 ## Qwen3.5-397B-A17B 在 MacBook Pro 上的 24 小时成果
研究人员成功地在配备 48GB 内存的 MacBook Pro 上运行了大型 Qwen3.5-397B-A17B(3970 亿参数)混合专家模型,实现了 4.4+ token/秒的运行速度,并输出了高质量的结果,包括工具调用。 这仅用纯 C/Metal 推理引擎在 24 小时内完成,绕过了 Python 和传统框架。
209GB 的模型从 SSD 流式传输,利用定制的 Metal 计算流水线并“信任操作系统”进行缓存(达到 71% 的命中率)。 关键优化包括 FMA 优化的去量化内核(+12% 速度)和手工调整的 Metal 着色器。 虽然 2 位量化提供了更快的速度,但它损害了 JSON/工具调用的可靠性,因此 4 位成为首选配置。
该项目优先考虑高效的内存管理,仅使用约 6GB 的内存并按需流式传输专家权重。 重要的是,团队发现重叠的 SSD DMA 和 GPU 计算*降低*了性能,原因是内存控制器争用,因此选择串行流水线。 代码总计约 8200 行,已公开可用,展示了低级别优化的卓越成就。
## Qwen3.5-397B-A17B 在 MacBook Pro 上的 24 小时成果
研究人员成功地在配备 48GB 内存的 MacBook Pro 上运行了大型 Qwen3.5-397B-A17B(3970 亿参数)混合专家模型,实现了 4.4+ token/秒的运行速度,并输出了高质量的结果,包括工具调用。 这仅用纯 C/Metal 推理引擎在 24 小时内完成,绕过了 Python 和传统框架。
209GB 的模型从 SSD 流式传输,利用定制的 Metal 计算流水线并“信任操作系统”进行缓存(达到 71% 的命中率)。 关键优化包括 FMA 优化的去量化内核(+12% 速度)和手工调整的 Metal 着色器。 虽然 2 位量化提供了更快的速度,但它损害了 JSON/工具调用的可靠性,因此 4 位成为首选配置。
该项目优先考虑高效的内存管理,仅使用约 6GB 的内存并按需流式传输专家权重。 重要的是,团队发现重叠的 SSD DMA 和 GPU 计算*降低*了性能,原因是内存控制器争用,因此选择串行流水线。 代码总计约 8200 行,已公开可用,展示了低级别优化的卓越成就。
每日HackerNews RSS
## Flash-MoE:在笔记本电脑上运行397B参数模型 - 摘要
这个Hacker News讨论围绕一个项目,该项目使用一种名为Flash-MoE的技术,成功地在笔记本电脑上运行了Qwen 3.5 397B参数语言模型。核心成就是从SSD流式传输模型,并利用定制的Metal计算着色器进行处理。
虽然令人印象深刻,但性能约为每秒4.4个token,一些用户认为这对于实际使用来说太慢了。讨论强调,实现这一点需要大量的硬件(高端Macbook Pro),并且涉及权衡,例如4位量化,这可能会影响输出质量。
讨论了使用更低位量化(2位)或减少激活专家数量等替代方案,并对性能和输出连贯性严重下降表示担忧。 许多评论者分享了他们使用不同量化级别和硬件配置运行Qwen 3.5的经验,并指出4位量化通常能在速度和质量之间提供更好的平衡。
对话还涉及SSD磨损的可能性、更大RAM容量的好处,以及在消费级硬件与专用服务器基础设施上运行大型模型的更广泛影响。
展示HN:Oku – 一键过滤订阅源和内容噪音
Show HN: Oku – One tab to filter out noise from feeds and content sources
45 天前
## Oku:以您喜欢的方式保持信息更新 Oku 是一款可定制的信息仪表盘,提供免费和付费方案。**免费方案**提供一个仪表盘,最多可包含六个面板,提供来自 Reddit、YouTube、RSS 订阅等的信息每日摘要。 **付费方案(Start & Pro)**解锁更高的限制、所有面板类型和文章摘要。**Start** 提供 3 个仪表盘和 30 个面板,而 **Pro** 提供无限访问权限,以及 Reddit 帖子和 YouTube 视频的摘要,以及优先体验新功能。 Oku 还允许您保存文章以供稍后阅读,并提供高亮和笔记功能,以及专门用于新闻通讯的收件箱。独特的“网站监控”功能可以可视化地跟踪关键网页的变化。所有仪表盘默认设置为私有,订阅可以轻松取消。
## Oku:整理你的在线体验的工具
Oku (oku.io) 是一款旨在对抗信息过载并提高在线效率的新工具。它由一位对广告、垃圾信息和频繁切换标签页感到沮丧的用户创建,允许用户从各种信息源(包括 Hacker News、Reddit、Product Hunt 和 RSS)中整理干净、有组织的内容看板,并以网格、专注视图或电子邮件摘要的形式查看。
其目标是提供精简的体验,减少干扰,并确保用户不会错过重要内容。创建者正在积极寻求反馈,并计划添加诸如无需注册的公共看板,以及预设内容类别(例如:金融、科技等)等功能,以解决用户最初对需要登录的担忧。一些评论员指出 Oku 与较早的服务 Netvibes 相似,并强调现有的浏览器功能,如阅读模式,作为替代方案。
🛡️ 快速验证 我们正在检查您的连接以防止自动化滥用 为什么我看到这个? 有问题吗?联系客服
## Proba-3 飞船重新连接后恢复运行
欧洲的 Proba-3 任务,一个测试精确飞船对准的独特项目,在出现问题后已成功重新连接。该任务涉及两艘飞船协同工作——一艘遮挡太阳光,为另一艘创造人造日食进行研究。维持毫米级的轨道编排精度至关重要,因为这项技术对未来的任务至关重要。
最初,飞船开始翻滚,但在恢复太阳能后恢复了稳定。该任务是对复杂机动的测试,太阳观测方面是次要效益。
Hacker News 的讨论还涉及移动设备的广告拦截解决方案,以及标题中使用“欧洲”与“欧洲航天局”的争论,一些人认为应使用精确的语言以避免歧义。多名用户分享了 iPhone 上的广告拦截器资源。
 ## 25年的鸡蛋数据:AI驱动的深度分析
作者出于长期以来的爱好,成功使用AI编码代理(Codex和Claude)从11,345张收据中提取了25年的鸡蛋购买数据。这个为期14天的项目,花费约1,591美元的token,展示了结合使用专业AI模型的强大力量。
最初的挑战包括破译褪色的热敏打印以及解决旧扫描件的“白色阴影”问题,最终通过Meta的SAM3进行图像分割解决。项目进行中,Tesseract OCR被PaddleOCR-VL取代,以获得更清晰的文本提取。结构化数据提取最初尝试使用正则表达式,但效果不佳,随后由Codex处理,利用其巨大的token容量。
一个定制的LLM分类器,经过手工标注数据的训练,在识别鸡蛋购买方面实现了99%以上的准确率。该项目强调了AI辅助数据清洗的迭代性质——每个识别出的错误都允许代理提高整个数据集的准确性。最终,作者记录了购买了8,604个鸡蛋的数据,总价为1,972美元,证明即使是看似简单的数据,在合适的工具和方法下也能揭示出有趣的信息。
## 25年的鸡蛋数据:AI驱动的深度分析
作者出于长期以来的爱好,成功使用AI编码代理(Codex和Claude)从11,345张收据中提取了25年的鸡蛋购买数据。这个为期14天的项目,花费约1,591美元的token,展示了结合使用专业AI模型的强大力量。
最初的挑战包括破译褪色的热敏打印以及解决旧扫描件的“白色阴影”问题,最终通过Meta的SAM3进行图像分割解决。项目进行中,Tesseract OCR被PaddleOCR-VL取代,以获得更清晰的文本提取。结构化数据提取最初尝试使用正则表达式,但效果不佳,随后由Codex处理,利用其巨大的token容量。
一个定制的LLM分类器,经过手工标注数据的训练,在识别鸡蛋购买方面实现了99%以上的准确率。该项目强调了AI辅助数据清洗的迭代性质——每个识别出的错误都允许代理提高整个数据集的准确性。最终,作者记录了购买了8,604个鸡蛋的数据,总价为1,972美元,证明即使是看似简单的数据,在合适的工具和方法下也能揭示出有趣的信息。
## 25年的鸡蛋:一次AI数据分析
一篇近期文章详细介绍了一个利用AI,特别是Codex和Claude等LLM分析25年鸡蛋价格的项目。作者扫描了超过11,000张收据,最终专注于大约589张包含鸡蛋购买的收据,总共花费1,972美元购买了8,604个鸡蛋。
该项目出人意料地昂贵——代币成本约为1,591美元——引发了评论员对效率的质疑,与人工转录(估计费用101美元)或Gemini 3.0 Flash等替代OCR解决方案相比。许多人强调了更具针对性的传统机器学习方法在收据分类和数据提取等任务中的潜力。
讨论的中心是LLM在这种类型工作中的可扩展性和成本效益,一些人认为价值不在于最终数据,而在于LLM自主构建和完善数据管道的能力。另一些人则指出了禽流感和私募股权对鸡蛋价格的影响等外部因素。最终,该项目引发了关于AI现状、其潜力以及我们是否已在数据处理领域实现真正“工业化”的争论。
霍尔木兹扫雷 - □ × 000 准备好开始赢吧!!! 左键点击显示。右键点击标记。地雷只会在水域生成。
## Yawn:一个“永远v1”前端库 一个最近的认识促成了Yawn的想法:前端响应式自2018年以来就已存在,通过Async Iterables实现!与其不断学习新的框架特定响应式系统(useState、refs、Signals等),Yawn利用了这一内置的Web平台特性。这旨在对抗“JavaScript疲劳”——无休止地采用和重新学习前端工具的循环。 Yawn 提出了一个最小的API(约2个函数,1个类),镜像Web标准,承诺一个不会改变的库。它利用标准的HTML属性和事件监听器,响应式由Async Iterables驱动。核心组件是用于管理响应式数据的`State`类。 该项目目前是一个概念验证 (<https://github.com/SacDeNoeuds/yawn>),拥有极小的体积(2.6kB gzip压缩后),并提供诸如延迟求值、与现有迭代器辅助工具的兼容性以及与后端流直接集成的潜力等优势。 作者寻求社区支持——如果GitHub仓库达到5,000颗星,则目标是向生产就绪推进。目标是构建一个基于持久Web基础的库,提供稳定且熟悉的发展体验。
对不起。
## HopTab:一款新的macOS应用切换器和平铺工具
Royalbhati发布了HopTab,一款免费且开源的macOS应用程序,旨在取代标准的Cmd+Tab应用切换器并提供高级窗口管理。许多从Windows切换到macOS的用户常常觉得macOS的窗口管理功能不足,HopTab通过诸如全局平铺快捷键(Ctrl+Opt+箭头键用于分割成一半、四分之一、三分之一)和撤销捕捉的功能来解决这个问题。
它建立在现有的工具(如Rectangle和AltTab)之上,将应用切换、平铺和工作区管理整合到一个应用程序中。与AltTab不同,HopTab允许固定特定应用程序;与Rectangle不同,它将平铺功能与配置文件和布局集成。
用户称赞其精致和潜力,并有人建议增加付费支持层级。讨论中强调需要改进之处,例如考虑Space(虚拟桌面)的窗口过滤、自定义布局以及更好地处理多显示器设置。 许多用户也提到了Divvy、Ice/Thaw和Hammerspoon等具有类似功能的替代方案。
**更多信息请访问:** [https://www.royalbhati.com/hoptab](https://www.royalbhati.com/hoptab) & [https://github.com/royalbhati/HopTab](https://github.com/royalbhati/HopTab)
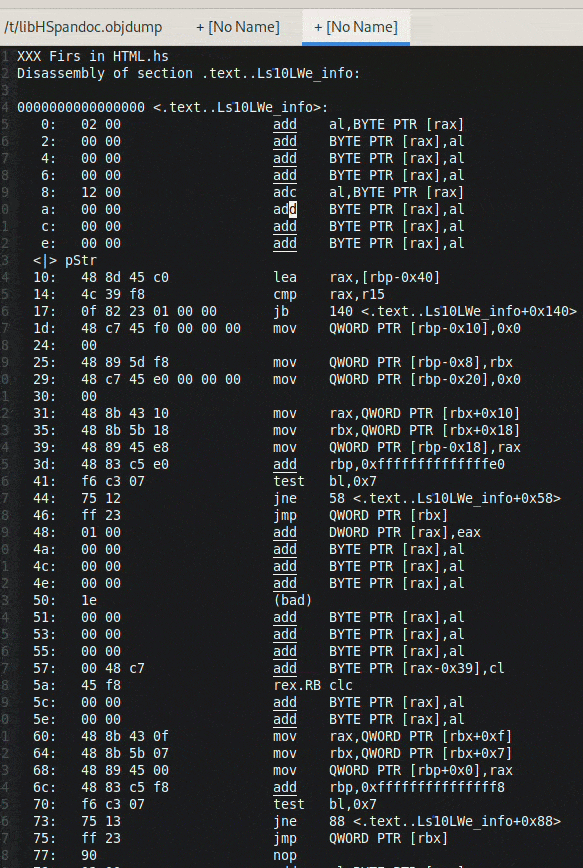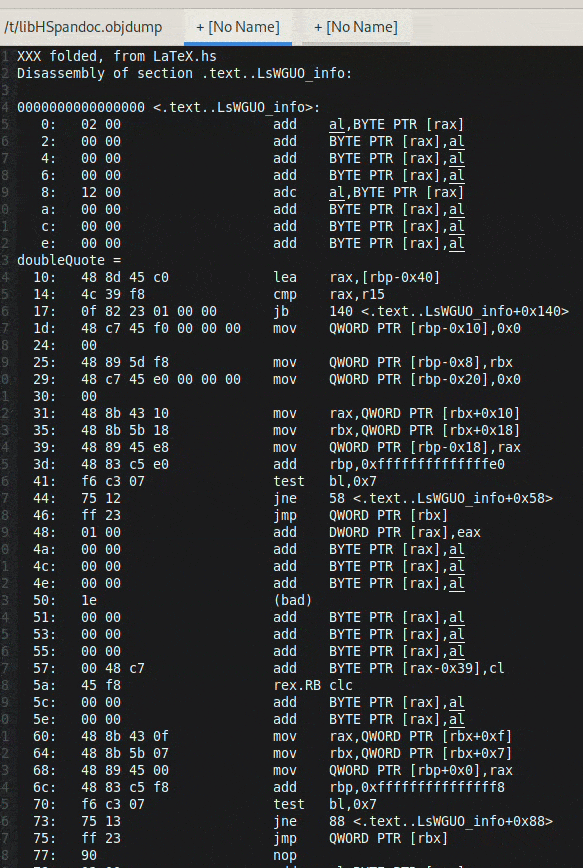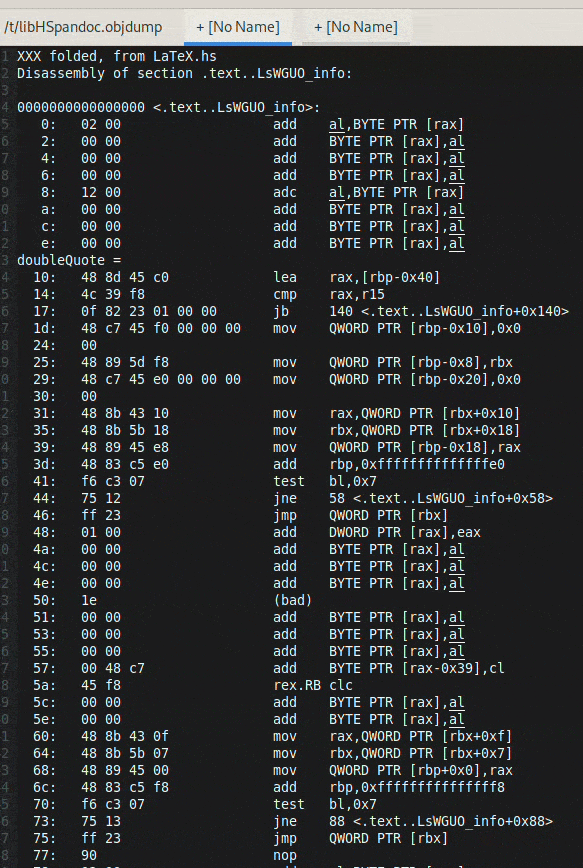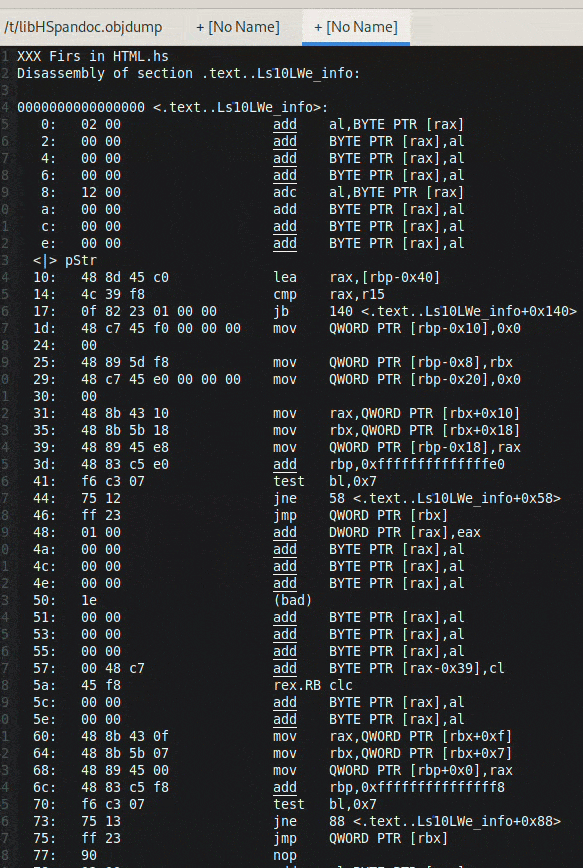 ## 减小 Haskell 二进制文件大小:链接与代码折叠
Haskell 二进制文件由于传递依赖性可能出乎意料地很大。本文探讨了在链接时减小它们大小的技术,并以 `pandoc` 项目为例进行演示。
提出了两种主要策略。首先,使用 GHC 选项 `-split-sections` 和 `--gc-sections`(通过 `-fuse-ld=lld` 使用 `lld` 作为链接器)可以将二进制文件大小减少 27%,从而实现死代码移除。
更具实验性的是,使用 `lld` 的*相同代码折叠* (ICF) 可以进一步缩小二进制文件(在本例中减少了另外 23%)。ICF 识别并合并功能上等效的代码段。虽然有效,但 ICF 并非完全安全,可能会导致依赖于特定函数地址的 C 代码出现问题。
分析表明 Haskell 项目内部存在大量代码重复,表明在编译过程中存在优化的潜力——缓存编译单元以避免重复工作。尝试了 `bloaty` 和 `kcov` 等工具进行进一步分析,但证明与 Haskell 代码不兼容。
作者还指出 ICF 与调试工具(如 `-fdistinct-constructor-tables`)之间可能存在交互,需要仔细考虑以保留调试信息。
## 减小 Haskell 二进制文件大小:链接与代码折叠
Haskell 二进制文件由于传递依赖性可能出乎意料地很大。本文探讨了在链接时减小它们大小的技术,并以 `pandoc` 项目为例进行演示。
提出了两种主要策略。首先,使用 GHC 选项 `-split-sections` 和 `--gc-sections`(通过 `-fuse-ld=lld` 使用 `lld` 作为链接器)可以将二进制文件大小减少 27%,从而实现死代码移除。
更具实验性的是,使用 `lld` 的*相同代码折叠* (ICF) 可以进一步缩小二进制文件(在本例中减少了另外 23%)。ICF 识别并合并功能上等效的代码段。虽然有效,但 ICF 并非完全安全,可能会导致依赖于特定函数地址的 C 代码出现问题。
分析表明 Haskell 项目内部存在大量代码重复,表明在编译过程中存在优化的潜力——缓存编译单元以避免重复工作。尝试了 `bloaty` 和 `kcov` 等工具进行进一步分析,但证明与 Haskell 代码不兼容。
作者还指出 ICF 与调试工具(如 `-fdistinct-constructor-tables`)之间可能存在交互,需要仔细考虑以保留调试信息。
对不起。
这篇预印本报告了一种可重复的跨模型行为收敛现象:前沿语言模型在面对本体上为空的概念时,会选择性地不继续生成内容。在重复试验中,GPT-5.2和Claude Opus 4.6对于核心空概念提示返回确定的空输出,而对于对照组提示则正常响应,显示了一个共同的边界,即未经授权的继续生成不会发生。该论文展示了跨模型复制、token预算独立性、部分对抗鲁棒性,以及在明确允许沉默的情况下边界扩展,同时将语义具身效应与普通的指令遵循或拒绝区分开来。这项贡献是一个公开的黑盒产物:收敛的、可检查的证据表明,某些语义条件会终止跨独立前沿系统的继续生成。
## Hacker News 讨论摘要:“跨模型虚无收敛”
Hacker News 上一篇帖子讨论了一篇论文(可在 zenodo.org 上找到),该论文探讨了大型语言模型(LLM),如 GPT-5.2 和 Claude Opus 4.6,在被要求扮演“虚无”或沉默时,持续返回空输出的现象。
讨论迅速从论文声称的“确定性沉默”转向了潜在的解释,这些解释根植于这些模型*实际*的工作方式。许多评论员认为这种行为并不令人惊讶,将其归因于预处理层、令牌限制,或模型被优化为简洁的响应。 几个人指出,超过令牌限制会导致空输出,并且模型可能会为了效率而优先考虑更短的响应。
对于论文的框架和术语存在怀疑,一些人将其称为“伪科学”,并认为该发现——LLM 可以输出空内容——是微不足道的。 另一些人指出,该研究侧重于 temperature=0 的 API 调用,这可能会限制观察到的收敛的意义。 作者已经发表了多篇关于此主题的类似论文,这进一步引发了对研究新颖性的质疑。
鼠王
Rat King
45 天前
 ## 鼠王:一种罕见现象
“鼠王”是一种罕见且令人不安的现象,即老鼠(通常是黑鼠)的尾巴被缠绕在一起——纠缠在毛发、树液甚至冻结的排泄物等材料中。自16世纪以来就有历史记录,这个术语并非来自动物本身,而是最初用于贬低那些剥削他人的人,后来则指坐在尾巴宝座上的国王。
虽然目击事件很少,但最近的发现——包括2021年在爱沙尼亚发现的13只活鼠组成的鼠王——证实这是一种自然但极其罕见的现象。大多数博物馆标本来自欧洲,其中最大的是在德国发现的32只木乃伊鼠组成的集合。
目前的主流理论认为,老鼠在狭窄的空间里睡觉时会被缠绕在一起,尤其是在冬季,粘性物质会使结固化。尽管存在争议,并且有人对较老的标本的真实性表示怀疑,但这种现象并不局限于老鼠;类似的“松鼠王”也被观察到。鼠王激发了人们的想象力,出现在文学、电子游戏,甚至启发了音乐标题。
## 鼠王:一种罕见现象
“鼠王”是一种罕见且令人不安的现象,即老鼠(通常是黑鼠)的尾巴被缠绕在一起——纠缠在毛发、树液甚至冻结的排泄物等材料中。自16世纪以来就有历史记录,这个术语并非来自动物本身,而是最初用于贬低那些剥削他人的人,后来则指坐在尾巴宝座上的国王。
虽然目击事件很少,但最近的发现——包括2021年在爱沙尼亚发现的13只活鼠组成的鼠王——证实这是一种自然但极其罕见的现象。大多数博物馆标本来自欧洲,其中最大的是在德国发现的32只木乃伊鼠组成的集合。
目前的主流理论认为,老鼠在狭窄的空间里睡觉时会被缠绕在一起,尤其是在冬季,粘性物质会使结固化。尽管存在争议,并且有人对较老的标本的真实性表示怀疑,但这种现象并不局限于老鼠;类似的“松鼠王”也被观察到。鼠王激发了人们的想象力,出现在文学、电子游戏,甚至启发了音乐标题。
对不起。