Anthropic 在发布其“Fable”模型后正面临审查。该模型是其“Mythos”人工智能的一个版本,而 Anthropic 此前曾认定 Mythos 为一种危险的网络武器。尽管 Anthropic 曾倡导对 Mythos 进行严格监管,但一位受信任的合作伙伴近期发现了一个可以绕过 Fable 安全护栏的越狱漏洞。 美国政府要求 Anthropic 要么修复此漏洞,要么将该模型下架。Anthropic 拒绝了这一要求,并公开称该越狱漏洞无关紧要。美国政府认为这是一个重大的安全风险,随即便对该模型实施了出口管制。 这一应对措施与其既定的“人工智能安全”品牌形象形成了鲜明对比。政府官员对该公司拒绝处理其此前承认至关重要的安全漏洞感到不解。政府表示仍重视 Anthropic 的技术能力,并希望问题能尽快解决。在安全隐患消除之前,出口管制将持续有效,这也明确了 Anthropic 必须将安全置于商业部署之上的责任。
每日HackerNews RSS
抱歉。
请提供您需要翻译的内容。
 本文是介绍 Emacs 实用、冷门且“开箱即用”功能的系列文章的第三篇,旨在为资深用户提供参考。文章特意避开了热门插件,专注于那些几乎无需配置、学习曲线平缓的内置功能。
文中重点介绍了以下特性:
* **词典与搜索:** 使用 `dictionary-tooltip-mode` 即时查看释义,利用 `ffap-menu` 列出缓冲区内的所有文件路径或 URL。
* **文件管理:** 在 `find-file` 和 `dired` 中使用通配符进行批量操作,以及利用 `dired-compare-directories` 进行高级的文件级比对。
* **差异比对与追踪:** 使用 `compare-windows` 进行简单的并排文本差异比对,通过 `highlight-changes-mode` 可视化修改内容。
* **生产力工具:** `ruler-mode` 用于视觉布局调整,`refill-mode` 用于自动段落换行,`emacs-lock-mode` 用于防止误删缓冲区。
* **导航与定制:** 扩展 `apropos` 系列命令以更轻松地发现功能,使用 `find-function-on-key` 直接跳转到函数源码。
作者强调,虽然这些工具较为冷门,但它们无需外部依赖即可显著提升工作流效率,这也证明了只要深入挖掘,Emacs 的内置库依然蕴含着惊人的潜力。
本文是介绍 Emacs 实用、冷门且“开箱即用”功能的系列文章的第三篇,旨在为资深用户提供参考。文章特意避开了热门插件,专注于那些几乎无需配置、学习曲线平缓的内置功能。
文中重点介绍了以下特性:
* **词典与搜索:** 使用 `dictionary-tooltip-mode` 即时查看释义,利用 `ffap-menu` 列出缓冲区内的所有文件路径或 URL。
* **文件管理:** 在 `find-file` 和 `dired` 中使用通配符进行批量操作,以及利用 `dired-compare-directories` 进行高级的文件级比对。
* **差异比对与追踪:** 使用 `compare-windows` 进行简单的并排文本差异比对,通过 `highlight-changes-mode` 可视化修改内容。
* **生产力工具:** `ruler-mode` 用于视觉布局调整,`refill-mode` 用于自动段落换行,`emacs-lock-mode` 用于防止误删缓冲区。
* **导航与定制:** 扩展 `apropos` 系列命令以更轻松地发现功能,使用 `find-function-on-key` 直接跳转到函数源码。
作者强调,虽然这些工具较为冷门,但它们无需外部依赖即可显著提升工作流效率,这也证明了只要深入挖掘,Emacs 的内置库依然蕴含着惊人的潜力。
这场 Hacker News 讨论探讨了 Emacs 持久的魅力、复杂性及其持续演进的过程。
贡献者们认为,Emacs 不仅仅是一个文本编辑器,更是一个深度可扩展的平台——一个能够根据用户特定需求进行塑造的 Lisp 解释器。虽然资深用户赞赏 `org-mode`、`magit` 以及卓越的文本处理能力等功能,但新手往往面临着陡峭的学习曲线。
讨论的很大一部分集中在“内置电池”式的发行版(如 Doom 或 Spacemacs)与“原生(vanilla)”设置之间的稳定性之争。许多用户指出,复杂的第三方框架在更新时容易出现故障,因此一些人主张构建自定义配置以确保长期的可靠性。
对话还强调了 Emacs 与人工智能的交集。一些高级用户正成功地集成大语言模型(通过 `gptel` 等工具)来排除故障、自动化操作并重构其配置。尽管有人认为这种做法容易产生幻觉,但另一些人则认为,通过 AI 代理来“驾驶” Emacs 实例是生产力的一次变革性飞跃。归根结底,用户们一致认为,虽然 Emacs 可能并不适合所有人,但其在内省和个人定制方面的能力依然无与伦比。
《塞罗托雷峰简史:最具争议的山峰(2012)》 A short history of Cerro Torre, the most controversial mountain (2012)
11 天前
 托雷峰(Cerro Torre)是一座海拔 3,128 米的山峰,坐落于智利与阿根廷边境,至今仍是世界上最具争议的山峰。其历史因意大利登山家切萨雷·马埃斯特里(Cesare Maestri)而蒙上阴影,他声称于 1959 年首次登顶,但这一说法广受质疑。1970 年,马埃斯特里重返此地,开辟了“压缩机路线”(Compressor Route),他使用汽油动力钻机安装了数百个永久性岩钉,此举被纯粹主义者斥为“从未来手中窃取山峰”。
2012 年,随着美国登山家海登·肯尼迪(Hayden Kennedy)和贾森·克鲁克(Jason Kruk)在无需岩钉的情况下快速登顶,并在下山途中拆除了马埃斯特里留下的 125 个岩钉,这场辩论达到了白热化。他们的单方面行动引发了全球愤慨,并点燃了关于登山“公平手段”的激烈争论:这些路线究竟应作为历史遗迹予以保留,还是应通过“解放”来恢复山峰最初的挑战难度。
批评者认为,拆除行为是傲慢的破坏,限制了技术较弱登山者的进入机会;而支持者则将其视为恢复道德纯洁性的无私之举。这场争议凸显了登山伦理的主观性。如今,托雷峰已被随后的自由攀登壮举进一步“解放”,其留给后世的遗产正如其锯齿状的岩壁一样,复杂且充满争议。
托雷峰(Cerro Torre)是一座海拔 3,128 米的山峰,坐落于智利与阿根廷边境,至今仍是世界上最具争议的山峰。其历史因意大利登山家切萨雷·马埃斯特里(Cesare Maestri)而蒙上阴影,他声称于 1959 年首次登顶,但这一说法广受质疑。1970 年,马埃斯特里重返此地,开辟了“压缩机路线”(Compressor Route),他使用汽油动力钻机安装了数百个永久性岩钉,此举被纯粹主义者斥为“从未来手中窃取山峰”。
2012 年,随着美国登山家海登·肯尼迪(Hayden Kennedy)和贾森·克鲁克(Jason Kruk)在无需岩钉的情况下快速登顶,并在下山途中拆除了马埃斯特里留下的 125 个岩钉,这场辩论达到了白热化。他们的单方面行动引发了全球愤慨,并点燃了关于登山“公平手段”的激烈争论:这些路线究竟应作为历史遗迹予以保留,还是应通过“解放”来恢复山峰最初的挑战难度。
批评者认为,拆除行为是傲慢的破坏,限制了技术较弱登山者的进入机会;而支持者则将其视为恢复道德纯洁性的无私之举。这场争议凸显了登山伦理的主观性。如今,托雷峰已被随后的自由攀登壮举进一步“解放”,其留给后世的遗产正如其锯齿状的岩壁一样,复杂且充满争议。
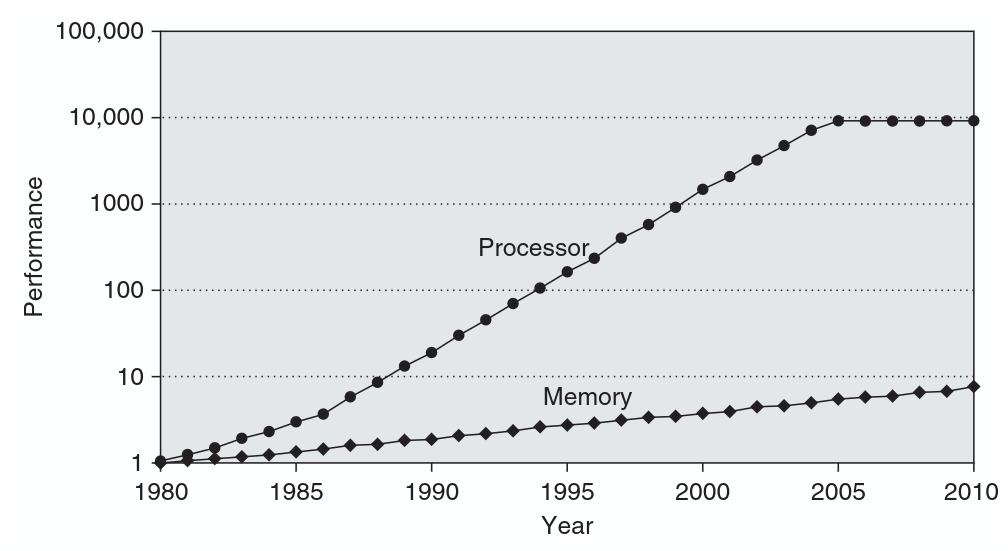 现代 CPU 每秒能执行数十亿次运算,但程序运行速度往往慢得惊人,这是因为受到了“内存墙”(Memory Wall)的限制。虽然处理器的速度呈指数级增长,但 DRAM 的延迟却始终是一个重大瓶颈,从而导致了巨大的性能鸿沟。
现代硬件试图通过使用高速缓存层级(L1、L2、L3)来缓解这一问题。这些缓存以 64 字节为单位获取数据,预设的前提是:如果你需要某段数据,很可能也会需要它相邻的数据(即空间局部性)。
作者使用一个名为 *Aletheia* 的自定义框架发现,在 64 字节的间隔处存在一个显著的性能“悬崖”。当程序在内存中跳跃(即“跨度”)超过 64 字节时,每一次访问都会导致缓存缺失,迫使 CPU 在等待缓慢的 DRAM 时陷入停顿。
这说明了“屋顶模型”(Roofline Model):程序要么受限于计算能力,要么受限于内存带宽。大多数运行缓慢的软件并非受限于计算速度,而是受限于数据访问模式。为了优化性能,开发者必须停止思考如何加快计算,而应开始关注如何更高效地移动数据,并将“工作集”保持在缓存之内。
现代 CPU 每秒能执行数十亿次运算,但程序运行速度往往慢得惊人,这是因为受到了“内存墙”(Memory Wall)的限制。虽然处理器的速度呈指数级增长,但 DRAM 的延迟却始终是一个重大瓶颈,从而导致了巨大的性能鸿沟。
现代硬件试图通过使用高速缓存层级(L1、L2、L3)来缓解这一问题。这些缓存以 64 字节为单位获取数据,预设的前提是:如果你需要某段数据,很可能也会需要它相邻的数据(即空间局部性)。
作者使用一个名为 *Aletheia* 的自定义框架发现,在 64 字节的间隔处存在一个显著的性能“悬崖”。当程序在内存中跳跃(即“跨度”)超过 64 字节时,每一次访问都会导致缓存缺失,迫使 CPU 在等待缓慢的 DRAM 时陷入停顿。
这说明了“屋顶模型”(Roofline Model):程序要么受限于计算能力,要么受限于内存带宽。大多数运行缓慢的软件并非受限于计算速度,而是受限于数据访问模式。为了优化性能,开发者必须停止思考如何加快计算,而应开始关注如何更高效地移动数据,并将“工作集”保持在缓存之内。
抱歉。
蓝美牛肝菌属(*Lanmaoa*)是一类全球分布的牛肝菌,目前正因其神秘的致幻作用而备受科学界关注。其中,在中国云南被称为“见手青”的亚洲蓝美牛肝菌(*Lanmaoa asiatica*)尤为出名,食用者常会产生“小人国幻觉”,即看到微小的、跳舞的小人。 尽管它作为一种美味佳肴深受欢迎,但这些致幻事件仍是一个重大的健康隐忧。犹他大学最近的基因组研究终于完成了对该属的测序,正式确认了 17 个物种,并厘清了它们的演化史。然而,这项研究得出了一个惊人的发现:亚洲蓝美牛肝菌并不含有任何已知的致幻标记物。基因组和化学分析均未发现裸盖菇素、鹅膏蕈氨酸,或其他任何与幻觉相关的已知化合物。 这一谜团仍未解开,因为导致这些普遍且一致的视觉幻觉的具体化学途径尚未被确定。如果得到证实,这将代表第三类完全独特的致幻真菌,有别于裸盖菇属和鹅膏菌属,从而从根本上挑战我们目前对真菌药理学和神经化学的认知。
 “分布式计算的八大谬论”是关于网络行为的长期误解,这些误解持续挑战着开发者和管理员。该列表最初由 Sun Microsystems 的工程师(包括 Bill Joy、Tom Lyon、L. Peter Deutsch 和 James Gosling)编制,是构建健壮网络软件的重要指南。
这八大谬论为:
1. **网络是可靠的:** 数据包经常丢失;协议必须考虑到这一点。
2. **延迟为零:** 延迟和抖动是固有的,需要使用缓冲等技术。
3. **带宽是无限的:** 有限的容量会导致拥塞和排队。
4. **网络是安全的:** 隐私无法得到保证,因此加密至关重要。
5. **拓扑结构不会改变:** 路径变化会导致不稳定,协议必须掩盖这些变化。
6. **只有一名管理员:** 现代网络涉及复杂的多方管理。
7. **传输成本为零:** 数据传输会产生高昂的基础设施和运营费用。
8. **网络是同构的:** 节点在速度、可靠性和容量上存在巨大差异。
通过内化这些谬论,工程师可以更好地设计出能够处理现实网络不稳定性的协议,从而确保应用程序在底层基础设施复杂的情况下,依然保持弹性、高效和安全。
“分布式计算的八大谬论”是关于网络行为的长期误解,这些误解持续挑战着开发者和管理员。该列表最初由 Sun Microsystems 的工程师(包括 Bill Joy、Tom Lyon、L. Peter Deutsch 和 James Gosling)编制,是构建健壮网络软件的重要指南。
这八大谬论为:
1. **网络是可靠的:** 数据包经常丢失;协议必须考虑到这一点。
2. **延迟为零:** 延迟和抖动是固有的,需要使用缓冲等技术。
3. **带宽是无限的:** 有限的容量会导致拥塞和排队。
4. **网络是安全的:** 隐私无法得到保证,因此加密至关重要。
5. **拓扑结构不会改变:** 路径变化会导致不稳定,协议必须掩盖这些变化。
6. **只有一名管理员:** 现代网络涉及复杂的多方管理。
7. **传输成本为零:** 数据传输会产生高昂的基础设施和运营费用。
8. **网络是同构的:** 节点在速度、可靠性和容量上存在巨大差异。
通过内化这些谬论,工程师可以更好地设计出能够处理现实网络不稳定性的协议,从而确保应用程序在底层基础设施复杂的情况下,依然保持弹性、高效和安全。
 尽管微软正在推进旨在改善用户体验和重建信任的“Windows K2”计划,但该公司在 Windows 11 设置过程中强制要求使用微软账户的立场依然坚定。这一政策持续引发用户不满,近期的讨论显示,用户强烈要求恢复原生的、简便的本地账户选项。
虽然微软辩称该政策是出于安全必要——即确保 BitLocker 恢复密钥得到备份,以防永久性数据丢失,但核心问题在于用户感觉失去了自主权。许多用户并非在寻找变通方法,而是在呼吁透明度以及管理设备方式的选择自由。批评者认为,在未明确解释自动加密等功能的影响下强制要求绑定账户,会使非技术用户面临被锁在自己数据之外的风险。即便有报道称微软内部也存在不同声音,表明该政策颇具争议,但该公司至今未显露任何妥协迹象。归根结底,这场争论凸显了一个持续存在的脱节:用户想要选择权,而微软则优先考虑一个将控制权隐藏在强制云整合之后的标准化生态系统。
尽管微软正在推进旨在改善用户体验和重建信任的“Windows K2”计划,但该公司在 Windows 11 设置过程中强制要求使用微软账户的立场依然坚定。这一政策持续引发用户不满,近期的讨论显示,用户强烈要求恢复原生的、简便的本地账户选项。
虽然微软辩称该政策是出于安全必要——即确保 BitLocker 恢复密钥得到备份,以防永久性数据丢失,但核心问题在于用户感觉失去了自主权。许多用户并非在寻找变通方法,而是在呼吁透明度以及管理设备方式的选择自由。批评者认为,在未明确解释自动加密等功能的影响下强制要求绑定账户,会使非技术用户面临被锁在自己数据之外的风险。即便有报道称微软内部也存在不同声音,表明该政策颇具争议,但该公司至今未显露任何妥协迹象。归根结底,这场争论凸显了一个持续存在的脱节:用户想要选择权,而微软则优先考虑一个将控制权隐藏在强制云整合之后的标准化生态系统。
位元 Bitsy
11 天前
欢迎来到 Bitsy 的世界! ~ 一个制作小游戏、小世界与小故事的微型引擎 ~ 开始 制作游戏 | 游玩游戏 学习 阅读文档 | 加入论坛 更多 Bitsy 的伙伴们 | Bitsy 经典版 | 媒体、展览等 网络上的 Bitsy itch.io | Mastodon | GitHub ~*~
最近的一场 Hacker News 讨论聚焦于 **Bitsy**,这是一个基于浏览器的引擎,用于制作复古风格的叙事类游戏。
用户称赞该工具具有迷人的、易于上手的像素艺术风格,且非常适合小型项目。然而,一些开发者指出,在构建大型、文本密集型作品时,它可能会让人感到力不从心。虽然许多人认为该平台更倾向于“互动诗歌”而非传统游戏,但参与者也为那些寻求更常规游戏机制的人分享了建议。
此次讨论还成为了类似游戏创作工具爱好者的交流中心,用户们为有志于复古风格游戏开发的开发者推荐了其他替代工具,如 Playdate 的 **Pulp** 和 **Pico-8** 虚拟主机。
“极度财富(如万亿身家)意味着卓越的贡献或才干”这一神话,是资本主义意识形态的基石。现实中,此类财富并非出自“孤胆天才”,而是从数百万人的集体劳动中系统性攫取的结果。 资本主义旨在通过剥离劳动者创造的价值与其实际所得工资来集中财富,并将剩余价值流向生产资料所有者。所有权本身就是一种社会统治形式,使个人能够拥有足以与主权国家抗衡的资源、基础设施和政策影响力。这种权力的集中之所以持续存在,并非因为它是创新的必要条件(创新依赖于积累的公共知识与集体努力),而是因为它是一个优先考虑私人利润而非人类需求的制度的逻辑产物。 归根结底,万亿富翁的出现是社会失败的症状,而非人类潜能的胜利。它反映了一个资源被统治阶级垄断、而基本需求却得不到满足的世界。挑战这一现状,需要摒弃对亿万富翁的盲目崇拜,并意识到真正的进步在于集体协作,而非等级森严的财富积累。
抱歉。