Google DeepMind recently published Amortized Planning with Large-Scale Transformers: A Case Study on Chess, wherein they present a transformer-based model for playing chess, trained on the strongest chess engine, StockfishSpecifically, Stockfish 16, which has since been surpassed by newer versions of Stockfish. ↩. This model takes a game-state as input, and learns to output three separate quantities:
- , the value of the state as determined by a 50ms Stockfish search
- , the value of taking action in state , as determined by a 50ms Stockfish search
- , a probability distribution over actions in state , attempting to match the choice of 50ms-SF
Once trained, this model can be used to play chess by taking in a given state.
Notably, this is extremely similar to the model used in AlphaZero, DeepMind's general game playing algorithm, the design of which has since been replicated in strong open-source game playing programs like KataGo and Leela Chess Zero. AZ-style networks predict policy and value only, so only the output is new.
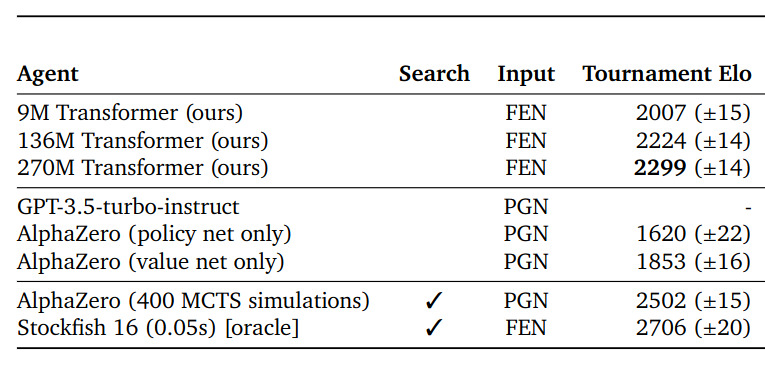
Indeed, in the paper they compare the model's playing strength to AlphaZero, either using the AZ model's policy (taking the move with the highest probability), or using the model's value estimate, by explicitly doing depth-one rollout of the legal moves in the position and taking the move that maximises the value of the resulting state (technically a search process, but the authors don't mark it as one):

The big claim the authors make here is that their model plays chess at the level of a human Grandmaster, and claim to demonstrate this by the fact that the model reached a Lichess Blitz rating of 2895. This is an impressive rating, and frankly it seems pretty hard to argue that it could be achieved by any human of less-than-Grandmaster strength. One potential caveat is that the model cannot make use of extra time to "think harder", so its Elo will decrease as time controls increase, meaning that even if it is “Grandmaster strength” in Blitz, it may be sub-Grandmaster in “real time controls”.
The biggest problem with this whole paper, in my opinion, is that it may not be a new result at all! The open-source Leela Chess Zero project have made massive improvements over AlphaZero, and their networks' raw policies are far stronger than AZ's - a test of BT4, the currently-strongest Lc0 network, versus T30/T40, the Lc0 nets that are closest in strength to AlphaZero, yields +547 Elo over T40, and +628 Elo over T30. These sorts of numbers catapult Lc0 right up to the same level as DeepMind's 136M Transformer (1620+600=2220) - and this is Policy Elo! The AZ nets get +230 more Elo from using the value head, so one could reasonably expect that BT4-Value would score something like 2400 in this paper's Tournament Elo.
They later analyse some of the games that their model played - the writing here is strange, as the authors appear ready to believe that the model they have trained to mimic Stockfish may have outperformed Stockfish... somehow? (a model outperforming its training data isn't actually so totally far-fetched as I make it sound, but the openness the authors express here is still totally unlicensed)

Particularly egregious is that they then elect to resolve this difference in opinion by appeal to human masters, who are hundreds of elo weaker than Stockfish!
In conclusion, this doesn't seem like a very serious paper, and it almost seems to make a point of ignoring literally the most significant piece of existing work in the area.
a comparison of “searchless” (1-ply value head maximisation) puzzle-solving ability across AlphaZero, the paper's model, and Lc0
