**zeroserve** 是一款高性能、零配置的 HTTPS 服务器,旨在替代 Nginx 和 Caddy 等工具。它直接从单个不可变的压缩包(tarball)提供网站服务,并利用 `io_uring` 处理所有 I/O 操作,从而实现卓越的速度和效率。 主要创新点包括: * **程序即配置**:用户无需使用复杂的声明式文件,而是将 eBPF 程序嵌入到压缩包中。这些脚本在用户空间沙盒中运行并即时编译(JIT)为原生代码,用于处理包括路由、身份验证、速率限制和反向代理在内的所有请求逻辑。 * **卓越性能**:在单核基准测试中,zeroserve 在提供小型静态文件和处理代理 API 请求方面的表现始终优于 Nginx 和 Caddy。 * **操作简便**:该服务器支持原子化部署——只需替换压缩包并发送 `SIGHUP` 信号,即可在不中断连接的情况下热重载网站、脚本和 TLS 证书。 * **现代安全性**:原生支持 TLS 1.3、加密客户端问候(ECH)以及 JA4 指纹识别。 通过将请求处理和配置集成到一个可脚本化的事件循环中,zeroserve 为现代 Web 服务提供了一种统一、易读且高效的解决方案。
每日HackerNews RSS
Zeroserve:一个可使用 eBPF 脚本编写的零配置 Web 服务器 Zeroserve: A zero-config web server you can script with eBPF
27 天前
Hacker News 社区正在讨论 **Zeroserve**,这是一款利用 eBPF 技术提升性能的新型“零配置”Web 服务器。该项目旨在通过简化配置并提供高速静态文件服务(包括直接从单个未压缩的 tarball 中提供文件),来挑战 Nginx 和 Caddy 等老牌服务器。
**讨论要点:**
* **性能与信任:** 初步基准测试显示,Zeroserve 在小文件延迟和吞吐量方面优于 Nginx 和 Caddy。然而,许多用户对此持怀疑态度,认为 Nginx 等成熟项目的安全性、强化程度和长期维护价值远高于微小的性能提升。
* **“AI 生成”的争议:** 该项目在开发过程中对大语言模型(LLM)的依赖引发了批评。一些评论者将其斥为“AI 垃圾”,担心这种“靠感觉编码”的软件缺乏严谨的工程实践。另一些人则为作者辩护,指出代码结构良好,且大语言模型如今已是加速开发的有效工具。
* **设计理念:** 围绕“配置与代码”的争论随之产生。虽然 Zeroserve 旨在用脚本取代声明式配置,但批评者认为,行业标准更倾向于配置文件所具备的可预测性和简洁性,而非嵌入式脚本。
从决策树到扩散模型及逆向过程:决策树与扩散模型的统一 Trees to Flows and Back: Unifying Decision Trees and Diffusion Models
27 天前
在《Trees to Flows and Back》一文中,作者 Sai Niranjan Ramachandran 和 Suvrit Sra 弥合了两个看似无关范式之间的鸿沟:层次化决策树与连续扩散模型。该论文建立了这两类模型之间的形式化数学对应关系,揭示出两者均受名为“全局轨迹分数匹配”(GTSM)的共同优化原则支配。通过该框架,作者论证了理想化的梯度提升是这些模型的一种渐进最优方法。 这一理论统一带来了两项重要的实际应用: 1. **TreeFlow**:一种用于表格数据的生成模型,在提升保真度的同时实现了 2 倍的计算加速。 2. **DSMTree**:一种蒸馏技术,可有效地将层次化决策逻辑迁移至神经网络中,在多个基准测试中均能稳定地达到教师模型性能的 98% 以上。 通过证明决策树与扩散过程是同一事物的两个侧面,该研究为增强表格数据生成和模型可解释性提供了一个强有力的新视角。
抱歉。
在沙盒中使用 MicroPython 和 WASM 运行 Python 代码 Running Python code in a sandbox with MicroPython and WASM
27 天前
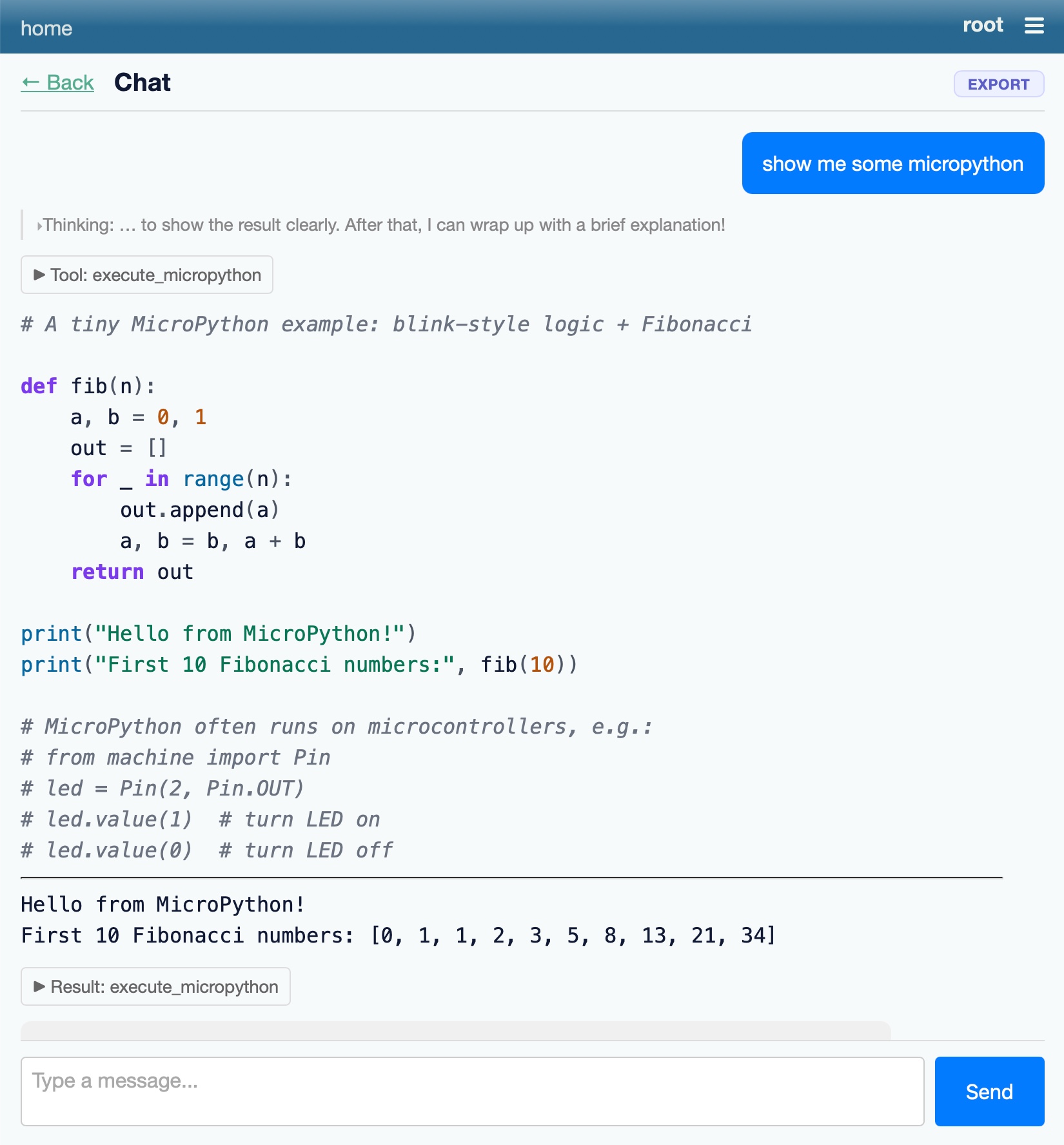 软件开发者 Simon Willison 发布了 `micropython-wasm`,这是一个处于 Alpha 阶段的库,旨在为在大型应用程序中执行不受信任的 Python 代码提供一个安全、隔离的沙箱环境。
Willison 强调,对于像 Datasette 和 LLM 这样的项目,沙箱环境是必不可少的,这样可以在不影响系统稳定性、文件完整性或网络安全的前提下,实现功能强大且可扩展的插件系统。在发现现有的 Python 沙箱解决方案不可靠或维护不善后,他转向了 WebAssembly (WASM)。
通过利用 `wasmtime` 库和一个自定义编译的 MicroPython 版本,Willison 创建了一个稳健的沙箱,它提供了内存/CPU 限制、受限的文件系统访问,以及选择性公开宿主函数的能力。一个关键的突破是在多次调用之间保持了持久的解释器状态,从而支持复杂的多步代码执行。
尽管目前该工具仍处于 Alpha 阶段,但已可通过 PyPI 获取,并与 Datasette 生态系统集成。Willison 承认新沙箱固有的风险,但他希望这一原型能够鼓励专业安全团队进一步开发和标准化 Python-in-WASM 解决方案,以实现生产级的沙箱环境。
软件开发者 Simon Willison 发布了 `micropython-wasm`,这是一个处于 Alpha 阶段的库,旨在为在大型应用程序中执行不受信任的 Python 代码提供一个安全、隔离的沙箱环境。
Willison 强调,对于像 Datasette 和 LLM 这样的项目,沙箱环境是必不可少的,这样可以在不影响系统稳定性、文件完整性或网络安全的前提下,实现功能强大且可扩展的插件系统。在发现现有的 Python 沙箱解决方案不可靠或维护不善后,他转向了 WebAssembly (WASM)。
通过利用 `wasmtime` 库和一个自定义编译的 MicroPython 版本,Willison 创建了一个稳健的沙箱,它提供了内存/CPU 限制、受限的文件系统访问,以及选择性公开宿主函数的能力。一个关键的突破是在多次调用之间保持了持久的解释器状态,从而支持复杂的多步代码执行。
尽管目前该工具仍处于 Alpha 阶段,但已可通过 PyPI 获取,并与 Datasette 生态系统集成。Willison 承认新沙箱固有的风险,但他希望这一原型能够鼓励专业安全团队进一步开发和标准化 Python-in-WASM 解决方案,以实现生产级的沙箱环境。
英格兰及威尔士警方被要求停止在法庭陈述中使用人工智能。 Police in England and Wales told to halt AI use in court statements
27 天前

抱歉。
**Splash** 是一种简单且易于阅读的色彩格式,它使用 3 位数字来表示 RGB 通道,每个数字的范围从 0 到 9。例如,900 代表纯红,000 代表黑色,999 代表白色。 作为一种情感化工具,Splash 通过提供仅 1,000 种颜色的有限选择来帮助创作者克服选择困难,消除寻找“完美”色调的压力。它具有高度灵活性:你可以通过将 0–9 映射到 0–255 来通过数学方式生成颜色,也可以使用查找表来定义自定义的品牌色板。 由于该格式避免了字母和复杂的语法,它在代码中非常易于实现——无论是通过简单的函数、CSS 变量还是预设的样式表。该系统旨在实现“顺滑”与易用,鼓励实验而非追求完美。通过限制选择,Splash 使设计过程更快、性能更高,并最终带来更多的自由。
关于“Splash”(一种自定义颜色格式)的 Hacker News 讨论,核心在于技术实用性与创作意图之间的争论。
作者设计 Splash——一套使用十进制数值来表示 RGB 通道的系统——是为了克服“选择困难症”,以及在数百万种颜色中挑选时所产生的“无谓纠结”。通过将选项限制在一个更易于管理且量化的调色板中,作者旨在简化应用程序开发与设计中的颜色选择流程。
评论者的观点两极分化。许多技术用户质疑这种新格式的必要性,认为标准的 3 位十六进制代码(#ABC)已经广为应用、支持广泛且效率更高。其他人则建议,HSV、HCL 等颜色模型,甚至基于物理混色的类比,都比基于 RGB 的系统能提供更直观的配色逻辑。
作者为该项目辩护称,这是一种“情感工具”而非技术突破,并强调该系统旨在为其特定的使用场景提供简洁性与乐趣。归根结底,这篇讨论凸显了两种观点之间的冲突:一方透过行业标准的视角看待颜色编码,另一方则优先考虑定制化、以人为本的工作流程。
 本项目提供了一套轻量级、与渲染器无关的实时抖动物理标准,在简单的布娃娃系统与复杂的软体模拟之间找到了平衡点。通过使用 UV 映射权重绘制和阻尼弹簧骨骼,开发者可以定义出能随父级运动而真实抖动的柔软区域。
**核心组件:**
* **`jiggle-physics.js`**:纯粹的模拟引擎,基于父级的速度和加速度计算阻尼弹簧偏移量。它与渲染器无关,不需要 DOM 或 WebGL,可轻松集成到任何游戏循环中。
* **变形逻辑**:采用简单的通用公式 `vertex += weight * boneJiggle` 来驱动运动,从而实现局部的“肉体回弹”以及挤压和拉伸效果。
* **资源标准**:使用 UV 映射的权重纹理来定义柔软度(0–1)和骨骼分配。这种方法性能极高,每个顶点仅需一次纹理查找。
随附的 WebGL 演示(`jiggle-app.js` 和 `index.html`)展示了该系统的实际运行效果,其中包含用于绘制权重、调整物理参数(刚度、阻尼、重力)以及测试各种几何体的工具。该系统专为广泛的可移植性而设计;任何支持基础向量数学的引擎均可实现此标准。
本项目提供了一套轻量级、与渲染器无关的实时抖动物理标准,在简单的布娃娃系统与复杂的软体模拟之间找到了平衡点。通过使用 UV 映射权重绘制和阻尼弹簧骨骼,开发者可以定义出能随父级运动而真实抖动的柔软区域。
**核心组件:**
* **`jiggle-physics.js`**:纯粹的模拟引擎,基于父级的速度和加速度计算阻尼弹簧偏移量。它与渲染器无关,不需要 DOM 或 WebGL,可轻松集成到任何游戏循环中。
* **变形逻辑**:采用简单的通用公式 `vertex += weight * boneJiggle` 来驱动运动,从而实现局部的“肉体回弹”以及挤压和拉伸效果。
* **资源标准**:使用 UV 映射的权重纹理来定义柔软度(0–1)和骨骼分配。这种方法性能极高,每个顶点仅需一次纹理查找。
随附的 WebGL 演示(`jiggle-app.js` 和 `index.html`)展示了该系统的实际运行效果,其中包含用于绘制权重、调整物理参数(刚度、阻尼、重力)以及测试各种几何体的工具。该系统专为广泛的可移植性而设计;任何支持基础向量数学的引擎均可实现此标准。
抱歉。
Linux 内核开发者李晨(Li Chen)最近提出了“孵化模板”(spawn templates),旨在优化传统的 `fork()` 和 `exec()` 进程创建模式。虽然 `fork()` 在历史上被认为是优雅的,但由于它需要复制整个进程状态,而其中大部分工作随后又会被 `exec()` 丢弃,因此其计算成本很高。李晨的提案旨在通过允许应用程序将可执行配置缓存为模板来加速这一过程,从而降低频繁重复命令的设置成本。 尽管该提案显示出 2% 的性能提升,但内核维护者最终拒绝了其当前的形式。像 Mateusz Guzik 这样的审查者认为,业界需要完全摒弃 `fork()` 惯用法,转而创建“纯净”的进程。Christian Brauner 建议使用 `pidfd` 抽象采用替代方法——即创建一个空进程并通过新的系统调用(类似于 `fsconfig()`)进行配置。 李晨认同这一方向,将重心转向开发更稳健、原生的 `posix_spawn()` 实现。这一转变表明,虽然“孵化模板”不会被实现,但它成功催化了 Linux 迈向更简洁、更高效的进程创建 API 的进程。
所提供的文本探讨了围绕 Unix `fork()` 和 `exec()` 系统调用模式的争论,最近一篇 LWN 文章指出 `fork()` 是一种已经过时且不再实用的“黑客”手段,该观点引发了热议。
**主要论点包括:**
* **历史背景:** `fork()` 设计于 20 世纪 70 年代,旨在满足当时内存极其有限的系统需求,允许程序将内存交换到磁盘并执行新代码。批评者认为,该模型现已成为一种负担,迫使操作系统设计陷入僵化且低效的模式(例如对写时复制和内存超额分配的过度依赖)。
* **现代性能问题:** 对于大型进程(如服务器应用程序或 Redis 等高内存负载程序),由于 `fork()` 必须遍历并复制庞大的页表(即使有写时复制优化),会导致显著的延迟峰值。
* **拟议替代方案:** 参与者建议转向“创建、配置、执行”(spawn, configure, exec)模型,即新进程在空状态下创建,从而避免复制父进程带来的开销。
* **反方观点:** 支持现状的人士强调,`fork()` 在概念上简单、优雅,且在 shell 管道处理和进程编排方面具有高度灵活性。许多人认为,目前所谓的“现代”替代方案往往更为复杂,且无法完全解决进程配置中的细微问题。
请启用 JavaScript 并关闭广告拦截器
美国众议院发布了一份草案,旨在禁止各州制定本州的人工智能法规。该提案在 Hacker News 上引发了激烈讨论,核心争议在于联邦优先权与“州权”之间的矛盾。
支持者认为,各州互不兼容的法律体系会为开发者创造无法实施的监管环境,而人工智能作为一种跨州技术,应由统一的联邦框架进行管理。相反,批评者则将该法案视为绕过地方民主控制的手段,主张各州和县应有权为了公共安全、数据隐私和社区土地利用等问题对人工智能进行监管。
许多评论者认为“州权”言论虚伪,指出各政治派别往往只在符合自身利益时才会援引这一原则。讨论还涉及了宪法中的商业条款、企业游说对联邦政策的潜在影响,并将其与网络中立性等以往的监管斗争进行了类比。最终,参与者对于“权力集中是防止法律混乱,还是仅仅为了牺牲地方社区利益以造福大型科技公司”这一问题各执一词。
关于 媒体报道 版权 联系我们 创作者 广告 开发者 条款 隐私 政策与安全 YouTube 的运作方式 测试新功能 © 2026 Google LLC