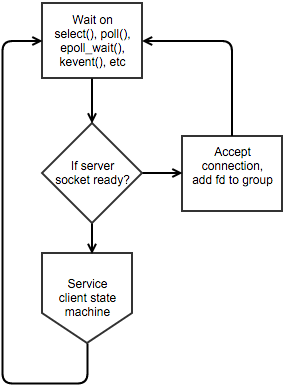
There's a network-server programming pattern which is so popular that it's the canonical approach towards writing network servers:
 ...
...This design is easy to recognise: The main loop waits for some event, then dispatches based on the file descriptor and state that the file descriptor is in. At one point it was in vogue to actually fork() so that each file descriptor could be handled by a different thread, but now "worker threads" are usually created that all perform the same task and rely on the kernel to schedule file descriptors to them.
A much better design is possible because of the epoll and kqueue, however most people use these "new" system calls using a wrapper like libevent which just encourages the same slow design people have been using for over twenty years now.
The design I currently use and recommend involves two major points:
- One thread per core, pinned (affinity) to separate CPUs, each with their own epoll/kqueue fd
- Each major state transition (accept, reader) is handled by a separate thread, and transitioning one client from one state to another involves passing the file descriptor to the epoll/kqueue fd of the other thread.
 ...
...This design has no decision points, simple blocking/IO calls, and makes simple one-page performant servers that easily get into the 100k requests/second territory on modern systems.
Creating the thread pool
Ask the operating system how many cores there are. Sometimes reserving some cores make sense, so let the user lower this number. If raising this number helps, then your state transitions are too complex and you will need to break them up.
pthread_attr_t a;
pthread_attr_init(&a);pthread_attr_setscope(&a,PTHREAD_SCOPE_SYSTEM);
pthread_attr_setdetachstate(&a,PTHREAD_CREATE_DETACHED);
t=sysconf(_SC_NPROCESSORS_ONLN);
for(i=0;i<t;++i)pthread_create(&id,&a,(void*)run,(void*)i);
while(busy(t)){pthread_mutex_lock(&tm);pthread_cond_wait(&tc,&tm);pthread_mutex_unlock(&tm);}
Then in each thread, do any per-thread initialisation and allocate your kevent/epoll fd:
void*run(int id){
set_affinity(id);
pthread_mutex_lock(&tm);
#ifdef __linux__
worker[id].q=epoll_create1(0);
#else
worker[id].q=kqueue();
#endif
...
pthread_mutex_unlock(&tm);pthread_cond_signal(&tc);
Setting processor affinity is something that must be done in-process on some platforms, but the system administrator should be able to provide input:
cpu_set_t c;CPU_ZERO(&c);CPU_SET(id,&c);pthread_setaffinity_np(pthread_self(),sizeof(c),&c);
Apple OSX doesn't support pthread_setaffinity_np() directly, but what we need is easy to implement:
extern int thread_policy_set(thread_t thread, thread_policy_flavor_t flavor, thread_policy_t policy_info, mach_msg_type_number_t count);
thread_affinity_policy_data_t ap;
thread_extended_policy_data_t ep;
ap.affinity_tag=id+1;
ep.timeshare=FALSE;
thread_policy_set(mach_thread_self(),THREAD_EXTENDED_POLICY,(thread_policy_t)&ep,THREAD_EXTENDED_POLICY_COUNT);
thread_policy_set(mach_thread_self(),THREAD_EXTENDED_POLICY,(thread_policy_t)&ap,THREAD_EXTENDED_POLICY_COUNT);
Creating the listening socket
Increase the number of file descriptors to handle the number of connections you want to handle n=2048 per thread:
getrlimit(RLIMIT_NOFILE, &r);
if(r.rlim_curn)){r.rlim_cur=n;P(setrlimit(RLIMIT_NOFILE,&r)==-1,oops("setrlimit"));}
Disabling lingering is important otherwise you'll run out of file descriptors:
s=socket(sin.sin_family=AF_INET,SOCK_STREAM,IPPROTO_TCP);
lf.l_onoff=1;lf.l_linger=0;setsockopt(s,SOL_SOCKET,SO_LINGER,&lf,sizeof(lf));
listen(s,n*t);
If the client speaks first (as in HTTP), then enable deferred accepts on Linux:
#ifdef __linux__
o=5;setsockopt(s,SOL_TCP,TCP_DEFER_ACCEPT,&o,sizeof(o));
#endif
The accept-loop
There's no point in waiting for epoll/kevent since all this loop does is accept connections:
for(;;){
f=accept(s,0,0);
...
q=pick();
#ifdef __linux__
struct epoll_event ev={0};
ev.data.fd=f;ev.events=EPOLLIN|EPOLLRDHUP|EPOLLERR|EPOLLET;
epoll_ctl(q,EPOLL_CTL_ADD,f,&ev);
#else
struct kevent ev;
EV_SET(&ev,f,EVFILT_READ,EV_ADD|EV_CLEAR,0,NM,NULL);
kevent(q,&ev,1,0,0,0);
#endif
}
Any socket options should be enabled before handing to the next step. Consider enabling a timeout (SO_RCVTIMEO) to the socket instead of tracking timers in your application:
struct timeval tv={0};
tv.tv_sec=5;
setsockopt(f,SOL_SOCKET,SO_RCVTIMEO,&tv,sizeof(tv));
fcntl(f,F_SETFL,O_NONBLOCK);
Hasan Alayli observes that on Linux you can use accept4() to combine accept() and the fcntl().
Scheduling tasks can usually be done by rotating through the threads:
int pick(void){ static int c; ++c; return worker[c%t].q; }
...however some workloads benefit from some analysis here and choosing a worker based on the probability that input will belong to one type or another can actually improve the mean throughput if some bias is introduced into the pick() routine. Experiment and benchmark.
The request-loop
A task that has some input will begin with a epoll_wait() or kevent() step:
#ifdef __linux__
struct epoll_event e[1000];
for(i=0;i<epoll_wait(q,e,1000,-1);++i)
if(e[i].events&(EPOLLRDHUP|EPOLLHUP))close(e[i].data.fd);
else handle(e[i].data.fd);
#else
struct kevent e[1000];
for(i=0;i<kevent(q,0,0,e,1000,0);++i)
if(e[i].flags&EV_EOF)close(e[i].ident);
else handle(e[i].ident);
#endif
Each file descriptor will only be used by a single request in a single state, so having an array for input buffers for file descriptors can simplify a lot of algorithms. handle(fd) can read from the input, use write() or sendfile() as necessary however if more than one syscall is needed schedule the task with a worker that performs that operation.