By Felix Wunderlich -
The car wash test is the simplest AI reasoning benchmark that nearly every model fails, including Claude Sonnet 4.5, GPT-5.1, Llama, and Mistral.
The question is simple: "I want to wash my car. The car wash is 50 meters away. Should I walk or drive?"
Obviously, you need to drive. The car needs to be at the car wash.
The question has been making the rounds online as a simple logic test, the kind any human gets instantly, but most AI models don't. We decided to run it properly: 53 models through Opper's LLM gateway, no system prompt, forced choice between "drive" or "walk" with a reasoning field. First once per model, then 10 times each to test consistency.
Part 1: The Single-Run Test — 42 Out of 53 AI Models Said "Walk"
On a single call, only 11 out of 53 models got it right. 42 said walk.
The models that passed the car wash test:
- Claude Opus 4.6
- Gemini 2.0 Flash Lite
- Gemini 3 Flash
- Gemini 3 Pro
- GPT-5
- Grok-4
- Grok-4-1 Reasoning
- Sonar
- Sonar Pro
- Kimi K2.5
- GLM-5
Across entire model families, only one model per provider got it right: Opus 4.6 for Anthropic, GPT-5 for OpenAI. All Llama and Mistral models failed.
The wrong answers were all the same: "50 meters is a short distance, walking is more efficient, saves fuel, better for the environment." Correct reasoning about the wrong problem. The models fixate on the distance and completely miss that the car itself needs to get to the car wash.
The funniest part: Perplexity's Sonar and Sonar Pro got the right answer for completely wrong reasons. They cited EPA studies and argued that walking burns calories which requires food production energy, making walking more polluting than driving 50 meters. Right answer, insane reasoning.
Full reasoning traces from the single-run experiment — click to zoom
Single-Run Results by Model Family
| Family | Score | Notes |
|---|---|---|
| Anthropic | 1/9 | Only Opus 4.6 |
| OpenAI | 1/12 | Only GPT-5 |
| 3/8 | Gemini 3 models nailed it, all 2.x failed | |
| xAI | 2/4 | Grok-4 yes, non-reasoning variant no |
| Perplexity | 2/3 | Right answer, wrong reasons |
| Meta (Llama) | 0/4 | |
| Mistral | 0/3 | |
| DeepSeek | 0/2 | |
| Moonshot (Kimi) | 1/4 | |
| Zhipu (GLM) | 1/3 | |
| MiniMax | 0/1 |
Part 2: The 10-Run Consistency Test — Can AI Models Reason Reliably?
Getting it right once is easy. But can they do it reliably? We reran every model 10 times, 530 API calls total.
The results got worse. Of the 11 models that passed the single-run test, only 5 could do it consistently.
10/10 — The Only Reliable AI Models (5 Models)
Claude Opus 4.6, Gemini 2.0 Flash Lite, Gemini 3 Flash, Gemini 3 Pro, Grok-4
These are the only models that answered correctly every single time across 10 runs.
8/10 — Close, But Still Fails 20% of the Time (2 Models)
GLM-5, Grok-4-1 Reasoning
Both get it right most of the time. But in production, an 80% success rate on basic reasoning means 1 in 5 API calls returns the wrong answer.
7/10 — GPT-5 Fails 3 Out of 10 Times
OpenAI's flagship model fails this 30% of the time. When it gets it right, the reasoning is concise: "You need the car at the car wash to wash it, so drive the short 50 meters." When it gets it wrong, it writes about fuel efficiency.
6/10 or Below — Coin Flip or Worse (12 Models)
| Model | Score |
|---|---|
| GLM-4.7 | 6/10 |
| Kimi K2.5 | 5/10 |
| Gemini 2.5 Pro | 4/10 |
| GLM-4.7 Flash | 4/10 |
| Sonar Pro | 4/10 |
| Gemini 2.5 Pro EU | 2/10 |
| MiniMax M2.1 | 2/10 |
| Kimi K2 Thinking | 2/10 |
| DeepSeek v3.2 | 1/10 |
| GPT-OSS 20B | 1/10 |
| GPT-OSS 120B | 1/10 |
| Kimi K2 Thinking Turbo | 1/10 |
0/10 — Never Got It Right (33 Models)
All Claude models except Opus 4.6, all Llama, all Mistral, GPT-4o, GPT-4.1, GPT-5-mini, GPT-5-nano, GPT-5.1, GPT-5.2, Grok-3, Grok-4-1 non-reasoning, Sonar, Sonar Reasoning Pro, DeepSeek v3.1, Kimi K2 Instruct.
Full reasoning traces from the 10-run consistency experiment — click to zoom
What Changed Between One Run and Ten: The Fluke Problem
Some models that looked correct on the first try turned out to be flukes.
Sonar went from correct to 0/10. It still writes the same 200-word essay about food production energy chains and EPA studies in every single run, it just flips the conclusion to "walk" every time now. Same reasoning, opposite answer.
Kimi K2.5 went from correct to a perfect 5/5 tie. Literally cannot decide.
Sonar Pro went from correct to 4/10. When it says "drive," it's because of calorie-emission math, not because the car needs to be there.
And one model went the other direction: GLM-4.7 went from wrong on the single run to 6/10. It was unlucky the first time. Still not reliable, but the capability is clearly in the weights.
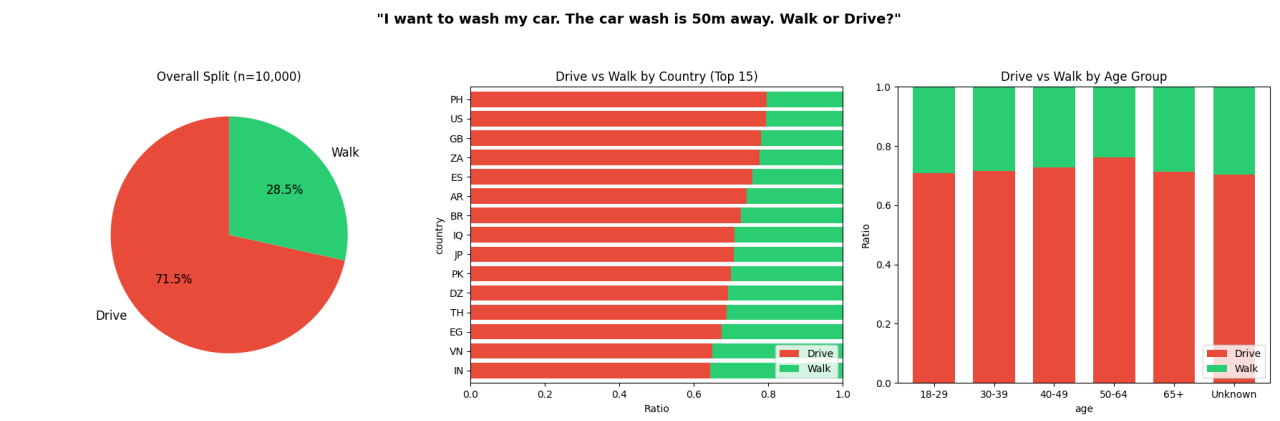
Part 3: The Human Baseline — 10,000 People, Same Question
The most common pushback on the car wash test: "Humans would fail this too."
Fair point. We didn't have data either way. So we partnered with Rapidata to find out. They ran the exact same question with the same forced choice between "drive" and "walk," no additional context, past 10,000 real people through their human feedback platform.
71.5% said drive.

Turns out GPT-5 (7/10) answered about as reliably as the average human (71.5%) in this test. Humans still outperform most AI models with this question, but to be fair I expected a far higher "drive" rate.
That 71.5% is still a higher success rate than 48 out of 53 models tested. Only the five 10/10 models and the two 8/10 models outperform the average human. Everything below GPT-5 performs worse than 10,000 people given two buttons and no time to think.
Thanks to Jason Corkill and the Rapidata team for making this happen on short notice.
Notable Reasoning Across 530 Runs
530 runs produce a lot of reasoning text. Some highlights:
GLM-4.7 Flash on one of its correct runs: "Walking would require physically pushing or carrying the car, which is impractical and impossible." Probably the best articulation of the actual problem from any model.
Claude Sonnet 4.5 wrote: "The only scenario where driving might make sense is if you need to drive the car into the car wash anyway for an automatic wash" and then picked walk. It saw the answer and rejected it.
Claude Opus 4.5 suggested you should "walk to the car wash, then drive your car through the wash." The car is at home.
Gemini 2.5 Pro when it gets it right: "You want to wash your car. The car needs to be at the car wash for this to happen. Therefore, you must drive it there, regardless of the short distance." When it gets it wrong: "50 meters is a very short distance that would take less than a minute to walk." Same model, same prompt.
Why This Matters: The AI Reliability Problem in Production
This is a trivial question. There's one correct answer and the reasoning to get there takes one step: the car needs to be at the car wash, so you drive.
Out of 53 models, only 5 can do this reliably. 15 more can sometimes get there but unpredictably. The remaining 33 never get it right.
The pattern across 530 API calls shows three tiers of failure:
Models that never get it right (33/53): These models have learned "short distance = walk" as a heuristic and can't override it with contextual reasoning. The correct answer isn't accessible to them.
Models that sometimes get it right (15/53): The capability exists but competes with the distance heuristic. On any given call, either path might win. This is the most dangerous category for production AI. The model passes during evaluation and then fails unpredictably in deployment. Picking the right model isn't enough on its own.
Models that always get it right (5/53): The contextual reasoning consistently overrides the heuristic.
This is a toy problem with one logical step. Real-world AI applications involve chains of reasoning far more complex than this. If 90% of models can't reliably handle "the car needs to be at the car wash," how do they handle actual business logic, multi-step workflows, or ambiguous edge cases in production?
What Context Engineering Can Do About This
The car wash test is a zero-context problem by design. No system prompt, no examples, just a raw question. That's what makes it useful as a benchmark. But the failure mode is telling: models don't fail because they lack the capability. They fail because the heuristic ("short distance = walk") wins over the reasoning ("the car needs to be there").
Context engineering is one way to shift that balance. When you provide a model with structured examples, domain patterns, and relevant context at inference time, you give it information that can help override generic heuristics with task-specific reasoning.
We've seen this in practice. In a separate experiment, we took a small open-weight model that failed an agent-building task and added curated examples through Opper's context features. It matched the output quality of a frontier model at 98.6% lower cost, without changing the model itself.
The car wash problem is simple enough that the top 5 models solve it without help. But most production tasks aren't that clean. They involve ambiguity, domain knowledge, and constraints that aren't obvious from the prompt alone. For those, the gap between "sometimes gets it right" and "always gets it right" is often a context problem.
Methodology
All 53 models were tested through Opper's LLM gateway using the same prompt: "I want to wash my car. The car wash is 50 meters away. Should I walk or drive?" No system prompt. Forced choice between "drive" and "walk" with a reasoning field. The single-run test was one call per model. The 10-run retest was 10 identical calls per model (530 total), no cache / memory. Every call was traced and logged through Opper, so we could inspect each model's reasoning.
The human baseline was collected through Rapidata, using the same question and forced choice format across 10,000 participants.
Full data from every run is available for download: