 UniFi 网关(包括高端型号)在处理 PPPoE 连接时存在严重的性能瓶颈。这是因为大多数 UniFi 的 SoC 缺乏对 PPPoE 的硬件加速,而 PPPoE 本质上是一个单线程进程,会极大地消耗单个 CPU 核心。因此,用户体验到的速度往往远低于其光纤额定带宽。
为了规避这一限制,ArcBox Labs 提出了一种“PPPoE 半桥”(或称 Zero IP Bridge)解决方案。通过将 PPPoE 认证卸载到辅助设备(例如运行 OpenWrt 的路由器)上,PPPoE 的开销由外部设备处理。随后,该设备通过 DHCP 将公网 IP 地址直接传递给 UniFi 网关。
ArcBox Labs 的解决方案利用 OpenWrt 的 `hotplug.d` 机制实现了该过程的自动化:OpenWrt 设备进行拨号连接、剥离 IP,并管理向后端 UniFi 网关的移交。这有效地使 UniFi 网关能够专注于路由和安全功能,而无需承受 PPPoE 处理带来的繁重 CPU 负担。使用此方法,用户可以成功实现超过 5 Gbps 的线路速度,从而克服 UniFi 当前产品系列固有的硬件限制。
UniFi 网关(包括高端型号)在处理 PPPoE 连接时存在严重的性能瓶颈。这是因为大多数 UniFi 的 SoC 缺乏对 PPPoE 的硬件加速,而 PPPoE 本质上是一个单线程进程,会极大地消耗单个 CPU 核心。因此,用户体验到的速度往往远低于其光纤额定带宽。
为了规避这一限制,ArcBox Labs 提出了一种“PPPoE 半桥”(或称 Zero IP Bridge)解决方案。通过将 PPPoE 认证卸载到辅助设备(例如运行 OpenWrt 的路由器)上,PPPoE 的开销由外部设备处理。随后,该设备通过 DHCP 将公网 IP 地址直接传递给 UniFi 网关。
ArcBox Labs 的解决方案利用 OpenWrt 的 `hotplug.d` 机制实现了该过程的自动化:OpenWrt 设备进行拨号连接、剥离 IP,并管理向后端 UniFi 网关的移交。这有效地使 UniFi 网关能够专注于路由和安全功能,而无需承受 PPPoE 处理带来的繁重 CPU 负担。使用此方法,用户可以成功实现超过 5 Gbps 的线路速度,从而克服 UniFi 当前产品系列固有的硬件限制。
每日HackerNews RSS
Hacker News
最新 | 过往 | 评论 | 提问 | 展示 | 招聘 | 提交
登录
Show HN: 我们通过 PPPoE 半桥模式解决了 UniFi 的 PPPoE 性能缓慢问题 (arcbox.dev)
6 分,由 uneven9434 发布于 1 小时前 | 隐藏 | 过往 | 收藏 | 2 条评论
帮助
cr3ative 2 分钟前 | 下一条 [–]
我一直怀疑这是可行的,但有实际演示真是太棒了。我想这对支持硬件卸载的 OpenWRT 设备来说受益最大!
回复
mono442 4 分钟前 | 上一条 [–]
我猜他们的方法确实有效,但它会导致一些有效的 IP 地址不可用。
回复
考虑申请 YC 2026 年秋季批次!申请截止日期为 7 月 27 日。
准则 | 常见问题 | 列表 | API | 安全 | 法律 | 申请 YC | 联系
搜索:
本网站正在使用安全服务来抵御在线攻击。您刚才的操作触发了安全防御机制。触发此拦截的原因可能有多种,包括提交了特定的词汇或短语、SQL 命令或格式错误的数据。
议员们目前正在质疑英国政府为何在主要的公共部门 IT 框架中继续使用富士通(Fujitsu)。
在 Hacker News 的一场讨论中,一位评论者认为,问题的根源在于缺乏可行的替代方案;英国的国内 IT 基础设施在 90 年代大体上已被富士通吸收,而其他大型供应商(如 Capita 或 Atos)也被认为存在同样的问题。
该评论者建议,解决方案是重建强大的内部技术架构团队,使其能够直接管理复杂系统。然而,这种转变面临着重大的政治和结构性障碍:
1. **长期愿景:** 政府项目往往缺乏必要的连续性。
2. **人才留任:** 在薪酬方面难以与私营部门竞争,从而难以聘用技术精湛的员工。
3. **政治问责:** 终止失败的合同在政治上具有风险,因为这往往会被归咎于政府的失职,而非供应商的失败。
归根结底,这一共识凸显了一种依赖循环:由于缺乏内部专业知识以及担心承认项目失败会带来政治后果,政府不得不锁定在与这些表现不佳的巨头签订的合同中。
![]() **PISIGuard** 是一款专注于隐私保护的浏览器扩展程序,旨在保护您在使用 ChatGPT、Claude 和 DeepSeek 等 AI 平台时的数据安全。
许多用户在不知不觉中会将姓名、电话号码、密码和 API 密钥等个人信息共享给 AI 模型。PISIGuard 通过在数据离开浏览器之前在本地自动识别并遮盖这些敏感信息来解决这一问题。它会将敏感信息替换为安全占位符,确保 AI 无法获取您的隐私细节。当 AI 回复后,该扩展会自动还原原始值,从而为您提供自然且无缝的使用体验。
主要功能包括:
* **本地处理:** 所有识别、遮盖和还原操作均完全在您的设备上完成;不会有任何数据被发送到第三方服务器。
* **隐私至上:** 不包含任何遥测、分析或后台进程。
* **兼容性:** 适用于各大主流浏览器(Chrome/Edge/Brave 和 Firefox)。
* **可配置性:** 高级用户可以自定义检测规则,以满足特定需求。
PISIGuard 在确保您的个人信息始终保密的同时,还能让您顺畅使用心仪的 AI 工具,为您带来安心的体验。
*免责声明:本软件按“原样”提供,不提供任何保证。*
**PISIGuard** 是一款专注于隐私保护的浏览器扩展程序,旨在保护您在使用 ChatGPT、Claude 和 DeepSeek 等 AI 平台时的数据安全。
许多用户在不知不觉中会将姓名、电话号码、密码和 API 密钥等个人信息共享给 AI 模型。PISIGuard 通过在数据离开浏览器之前在本地自动识别并遮盖这些敏感信息来解决这一问题。它会将敏感信息替换为安全占位符,确保 AI 无法获取您的隐私细节。当 AI 回复后,该扩展会自动还原原始值,从而为您提供自然且无缝的使用体验。
主要功能包括:
* **本地处理:** 所有识别、遮盖和还原操作均完全在您的设备上完成;不会有任何数据被发送到第三方服务器。
* **隐私至上:** 不包含任何遥测、分析或后台进程。
* **兼容性:** 适用于各大主流浏览器(Chrome/Edge/Brave 和 Firefox)。
* **可配置性:** 高级用户可以自定义检测规则,以满足特定需求。
PISIGuard 在确保您的个人信息始终保密的同时,还能让您顺畅使用心仪的 AI 工具,为您带来安心的体验。
*免责声明:本软件按“原样”提供,不提供任何保证。*
Mohamed Abdel-Maksoud 推出了 **PISIGuard**,这是一款旨在保护用户在与 AI 聊天机器人交互时,个人及敏感信息的工具。该名称意为“个人身份与敏感信息保护卫士”(Personally Identifiable & Sensitive Information Guard)。
针对 Hacker News 上的反馈,开发者澄清道,尽管目前已有企业级的“数据防泄漏”(DLP)工具,但 PISIGuard 主要填补了个人用户的使用需求。根据用户的建议,开发者更新了项目文档以明确该缩写的含义,并优化了 GitHub 的 README 布局,以提升移动端的访问体验。
在多年依靠每天四到五杯咖啡来对抗慢性疲劳后,作者决定尝试将摄入量限制在每天早晨仅喝一杯。 在经历第一天强烈的戒断反应(这揭示了作者疲劳的真实程度)之后,效果发生了彻底的改变。通过清除体内残留的咖啡因,作者打破了“因为喝咖啡而疲惫,又因为疲惫而喝咖啡”的恶性循环。 如今,作者表示睡眠质量显著提高,全天情绪稳定且头脑清晰。通过顺应自然的能量水平,而非用过量的咖啡因来掩盖疲劳,作者现在晚上能快速入睡,醒来时也感到真正恢复了活力。这一实验证实,大幅减少咖啡因摄入可以显著改善日常能量水平和睡眠质量。
Hacker News 最新 | 过往 | 评论 | 提问 | 展示 | 招聘 | 投稿 登录
少喝咖啡,睡得更好 (marginalia.nu)
5 分,由 edward 发布于 51 分钟前 | 隐藏 | 过往 | 收藏 | 2 条评论 帮助
anonzzzies 1 分钟前 | 下一条 [–]
我喝咖啡和能量饮料后会犯困。 回复
majorbugger 5 分钟前 | 上一条 [–]
对许多人来说,这可能会带来巨大的改变。但人们对咖啡因的敏感度并不相同。 回复
考虑申请 YC 2026 年秋季批次!申请截止日期为 7 月 27 日。
准则 | 常见问题 | 列表 | API | 安全 | 法律 | 申请 YC | 联系
搜索:
DMARC 常被误解为一种全面的安全过滤机制,但其实际用途非常有限:它仅用于确认电子邮件中“可见发件人”地址的域名是否已通过 SPF 或 DKIM 对齐验证。 SPF 用于验证隐藏的“信封”发件人,而 DKIM 提供加密签名。DMARC 则是确保这些验证方法与用户实际看到的地址相匹配的桥梁。它在防御精确域名仿冒方面非常有效,但并非万能的解决方案。 DMARC 不会分析邮件内容,这意味着它无法拦截伪装域名、显示名称冒充、遭入侵账户或已通过认证的恶意邮件。此外,DMARC 并非垃圾邮件过滤器,它仅负责验证来源。由于电子邮件转发等合法操作可能导致验证失败,因此在推行严格的 `p=reject` 策略时,必须经过仔细监控,以避免拦截正常的通信。 归根结底,DMARC 是一种身份验证工具,而非信任信号。它能保护您的域名身份并提供有关谁代表您发送邮件的可见性,但无法判断邮件是否安全或真实。真正的安全性要求将 DMARC 作为多层防御策略的一部分,而非将其视为单一的修复方案。
Hacker News
最新 | 过往 | 评论 | 提问 | 展示 | 招聘 | 提交
登录
DMARC 能防范什么,不能防范什么 (senderledger.com)
5 分 | 作者: adulion | 30 分钟前 | 隐藏 | 过往 | 收藏 | 讨论 | 帮助
考虑申请 YC 2026 年秋季批次!申请截止日期为 7 月 27 日。
准则 | 常见问题 | 列表 | API | 安全 | 法律 | 申请 YC | 联系
搜索:
```dependencies✖ 单个 Octane 运行时:安装了 2 个 Octane 副本 ✔ Vite 对等范围:vite 8.1.5 符合 ^8.0.16 typescript✖ JSX 导入源:未设置 jsxImportSource ⚠ 类型检查脚本:typecheck 运行的是原始 tsc ✖ 无通配符 .tsrx 声明:在 1 个文件中找到 declare module '*.tsrx' 3 个失败 · 1 个警告 · 11 个通过 `octane doctor --fix` 可以修复 2 个问题。```
Hacker News 最新 | 过往 | 评论 | 提问 | 展示 | 招聘 | 提交 登录
Octane – React 的编程模型,已编译 (octanejs.dev)
12 分,nnx 发布于 1 小时前 | 隐藏 | 过往 | 收藏 | 3 条评论 帮助
aatd86 9 分钟前 | 下一条 [–]
我认得这种对比风格。绝对是 Claude 生成的。哈哈
回复
Tajnymag 17 分钟前 | 上一条 [–]
看了性能对比表,Vue Vapor 模式的表现让我感到惊讶。
回复
purerandomness 12 分钟前 | 父评论 [–]
有趣的是,Vue Vapor 3.6 beta 和 Ripple 0.3 显示的性能与 Octane 完全相同(1.0),但它们的柱状图却长了一点点,这样 Octane 团队就可以假装有理由把自己的实现排在最上面了。
经典的统计学暗黑模式。
回复
考虑申请 YC 2026 年秋季批次!申请截止日期为 7 月 27 日。
指南 | 常见问题 | 列表 | API | 安全 | 法律 | 申请 YC | 联系
搜索:
**is.team** 于 2026 年推出,是一个人工智能原生项目管理平台。它通过一个可缩放的“无限画布”取代了 Jira 和 Asana 等碎片化工具,为用户提供统一的工作空间。这种空间化布局允许团队将看板、文档和便签并排排列,从而实时可视化跨职能的依赖关系。 该平台将 AI 视为核心成员。通过模型上下文协议(MCP),外部 AI 智能体可以订阅看板、参与实时对话并自主执行任务。内置的 AI 功能包括:根据提示自动生成看板的工作流规划器、从会议中自动提取任务的功能,以及用于对话式管理的卡片助手。 为实现无缝协作,is.team 具备实时光标、内置 WebRTC 语音通道以及全面的时间和预算跟踪功能。与传统工具不同,它不采用按席位收费的模式,而是提供无限任务数量的统一费率结构,适合自由职业者和初创企业使用。is.team 消除了嵌套菜单和复杂配置带来的负担,提供了一个高性能环境,让人员与 AI 能够在同一个持久化的画布上进行协作。
一位用户在 Hacker News 上发布了他们的新项目管理工具 *is.team*,但收到了社区的尖锐批评。
评论者指出了几个严重问题:营销文案看起来像是未经修改的通用 AI 内容,宣传视频的语气令人反感,而在饱和的市场中声称要取代 Jira 和 Slack 等行业巨头,显得缺乏可信度。此外,用户对网站上的推荐语持怀疑态度,怀疑它们并非真实,而是由 AI 生成的。
不过,反馈并不全是负面的。用户认可了该工具在专注于小型、灵活开发团队这一细分市场上的潜力,并建议开发者提供一个只读演示版以建立信任。开发者对此作出回应,确认该项目的开源版本即将推出。总体而言,社区鼓励开发者优化营销信息并注重透明度,以便在竞争激烈的项目管理领域更好地参与竞争。
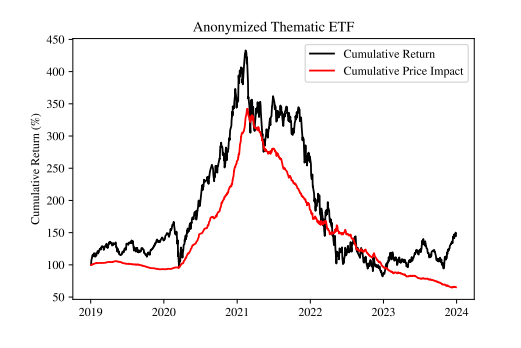 Situational Awareness (SA) 的兴衰是当前人工智能驱动的股市中的“煤矿里的金丝雀”,揭示了过度杠杆和过度集中的风险。SA 的轨迹并非一次孤立的失败,而是反映了一种反身性反馈循环:推动其股价上涨 400% 的兴奋情绪和资本流入,不可避免地导致了其剧烈的下跌。
作者认为,Citadel 最近对 SA 资产的大宗购买不应被解读为看涨信号。这很可能是一种为了空头回补或风险管理的战略举措,而非对人工智能行业的信任票。
这一现象符合乔治·索罗斯的“反身性理论”,即投资者的认知驱动资产价格,创造出一个既放大繁荣又加剧萧条的循环。随着散户和机构杠杆率的提高,市场已变得愈发脆弱。作者警告称,目前由类似未对冲、高集中度头寸主导的更广泛人工智能市场,正面临波动加剧的时期。投资者应为纳斯达克的“韩国综合股价指数化”(KOSPIfication)做好准备,其特征是随着市场从狂热转向潜在的恐慌性去杠杆周期,价格波动将变得日益极端和反复无常。
Situational Awareness (SA) 的兴衰是当前人工智能驱动的股市中的“煤矿里的金丝雀”,揭示了过度杠杆和过度集中的风险。SA 的轨迹并非一次孤立的失败,而是反映了一种反身性反馈循环:推动其股价上涨 400% 的兴奋情绪和资本流入,不可避免地导致了其剧烈的下跌。
作者认为,Citadel 最近对 SA 资产的大宗购买不应被解读为看涨信号。这很可能是一种为了空头回补或风险管理的战略举措,而非对人工智能行业的信任票。
这一现象符合乔治·索罗斯的“反身性理论”,即投资者的认知驱动资产价格,创造出一个既放大繁荣又加剧萧条的循环。随着散户和机构杠杆率的提高,市场已变得愈发脆弱。作者警告称,目前由类似未对冲、高集中度头寸主导的更广泛人工智能市场,正面临波动加剧的时期。投资者应为纳斯达克的“韩国综合股价指数化”(KOSPIfication)做好准备,其特征是随着市场从狂热转向潜在的恐慌性去杠杆周期,价格波动将变得日益极端和反复无常。
这篇 Hacker News 讨论帖探讨了股市即将出现波动的风险,重点分析了拥挤交易和高杠杆的运作机制。
参与者指出了一种反复出现的市场动态:多个基金采取相似的高杠杆策略。当市场走势与这些拥挤的头寸背道而驰时,会引发被迫抛售和剧烈清算。然而,由于投资者已经识别出这种模式,他们往往在抛售压力减弱后立即重新入场,从而导致去杠杆化和重新加杠杆的周期循环。
讨论还涉及了当前市场对人工智能资产的情绪,指出人们正在争论大型机构(如 Citadel)的干预行为究竟代表了对人工智能长期的看好,还是仅仅属于这些复杂的、由波动驱动的交易策略的一部分。
尽管人工智能无疑提高了生产力,但认为它能瞬间让工程师变成“十倍效率者”的想法是误导性的。软件开发远不止编写代码那么简单;尤其是资深工程师,他们大部分时间花在系统架构、调试、文档编制和协作上,而人工智能在这些任务中的影响仍然微乎其微。 数据表明,人工智能带来的效率提升幅度较为温和——资深工程师约为 15%,初级工程师约为 25%。与认为人工智能会取代初级人才的需求相反,初级工程师实际上从这些工具中受益最大,因为他们的工作流中包含更多人工智能最擅长处理的编码任务。 归根结底,编码仅仅是“入场券”。工程的核心在于复杂的逻辑推理、问题解决以及对模糊需求的提炼,而在这些领域,人工智能尚未成熟。领导者应调整预期:人工智能虽然是一个有价值的助手,但它目前无法取代资深员工所进行的严谨认知工作,也不能消除雇佣全能型工程师的必要性。请期待渐进式的生产力提升,而非革命性的转变。
这篇 Hacker News 的讨论探讨了“人工智能生产力差距”,重点关注 AI 智能体如何从根本上改变开发者的工作流程。
用户观察到,虽然 AI 允许同时管理多项任务,但它往往使开发者的角色从主动编码转变为被动监控。一位评论者指出,并行运行多个 AI 智能体会导致大量时间花在等待进程完成上,从而形成一种碎片化的工作模式,使他们在管理 AI 输出时难以保持高效。另一位贡献者认为,所承诺的生产力提升可能被夸大了;他指出,对于资深开发者而言,由于监管和纠错带来的额外开销,AI 辅助带来的净收益往往小于预期,甚至可能产生负面影响。
总而言之,该讨论串强调了一个转变:瓶颈已从技术实现转移到了认知负荷与管理上,并质疑 AI 究竟是真正加速了开发进程,还是仅仅改变了浪费时间的方式。
 从 C/C++ 迁移到 Rust 已不再是实验性概念,而是提升内存安全、可维护性和性能的战略举措。然而,迁移是否成功取决于其商业价值——这通常适用于涉及复杂并发、安全关键组件或高性能需求的系统。
专家建议采取**增量迁移**策略,而非风险极高的全面重写。具体包括:
* **建立信心:** 从独立的、低依赖的“叶子”模块开始,让团队在处理核心逻辑前,先解决集成障碍(构建系统、FFI、测试等)。
* **管理复杂性:** 虽然“垂直切片”能更快展示商业价值,但它们通常需要复杂的 FFI(外部函数接口)层。“由叶入核”的方法对于长期重构来说通常更为整洁。
* **处理 FFI:** 跨语言边界需要对内存所有权和分配制定严格规则,因为当 Rust 与 C/C++ 交互时,编译器提供的安全保证会减弱。
归根结底,迁移是一项长期工程,而非简单的代码替换。通过增量迁移到 Rust,团队可以在保持生产系统稳定运行的同时,保留现有技术积累、降低缺陷率并稳步优化代码库。
从 C/C++ 迁移到 Rust 已不再是实验性概念,而是提升内存安全、可维护性和性能的战略举措。然而,迁移是否成功取决于其商业价值——这通常适用于涉及复杂并发、安全关键组件或高性能需求的系统。
专家建议采取**增量迁移**策略,而非风险极高的全面重写。具体包括:
* **建立信心:** 从独立的、低依赖的“叶子”模块开始,让团队在处理核心逻辑前,先解决集成障碍(构建系统、FFI、测试等)。
* **管理复杂性:** 虽然“垂直切片”能更快展示商业价值,但它们通常需要复杂的 FFI(外部函数接口)层。“由叶入核”的方法对于长期重构来说通常更为整洁。
* **处理 FFI:** 跨语言边界需要对内存所有权和分配制定严格规则,因为当 Rust 与 C/C++ 交互时,编译器提供的安全保证会减弱。
归根结底,迁移是一项长期工程,而非简单的代码替换。通过增量迁移到 Rust,团队可以在保持生产系统稳定运行的同时,保留现有技术积累、降低缺陷率并稳步优化代码库。
Hacker News
最新 | 过往 | 评论 | 提问 | 展示 | 招聘 | 提交
登录
你如何将 C/C++ 项目重写为 Rust? (jetbrains.com)
4 点,由 smokeeaasd 发布于 1 小时前 | 隐藏 | 过往 | 收藏 | 2 条评论
帮助
himata4113 3 分钟前 | 下一条 [–]
我曾见过有人为了性能用 Rust 重写 WireGuard 代理,却没意识到那只不过是一个与内核交互以设置路由的守护进程……不过嘿,至少密钥生成变快了!
回复
keybored 5 分钟前 | 上一条 [–]
> 你如何将 C/C++ 项目重写为 Rust?
> 用 AI?
> 免责声明:本文在 AI 的协助下创作,并由 JetBrains RustRover 团队审核。
看来我不会知道了。
回复
考虑申请 YC 2026 年秋季批次!申请截止日期为 7 月 27 日。
指导原则 | 常见问题 | 列表 | API | 安全 | 法律 | 申请 YC | 联系
搜索: