My LinkedIn and Twitter feeds are full of screenshots from the recent Forbes article on Cursor claiming that Anthropic's $200/month Claude Code Max plan can consume $5,000 in compute. The relevant quote:
Today, that subsidization appears to be even more aggressive, with that $200 plan able to consume about $5,000 in compute, according to a different person who has seen analyses on the company's compute spend patterns.
This is being shared as proof that Anthropic is haemorrhaging money on inference. It doesn't survive basic scrutiny.
What the $5,000 figure actually is
I'm fairly confident the Forbes sources are confusing retail API prices with actual compute costs. These are very different things.
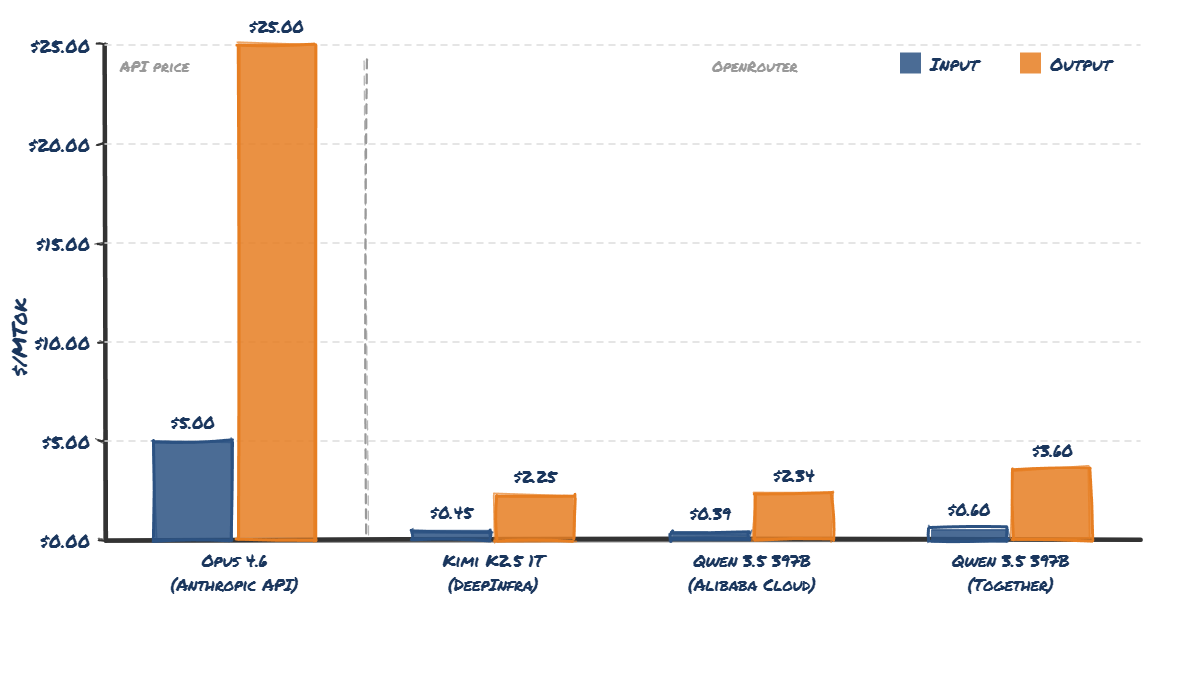
Anthropic's current API pricing for Opus 4.6 is $5 per million input tokens and $25 per million output tokens. At those prices, yes - a heavy Claude Code Max 20 user could rack up $5,000/month in API-equivalent usage. That maths checks out.
But API pricing is not what it costs Anthropic to serve those tokens.
The OpenRouter reality check
The best way to estimate what inference actually costs is to look at what open-weight models of similar size are priced at on OpenRouter - where multiple providers compete on price.
Qwen 3.5 397B-A17B is a good comparison point. It's a large MoE model, broadly comparable in architecture size to what Opus 4.6 is likely to be. Equally, so is Kimi K2.5 1T params with 32B active, which is probably approaching the upper limit of what you can efficiently serve.
Here's what the pricing looks like:
 The Qwen 3.5 397B model on OpenRouter (via Alibaba Cloud) costs _$0.39_ per million input tokens and _$2.34_ per million output tokens. Compare that to Opus 4.6's API pricing of $5/$25. Kimi K2.5 is even cheaper at $0.45 per million input tokens and $2.25 output.
The Qwen 3.5 397B model on OpenRouter (via Alibaba Cloud) costs _$0.39_ per million input tokens and _$2.34_ per million output tokens. Compare that to Opus 4.6's API pricing of $5/$25. Kimi K2.5 is even cheaper at $0.45 per million input tokens and $2.25 output.
That's roughly 10x cheaper.
And this ratio holds for cached tokens too - DeepInfra charges $0.07/MTok for cache reads on Kimi K2.5 vs Anthropic's $0.50/MTok.
These OpenRouter providers are running a business. They have to cover their compute costs, pay for GPUs, and make a margin. They're not charities. If so many can serve a model of comparable size at ~10% of Anthropic's API price and remain in business, it is hard for me to believe that they are all taking enormous losses (at ~the exact same rate range).
If a heavy Claude Code Max user consumes $5,000 worth of tokens at Anthropic's retail API prices, and the actual compute cost is roughly 10% of that, Anthropic is looking at approximately $500 in real compute cost for the heaviest users.
That's a loss of $300/month on the most extreme power users - not $4,800.
However, most users don't come anywhere near the limit. Anthropic themselves said when they introduced weekly caps that fewer than 5% of subscribers would be affected. I personally use the Max 20x plan and probably consume around 50% of my weekly token budget and it's hard to use that many tokens without getting serious RSI. At that level of usage, the maths works out to roughly break-even or profitable for Anthropic.
So who is actually losing $5,000?
The real story is actually in the article. The $5,000 figure comes from Cursor's internal analysis. And for Cursor, the number probably is roughly correct - because Cursor has to pay Anthropic's retail API prices (or close to it) for access to Opus 4.6.
So to provide a Claude Code-equivalent experience using Opus 4.6, it would cost Cursor ~$5,000 per power user per month. But it would cost Anthropic perhaps $500 max.
And the real issue for Cursor is that developers want to use the Anthropic models, even in Cursor itself. They have real "brand awareness", and they are genuinely better than the cheaper open weights models - for now at least. It's a real conundrum for them.
Anthropic is not a profitable company. But inference isn't why.
Obviously Anthropic isn't printing free cashflow. The costs of training frontier models, the enormous salaries required to hire top AI researchers, the multi-billion dollar compute commitments - these are genuinely massive expenses that dwarf inference costs.
But on a per-user, per-token basis for inference? I believe Anthropic is very likely profitable - potentially very profitable - on the average Claude Code subscriber.
The "AI inference is a money pit" narrative is misinformation that actually plays into the hands of the frontier labs. If everyone believes that serving tokens is wildly expensive, nobody questions the 10x+ markups on API pricing. It discourages competition and makes the moat look deeper than it is.
If you want to understand the real economics of AI inference, don't take API prices at face value. Look at what competitive open-weight model providers charge on OpenRouter. That's a much closer proxy for what it actually costs to run these models - and it's a fraction of what the frontier labs charge.