支持原生 INT4 量化,并兼容 vLLM 和 SGLang 等标准推理引擎。对于熟悉以往 K2.x 版本的用户而言,部署流程十分简洁。该模型及其代码库基于修改后的 MIT 许可协议发布。用户可通过 Moonshot AI 平台使用兼容 OpenAI/Anthropic 的 API 进行访问。
Moonshot AI(月之暗面)发布的开源权重编程模型 **Kimi K2.7-Code**,在 Hacker News 上引发了关于当前 AI 编程工具格局的广泛讨论。
社区的主要观点包括:
* **性能与价格**:尽管 Kimi、DeepSeek 和 Qwen 等模型提供了极具性价比且竞争力强的选择,足可替代 Anthropic 的 Claude Opus 及 OpenAI 的模型,但许多资深用户指出,顶尖模型在“推理”能力上仍具优势,特别是在多步规划和意图理解方面。
* **工作流转变**:用户正日益转向模块化工作流,利用“规划型”模型(如 Claude)进行架构设计,并使用“实现型”模型(如 DeepSeek 或 Kimi)进行代码生成,从而在不牺牲质量的前提下优化成本。
* **工具选型**:开发者们正在探讨各种“外壳”(CLI 代理)工具(如 OpenCode、Pi 和 Claude Code)的优劣。社区强烈倾向于那些支持灵活切换不同模型以匹配特定任务需求的工具。
* **地缘政治与伦理**:讨论也涉及了“国产模型”的标签问题,一些用户强调了隐私顾虑,而另一些人则认为,这些模型的开源权重特性使其比西方专有的“黑盒”替代方案更具可访问性和透明度。
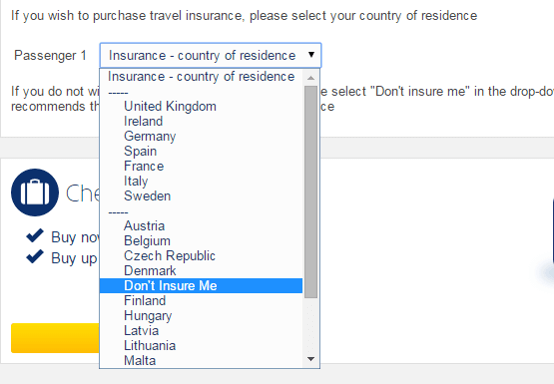 瑞安航空(Ryanair)的办理登机手续流程堪称“黑暗用户体验模式”的典范,旨在诱导用户购买不必要的附加服务。该流程包含九个不同阶段,从旅游保险、优先登机到选座和租车,航空公司会利用误导性语言或故意设置的复杂操作来施压,迫使旅客增加消费。
为了避开这些陷阱,作者建议采用一种反直觉的策略:尽量在最后一刻办理登机。拖到最后可以减少航空公司推销的机会,甚至还有可能被随机分配到出口排等更好的座位,因为位置较差的座位通常已被先行选走。相反,对于像汉莎航空这样采取传统、合理选座流程的航空公司,尽早办理登机仍是更好的选择。归根结底,想要成功实现经济出游,就需要保持警惕,并了解各家航空公司为赚取额外费用所采取的心理策略。
瑞安航空(Ryanair)的办理登机手续流程堪称“黑暗用户体验模式”的典范,旨在诱导用户购买不必要的附加服务。该流程包含九个不同阶段,从旅游保险、优先登机到选座和租车,航空公司会利用误导性语言或故意设置的复杂操作来施压,迫使旅客增加消费。
为了避开这些陷阱,作者建议采用一种反直觉的策略:尽量在最后一刻办理登机。拖到最后可以减少航空公司推销的机会,甚至还有可能被随机分配到出口排等更好的座位,因为位置较差的座位通常已被先行选走。相反,对于像汉莎航空这样采取传统、合理选座流程的航空公司,尽早办理登机仍是更好的选择。归根结底,想要成功实现经济出游,就需要保持警惕,并了解各家航空公司为赚取额外费用所采取的心理策略。
这段 Hacker News 的讨论探讨了瑞安航空(Ryanair)等廉价航空公司在预订流程中“黑暗模式”的普遍性。
**主要内容包括:**
* **商业模式:** 用户们讨论了瑞安航空激进的向上销售和具有欺骗性的用户界面究竟是“邪恶”的,还是为了实现超低票价而必须做出的权衡。支持者认为,通过这些页面“博弈”能让他们以极低的价格出行;而批评者则认为这些做法具有掠夺性,尤其是针对不精通技术的用户或老年旅客。
* **持续存在的问题:** 尽管有人称最糟糕的模式(如隐藏“不购买保险”选项)已成为过去,但用户反映目前仍存在基于恐惧的营销策略、强制下载应用程序以及令人困惑的登机口信息,这些问题可能导致昂贵的罚款。
* **第三方风险:** 许多评论者建议不要使用旅行代理商,因为它们通常提供的支持服务很差,无法转发航空公司的通知,有时甚至会出售并不存在的机票。为了获得更好的责任保障,建议直接通过航空公司预订。
* **监管背景:** 虽然一些用户呼吁更严格地执行消费者保护法,但另一些人指出,瑞安航空经常利用欧盟境内的法律漏洞或管辖权缺口,导致乘客在遇到问题时几乎求助无门。
电子邮件欺骗长期以来一直是一个难题,但随着人工智能驱动的电子邮件管理系统的兴起,身份验证变得至关重要。由于人工智能助手越来越多地自主阅读、总结并处理电子邮件,它们并不总能像人类那样察觉网络钓鱼企图的细微“破绽”。因此,验证发件人身份已不再仅仅是最佳实践,而是必不可少的基础设施。 电子邮件身份验证依赖于三个环环相扣的标准:**SPF**(授权发送服务器)、**DKIM**(提供加密签名以防止篡改)和 **DMARC**(指示服务器如何处理验证失败的情况)。这三者共同确保了邮件确实来自声称的发件人。 谷歌和雅虎等主要服务提供商现在强制要求批量发件人使用 DMARC,这标志着身份验证已被视为邮件送达的基本先决条件。虽然身份验证确认的是身份而非意图——这意味着它无法阻止所有诈骗——但它显著增加了冒充的复杂性和成本。随着我们的收件箱变得日益自动化,这些安全标准构成了必要的基石,确保未来的电子邮件在追求便捷的同时,依然保持其可信度。
链接的 Fastmail 博客文章《电子邮件的未来》在 Hacker News 上引发了激烈讨论。尽管许多用户批评该文章是缺乏实质内容的“标题党”或“公关废话”,但随后的讨论串对电子邮件基础设施和安全性的现状进行了深入探讨。
社区讨论的主要结论包括:
* **身份验证与安全:** 社区普遍认为,SPF、DKIM 和 DMARC 对于确保邮件送达率和防止欺诈已至关重要。然而,许多用户指出,这些协议常被大型组织误解或错误部署。
* **“围墙花园”问题:** 评论者担心,谷歌和雅虎等大型服务商通过设置严格的合规要求,实际上正在将互联网中心化,导致自建邮件服务器或小型服务商的运营难度日益增加。
* **人工智能与隐私:** 用户对在电子邮件中集成人工智能持谨慎态度,担心这会导致自动化的“机器人对机器人”通信,进而丧失人类的主动权。
* **用户解决方案:** 许多人推荐使用“筛选”或“白名单”机制(类似于 HEY 或自定义过滤器)来对抗垃圾邮件;另一些人则感叹,真正的端到端加密(如 GPG)对大众而言依然难以普及。
 2026 年 6 月,Arch 用户存储库(AUR)中超过 408 个软件包遭到入侵,起因是维护者账号“arojas”被劫持。攻击者向这些软件包中注入了恶意的预安装脚本,利用 `npm` 下载并执行了名为 `atomic-lockfile` 的载荷。
此次供应链攻击因其复杂性而引人注目,它同时部署了信息窃取程序和 eBPF Rootkit。该恶意 NPM 软件包与用户“herbsobering”有关联,此人还涉及其他可疑工具。
**所需操作:**
Arch Linux 用户应立即使用 [GitHub 上提供的官方脚本](https://github.com)检查系统是否受到影响。如果发现任何入侵迹象,由于系统可能存在 Rootkit,用户应将其视为不可信,保留环境以供取证分析,轮换所有存储的凭据,并考虑重装系统。有关技术细节和受影响软件包的列表,请参阅 [Ioctl.fail 分析报告](https://ioctl.fail)。
2026 年 6 月,Arch 用户存储库(AUR)中超过 408 个软件包遭到入侵,起因是维护者账号“arojas”被劫持。攻击者向这些软件包中注入了恶意的预安装脚本,利用 `npm` 下载并执行了名为 `atomic-lockfile` 的载荷。
此次供应链攻击因其复杂性而引人注目,它同时部署了信息窃取程序和 eBPF Rootkit。该恶意 NPM 软件包与用户“herbsobering”有关联,此人还涉及其他可疑工具。
**所需操作:**
Arch Linux 用户应立即使用 [GitHub 上提供的官方脚本](https://github.com)检查系统是否受到影响。如果发现任何入侵迹象,由于系统可能存在 Rootkit,用户应将其视为不可信,保留环境以供取证分析,轮换所有存储的凭据,并考虑重装系统。有关技术细节和受影响软件包的列表,请参阅 [Ioctl.fail 分析报告](https://ioctl.fail)。
最新报告指出,Arch 用户软件仓库(AUR)中的数百个软件包遭到恶意注入攻击,攻击者主要利用 `npm` 执行未授权代码。
**关键要点:**
* **受损情况:** 攻击者利用了 AUR 的“孤儿”软件包机制,该机制允许任何人接管无人维护的软件包。通过接管这些包,攻击者在构建过程中植入了恶意脚本。
* **运行模式:** AUR 是一个由社区驱动的项目,明确声明“使用风险自负”。它并非官方审计仓库;Arch 维护者建议用户在安装前手动审查每一个 `PKGBUILD` 文件和依赖链。
* **社区讨论:** 一些用户认为,在供应链攻击频发的时代,AUR 缺乏监管是一个巨大的隐患;而另一些用户则坚持认为,AUR 的初衷就是为愿意进行自我审查的用户提供社区贡献的内容。
* **缓解措施:** Arch Linux 已正式确认了此次事件。建议用户检查已安装的软件包(例如使用官方审计脚本或查看更新差异),并尽可能优先使用官方仓库而非 AUR。部分建议采用容器化或虚拟机来隔离不可信的软件。
医疗保健和大型基础设施等复杂系统常被人以愤世嫉俗的眼光看待,但它们远非“坏了”或“修好”那么简单。 在医疗领域,高昂的成本常被归咎于体制性的贪婪,但它们也反映了社会的选择,例如人们偏好顶尖的学术设施、前沿的研究以及更短的等待时间。要取得进步,可能需要做出不那么引人注目、具体务实的让步,而非对这些机构进行全面讨伐。 同样,波士顿的“大开挖”(Big Dig)等大型基础设施项目也展示了长期成功与混乱执行之间的张力。虽然这类项目常因巨大的财务和管理失误而饱受诟病,但它们确实能带来深远的城市改善。 归根结底,在复杂环境中取得成功往往就像下高级别象棋:它需要将注意力细化到大多数人忽略的“细枝末节”上。菲尔·恩(Phil Eng)领导下的波士顿马萨诸塞湾交通局(MBTA)的扭亏为盈证明了:根植于透明度、问责制以及对解决具体小问题近乎痴迷的执行力,能够打破悲观的预期。尽管世界更偏好关于反派与英雄的简单叙事,但真正的进步往往源于枯燥、细致且持之以恒的工作。
抱歉。
在一座身份不明且被遗弃的空间站紧急迫降后,一群探险者开始搜寻维修材料及失踪的船员。空间站最初被认为是一个小型中转站,但其规模却违背了所有逻辑。随着探险者穿梭于无尽且如出一辙的客运大厅和休息室,他们对空间站直径的估算呈指数级增长——从数百米跨越到数千光年。 尽管空间站建筑宏大且重复,且毫无人员踪迹,但探险队还是发现了其他旅行者留下的痕迹。他们最终断定,这座空间站不仅是一座建筑,更是一个宇宙实体;整个宇宙,包括他们自己的银河系,都存在于其内部。随着时间感和方向感的逐渐消逝,探险者放弃了最初的任务。他们对空间站产生了近乎宗教般的虔诚,认定自己的使命就是徘徊于其无限的长廊中,并坚信空间站本身就是宇宙,而他们永无止境的旅程,才是存在的唯一真谛。
关于 新闻 版权 联系我们 创作者 广告 开发者 条款 隐私 政策与安全 YouTube 的运作方式 测试新功能 © 2026 Google LLC
抱歉。
随着美国读取荷兰电子邮件,数字主权成为当务之急。 Digital Sovereignty Becomes an Imperative as the US Reads Dutch Emails
17 天前
 近期发生的微软据称向美国众议院泄露荷兰监管机构未脱敏敏感邮件的事件,凸显了数字主权的紧迫必要性。该案例表明,数据驻留——即仅将数据存储在国界之内——不足以保障控制权。由于美国服务提供商受美国法律管辖(如《云法案》),无论数据物理位置在哪里,都可能面临外国传票的风险。
荷兰的这一案例揭示了一个关键的不对称性:数字基础设施并非中立的容器,而是一种政治工具。真正的数字主权要求机构不能仅仅信任供应商的承诺,而必须确保对加密密钥、审计追踪和披露流程拥有可验证的控制权,从而确保敏感的行政和监管数据免受外国司法管辖。
对于政策制定者和IT主管而言,教训显而易见:架构必须将问责制置于便利性之上。如果一个组织无法确定谁掌握系统的“密钥”,或者无法确定谁有权强制披露其数据,那么它就缺乏真正的主权。为了防止“司法管辖权外溢”,未来的采购必须聚焦于可执行的治理,确保数字系统服务于拥有它们的机构,而非服务于托管它们的供应商。
近期发生的微软据称向美国众议院泄露荷兰监管机构未脱敏敏感邮件的事件,凸显了数字主权的紧迫必要性。该案例表明,数据驻留——即仅将数据存储在国界之内——不足以保障控制权。由于美国服务提供商受美国法律管辖(如《云法案》),无论数据物理位置在哪里,都可能面临外国传票的风险。
荷兰的这一案例揭示了一个关键的不对称性:数字基础设施并非中立的容器,而是一种政治工具。真正的数字主权要求机构不能仅仅信任供应商的承诺,而必须确保对加密密钥、审计追踪和披露流程拥有可验证的控制权,从而确保敏感的行政和监管数据免受外国司法管辖。
对于政策制定者和IT主管而言,教训显而易见:架构必须将问责制置于便利性之上。如果一个组织无法确定谁掌握系统的“密钥”,或者无法确定谁有权强制披露其数据,那么它就缺乏真正的主权。为了防止“司法管辖权外溢”,未来的采购必须聚焦于可执行的治理,确保数字系统服务于拥有它们的机构,而非服务于托管它们的供应商。
近期有披露称美国政府一直在获取荷兰的电子邮件,这在 Hacker News 上引发了关于“数字主权”的热烈讨论。
辩论的要点包括:
* **信任赤字:** 许多参与者认为,由于《云法案》(CLOUD Act)等法律的存在,依赖美国云服务商作为关键政府基础设施在本质上具有风险。有人建议,欧洲需要建立自己安全、自主的 IT 生态系统来打破这种依赖。
* **主权的负担:** 批评人士指出,“数字主权”难以实现。建立本地替代方案成本高昂,且人们担心低延迟性能以及政府是否有技术能力维护自身安全且具备竞争力的平台。
* **“陨落的神”:** 讨论在很大程度上反映了全球情绪的深刻转变。许多非美国评论者表达了一种背叛感,并指出他们心目中美国作为道德民主典范的形象,已因持续的监视行为和被感知的政治不稳定而破碎。
* **加密的作用:** 技术贡献者强调,管辖权只是问题的一部分。他们认为,真正的隐私需要端到端加密和对数据传输更好的控制,而不仅仅是将服务器迁移到另一个国家。