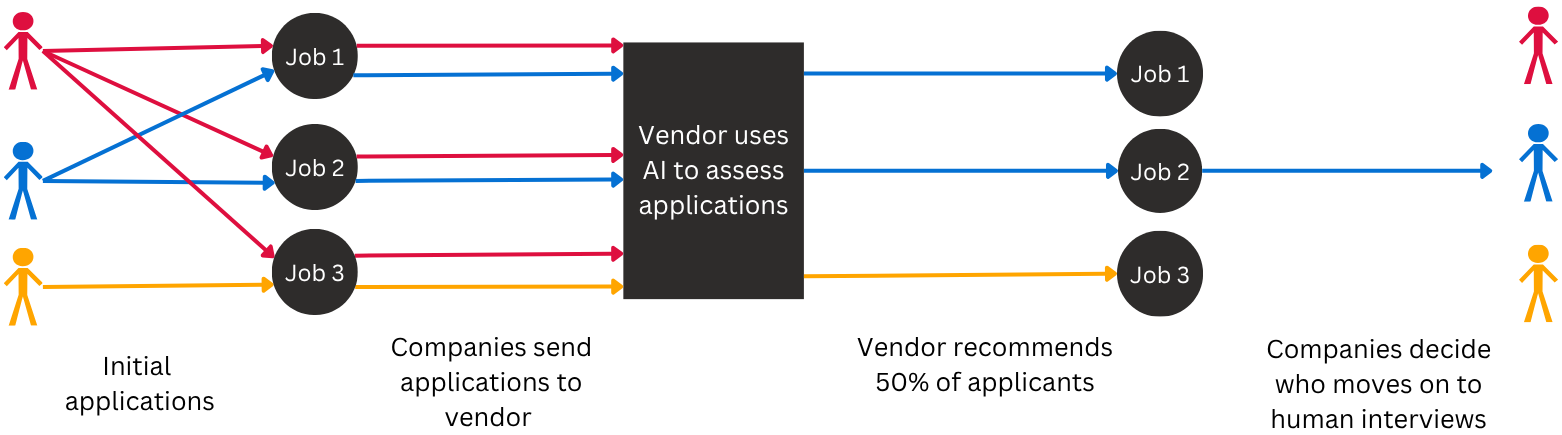
 一项针对 340 万求职者的大规模研究表明,“算法单一文化”——即广泛依赖少数几家相同的 AI 招聘供应商——正在造成系统性的就业障碍。研究人员通过分析 156 家雇主的 400 万份申请发现,这些算法产生了显著的种族差异,而这种差异往往被传统的汇总数据分析所掩盖。
主要发现包括:
* **隐性负面影响:** 按照美国《民权法案》第七章的要求,在对单个职位进行分析时,可以发现明显的歧视模式,尤其是针对黑人和亚裔申请人。
* **系统性拒绝:** 对单一供应商的依赖导致了“系统性拒绝”,即申请人在多个职位中被不成比例地拒绝。这种结果的高度同质化远超统计学常态,表明中心化的 AI 模型限制了就业机会。
* **研究壁垒:** 数据的不透明性阻碍了对这些高风险系统的独立监管。
作者认为,当前的法规尚显不足。他们建议决策者强制要求进行职位层面的负面影响审计,监督算法依赖风险,并改善独立研究人员的数据访问权限,以确保自动化招聘过程中的问责制。
一项针对 340 万求职者的大规模研究表明,“算法单一文化”——即广泛依赖少数几家相同的 AI 招聘供应商——正在造成系统性的就业障碍。研究人员通过分析 156 家雇主的 400 万份申请发现,这些算法产生了显著的种族差异,而这种差异往往被传统的汇总数据分析所掩盖。
主要发现包括:
* **隐性负面影响:** 按照美国《民权法案》第七章的要求,在对单个职位进行分析时,可以发现明显的歧视模式,尤其是针对黑人和亚裔申请人。
* **系统性拒绝:** 对单一供应商的依赖导致了“系统性拒绝”,即申请人在多个职位中被不成比例地拒绝。这种结果的高度同质化远超统计学常态,表明中心化的 AI 模型限制了就业机会。
* **研究壁垒:** 数据的不透明性阻碍了对这些高风险系统的独立监管。
作者认为,当前的法规尚显不足。他们建议决策者强制要求进行职位层面的负面影响审计,监督算法依赖风险,并改善独立研究人员的数据访问权限,以确保自动化招聘过程中的问责制。
每日HackerNews RSS
对不起。
请启用 JavaScript 和 Cookie 以继续。
抱歉。
 软件系统很少在一开始就变得复杂而混乱。它们是随着时间推移,通过一次次增量变更而逐渐演变成这样的。起初简单的功能(如用户注册或订单处理),不可避免地会演变成一系列相互关联的任务,涉及队列、后台作业、第三方集成和条件逻辑。
虽然这些单独的改动通常是合理的,但它们最终会累积成“隐藏的工作流”。当这些流程埋没在分散的代码中时,系统将变得难以维护。团队会因此陷入困境,因为改动往往伴随着不可预见的风险,调试时需要拼凑多个服务的日志,而组织内部的经验往往取代了清晰的文档。这削弱了开发者的信心,并使系统显得脆弱不堪。
解决之道并非消除复杂性,而是使其“可见”。通过承认系统正在运行编排流程,你可以将这些协调逻辑从零散的处理程序中剥离出来,转入集中且明确的工作流中。像 Unmeshed 这类工具允许团队在一个地方定义这些序列,从而更易于监控、调试和演进。归根结底,工作流是增长的自然产物;我们的目标是不再将其隐藏在“粘合代码”中,而是将其作为架构中的核心要素来管理。
软件系统很少在一开始就变得复杂而混乱。它们是随着时间推移,通过一次次增量变更而逐渐演变成这样的。起初简单的功能(如用户注册或订单处理),不可避免地会演变成一系列相互关联的任务,涉及队列、后台作业、第三方集成和条件逻辑。
虽然这些单独的改动通常是合理的,但它们最终会累积成“隐藏的工作流”。当这些流程埋没在分散的代码中时,系统将变得难以维护。团队会因此陷入困境,因为改动往往伴随着不可预见的风险,调试时需要拼凑多个服务的日志,而组织内部的经验往往取代了清晰的文档。这削弱了开发者的信心,并使系统显得脆弱不堪。
解决之道并非消除复杂性,而是使其“可见”。通过承认系统正在运行编排流程,你可以将这些协调逻辑从零散的处理程序中剥离出来,转入集中且明确的工作流中。像 Unmeshed 这类工具允许团队在一个地方定义这些序列,从而更易于监控、调试和演进。归根结底,工作流是增长的自然产物;我们的目标是不再将其隐藏在“粘合代码”中,而是将其作为架构中的核心要素来管理。
请提供您需要翻译的内容。
最近一篇关于 DeepSeek V4 Pro 在精度上超越 GPT-5.5 Pro 的 Hacker News 文章引发了关于 AI 生成内容及大语言模型基准测试有效性的激烈辩论。
批评者认为该文章是“AI 生成的标题党”,并指出其仅凭四项实验的方法论非常薄弱、构建粗糙,缺乏科学比较所需的严谨性。许多用户质疑该测试使用 AI 模型(Grok)作为裁判的做法,以及缺乏多轮测试以排除模型非确定性行为的影响。
相反,支持者则强调,DeepSeek V4 Pro 及类似模型代表了向高性价比、高性能替代方案的必要转型,挑战了西方“前沿”模型的地位。用户指出,尽管 GPT-5.5 可能在“宏观”推理或处理复杂、模糊的任务上仍具优势,但 DeepSeek 极高的成本效益、出色的 Token 缓存能力,以及在配合结构化代码框架使用时的有效性,使其成为实际开发中的“游戏规则改变者”。
归根结底,这场讨论突显了日益加剧的分歧:一部分人认为 AI 基准测试已沦为充斥着垃圾信息的无效劳动,而另一部分人则将廉价、开源权重模型的崛起视为对少数高价闭源公司垄断地位的必要冲击。
周一凌晨,菲律宾南部城市桑托斯将军市附近发生7.8级地震,该地区随即发布了海啸预警。此次地震震源深度为10公里,造成了电力中断和建筑物结构受损,其中包括一栋四层办公楼的部分坍塌。 当局已向沿海居民发出紧急撤离令,警告菲律宾境内可能出现高达3米的海啸,印度尼西亚、马来西亚及西太平洋其他地区也可能出现较小的海啸。目前尚无人员伤亡报告,但该地区随后发生了多次强余震,其中一次震级为6.5级。 菲律宾位于太平洋“火环”地带,极易受到地震和火山活动的影响。紧急救援小组目前正在评估灾情,由于地震发生在凌晨,商业建筑内人员较少,因此减少了人员受伤的情况。目前,夏威夷没有受到海啸威胁。
抱歉。
这是一款专业刻录机,专为实时制作音质卓越的原版播放唱片而设计。该机器仅通过我们的合作伙伴——模拟媒体大师 SUPERSENSE 独家提供。我们共同的愿景是让每一位希望将音乐或声音制作成实体唱片的人都能实现这一愿望。目前,该机器仅少量生产。如需获取该机器,请通过电子邮件联系我们。
 Manticore Search 引入了“提前终止”(early termination)机制来优化其 HNSW 向量搜索,在保持高精度的同时显著降低了查询延迟。
HNSW 搜索往往会在结果集趋于稳定后继续遍历图结构,从而浪费计算资源。Manticore 的新算法通过监控“发现率”——即遍历过程中找到更优候选点的频率——来解决这一问题。一旦该频率在一定轮次内低于自适应的分位数阈值,搜索即告结束。
这种方法对于较大的结果集(k > 10)非常有效,可在精度损失极小(通常为 2%–4%)的情况下,将距离计算量减少 50% 到 80%。在高并发负载下,该优势更为显著:通过减少内存流量和缓存抖动,提前终止机制带来的延迟改善几乎可以达到单线程基准测试的两倍。
该功能默认开启,可与量化和过采样等现有优化手段无缝协作。对于追求绝对最大召回率的应用场景或特定的基准测试需求,该功能也可以手动关闭。总而言之,提前终止提供了一种智能且自适应的方法来消除冗余的图遍历,从而实现更快、更高效的向量搜索性能。
Manticore Search 引入了“提前终止”(early termination)机制来优化其 HNSW 向量搜索,在保持高精度的同时显著降低了查询延迟。
HNSW 搜索往往会在结果集趋于稳定后继续遍历图结构,从而浪费计算资源。Manticore 的新算法通过监控“发现率”——即遍历过程中找到更优候选点的频率——来解决这一问题。一旦该频率在一定轮次内低于自适应的分位数阈值,搜索即告结束。
这种方法对于较大的结果集(k > 10)非常有效,可在精度损失极小(通常为 2%–4%)的情况下,将距离计算量减少 50% 到 80%。在高并发负载下,该优势更为显著:通过减少内存流量和缓存抖动,提前终止机制带来的延迟改善几乎可以达到单线程基准测试的两倍。
该功能默认开启,可与量化和过采样等现有优化手段无缝协作。对于追求绝对最大召回率的应用场景或特定的基准测试需求,该功能也可以手动关闭。总而言之,提前终止提供了一种智能且自适应的方法来消除冗余的图遍历,从而实现更快、更高效的向量搜索性能。
本仓库提供了一系列适用于 **Raspberry Pi Pico 2 (RP2350)** 的 Rust 示例,利用 **Embassy 异步框架**实现高效、非阻塞的硬件交互。
这些示例展示了多种外设接口及项目实现:
* **传感器:** 涵盖了 **HS3003** (I2C)、**ADXL345** 加速度计 (I2C)、**DS18B20** 温度探头 (1-Wire) 和 **DHT11** (数字协议) 的数据采集。注意,对时间敏感的传感器使用了自定义且周期精确的 `PreciseDelay` 实现。
* **显示屏:** 包含 Adafruit 2.2 英寸 TFT LCD 接口,其中一个复杂示例展示了如何利用物理引擎渲染动画雪花,并使用 DMA 实现高性能、非阻塞的显示更新。
* **物联网与连接:** 展示了适用于 Pico 2 W 的 **Matter 兼容 Wi-Fi 灯泡**,支持通过 BLE 配网和 Wi-Fi,实现与 Apple Home、Google Home 和 Home Assistant 等生态系统的安全集成。
* **实用程序:** 包含标准的 GPIO 闪灯示例。
这些项目充分利用了 RP2350 的双核架构,展示了如何在嵌入式 Rust 中管理复杂的时序和异步任务。所有项目均可使用提供的 [pico2-template](https://github.com/ImplFerris/pico2-template.git) 轻松引导启动。
抱歉。
请启用 JavaScript 并关闭广告拦截器
抱歉。
感知机是现代神经网络的基本构建单元。它受到生物神经元的启发,通过一个简单的数学公式处理输入,从而做出二元决策:`若 (权重 * 输入 + 偏置) > 0,则输出 1,否则输出 0`。 “权重”决定了输入的重要性,而“偏置”则起到阈值的作用,允许机器调整决策边界以适配数据。在训练过程中,感知机通过反复遍历数据(轮次)进行学习,并在出错时调整权重和偏置。“学习率”控制着每次修正时这些数值改变的幅度。 一个关键的最佳实践是“归一化”,即将输入缩放到统一的范围。这可以防止较大的数值主导其他输入,并确保学习过程平稳且高效。 虽然单个感知机只能画出一条直线来分割数据,但它却是复杂人工智能的重要基石。当这些简单的单元堆叠成层时,它们就会演变成能够解决复杂非线性问题的精细神经网络。本质上,每一个先进的 AI 模型都建立在这一相同的基本机制之上:权重、偏置和学习循环。
抱歉。