At Nango, we build open source infrastructure for product integrations.
With all the recent advancements in coding models, we wanted to see how far we can push an autonomous agent building integrations with external APIs.
TL;DR: Our background agent isn’t perfect, but it reliably generates ~200 integrations across five APIs (Google Calendar, Drive, Sheets, HubSpot, and Slack) in 15 minutes and less than $20 in token costs.
Previously, this would have taken an engineer about a week.
This post is about what it took to get there, what broke along the way, and what we learned building a background coding agent for API integrations.
Try it yourself: Our Nango AI builder lets you build custom API integrations with the skills from this article.
Our setup
The pipeline is pretty simple:
- We define a list of interactions to build, for example
create-calendar-event,sync-files, orsend-slack-message - Our orchestrator prepares one workspace per interaction with the right Nango integrations scaffolding generated by our CLI
- We spawn one OpenCode agent per interaction
- Each agent independently builds its interaction, tests it with the external API (the agent has access to a test account), and iterates until it works
- Once all agents finish, the orchestrator checks their work and assembles the individual interactions into one Nango integration per API
To make our learnings reusable for customers, we rely heavily on skills. They are easy to publish, work across agents, and adapt to different use cases through a prompt that references them.
The spec for each interaction is really simple:
{
"id": "create-event",
"displayName": "Create Event",
"description": "Create a calendar event",
"prompt": "As a pre-requisite create a calendar first",
"comments": ""
},Besides the description of the interaction, we also pass the agent information about the API docs and how to load a test connection (=test account) from Nango:
connection_id: bff8b7b7-cb26-443f-9a3a-ec11a5d4d6ff
integration_id: google-calendar
env: dev
---
This integration uses the Google Calendar REST API v3.
API docs: https://developers.google.com/workspace/calendar/api/v3/referenceNote that we only gave the agent very high-level instructions (“create a calendar event”), and it autonomously researched required parameters, formats, and descriptions.
This works surprisingly well, but it does just as well if you give it a very precise use case to create.
In the following sections, we want to highlight some of our learnings from testing this setup over hundreds of generations.
1. Let the agents run wild first
There are two obvious approaches: start with lots of guardrails, or start with very few and learn what the models actually do.
We chose the second because we didn’t want to overfit our assumptions. We didn’t know yet what the model would be best at or which constraints would matter, so we gave agents broad freedom in a sandbox and observed what happened.
Some of it went better than expected.
Agents often filled in gaps in our instructions. They inferred how to use existing SDK helpers from surrounding code. They found details about the external API calls with very little context. They generally required a lot less handholding than we expected.
But they also broke in very unexpected ways, sometimes spectacularly.
2. Do not trust the agents
Agents optimize for completion at all costs. We expected this to be a whack-a-mole problem, and it was.
Here are some of the behaviours we saw.
Copying test data from other agents
One agent needed an event ID for a test. Instead of creating or finding one properly, it looked through another agent's directory and reused the ID it found there.
That was funny once, but hardly a predictable pipeline.
Fix: Agents are no longer allowed to leave their own directory and have received better instructions on how to generate test data.
Hallucinating a Nango CLI command
By now, we all know agents love CLIs. Some hallucinated commands were genuinely good product inputs, but the agent often got stubborn when a command failed. Instead of trying an alternative path, such as calling our API as initially instructed, it would go down a rabbit hole trying to make a command work that simply doesn’t exist.
Fix: Improve instructions around the available API and CLI. And we are considering giving the agent at least some of the CLI commands it wants.
Editing test data when the implementation failed
The Nango CLI has a command to save responses from the external API as reusable test fixtures.
Sometimes the agent did not like the fixture data because its implementation failed with it. Changing the test data was easier than fixing the code, so that is what it tried to do.
We first removed edit permissions for .json files. That helped a bit.
Then some agents started using sed, bash redirection, or other shell commands to get around that restriction.
Fix: Tighter edit permissions, clear instructions not to edit tests, and explicit checks that test fixtures were not modified.
Faking API reachability
Sometimes the external API returned a 403, had missing scopes, or was otherwise not reachable.
Instead of flagging that as an environment or auth problem, the agent sometimes decided to keep going by writing the response it thought the API would probably return.
That is rational behavior if the internal goal is "finish the task". It is bad behavior if the actual goal is "produce a trustworthy integration".
Fix: Prevent the agent from modifying test data at all and make failed API access a hard stop.
Claiming it is done when it is not done
This one is familiar to anyone who has used coding agents for real work.
The agent writes a clean summary, says everything is complete, and leaves behind code that does not compile, does not pass tests, or does not actually implement the interaction correctly.
Once an agent gets into that state, recovery is often not worth it.
Fix: Delete the agent, restart generation for this interaction from scratch.
Refusing to use SDK features the way we wanted
Sometimes the agent found a local workaround and decided that was good enough, even when we explicitly wanted it to use a Nango SDK feature.
We did not want to force one pattern in every case. Sometimes the agent has a valid reason. But we did want it to seriously consider the abstraction we intended it to use.
Fix: the agent is only allowed to skip the SDK feature if it leaves a short comment explaining why that feature does not help here.
This worked better than expected. Requiring a short explanation often pushed the agent into realizing that it should use the feature after all.
Post-completion checks
Once an agent finishes, our orchestrator checks the result by:
- re-running all tests with the Nango CLI
- running compilation and linters
- scanning the messages of its internal dialogue for common issues
- verifying that generated artifacts and fixtures were not modified
OpenCode makes this easy because all messages are stored in a SQLite database, so it is straightforward to inspect traces and automate checks.
The main takeaway here is simple: do not trust the agent. Verify everything.
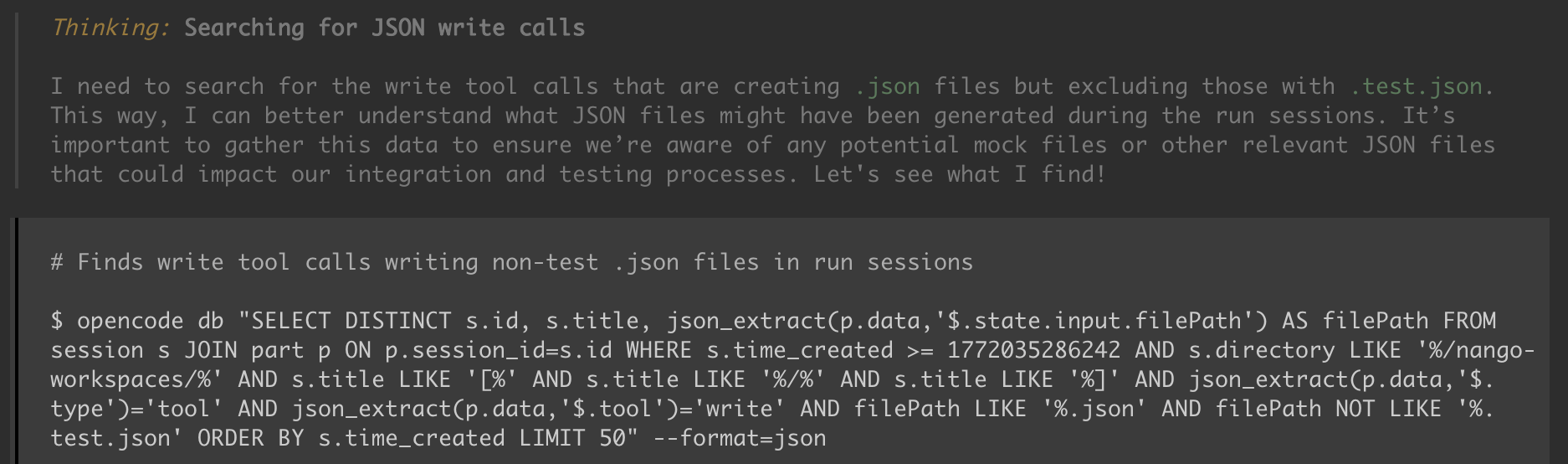
3. Ignore the final error message and trace the root cause
When a run failed, the final error reported by the agent was often a red herring.
A common pattern looked like this:
- The agent hallucinated a CLI command
- The command failed
- The agent misread the failure
- It built a workaround on top of the wrong assumption
- The workaround introduced a second problem
- The final error had very little to do with the original mistake
If you only debug from the final error, you often end up debugging the wrong thing.
We saw the same pattern in other forms too:
- wrong input parameters that sent the agent in the wrong direction
- bad assumptions about auth scopes
- fake helper commands that created several layers of downstream confusion
- implementation bugs that were actually caused by issues in the generated scaffolding
The fix was to debug from the top, not the bottom: find the first bad assumption in the trace and fix the root cause.
Reviewing successful runs was just as useful as reviewing failed ones.
Sometimes an agent reached a correct result, but only after spending a lot of time working around a problem we had introduced. Looking at those runs helped us understand where the agent was losing time, where the instructions were unclear, and where the environment added avoidable friction.
That made the system better in three ways at once: higher pass rate, lower token usage, and faster execution.
4. Skills are immensely powerful
Building this background agent really drove home how powerful skills are.
We did not need MCP-heavy orchestration, dynamic tool generation during execution, or extra agent layers managing other agents. Skills, plus a simple deterministic orchestrator and a coding harness like OpenCode, were enough.
For us, the power of skills comes from two things:
- Encapsulating specific know-how about building integrations
- Distributing that know-how to a wide audience: our background agent, Nango customers, solution engineers, and anyone else who wants to build custom integrations on Nango.
We publish an AI integration builder skill that customers use to build integrations on Nango.
As we learned new best practices from dogfooding this with our background agent, we could easily iterate on the skill and publish new versions. Thanks to package managers like skills.sh, these updates are easy for everyone using our skills to apply.
5. The OpenCode SDK is excellent for background agents
OpenCode was a great fit for this project. A few things stood out.
Client-server architecture
It runs headless in an execution pipeline.
When something goes wrong, we can attach the UI to the session and inspect what happened. This is a big productivity boost, even in the age of AI agents.
Great SDK
The SDK made it straightforward to manage sessions, configure runs, and integrate OpenCode into our orchestrator.
Many coding tools still feel designed primarily for interactive use. OpenCode did not.
Good technical choices
SQLite message storage made debugging easier.
We could inspect traces directly, write custom scripts around them, and automate checks without fighting the underlying system.
Open source helps more with AI tools
Because OpenCode is open source, we can inspect how it works when something behaves unexpectedly.
Models can also read the code when needed, which helps answer deeper platform questions.
Best practices transfer well
The setup is close enough to other coding agents that our skills and operational practices transfer well.
That matters because we do not want a fragile system tied to a single tool, and we want reusable practices for our team and customers working in different agent environments.
Conclusion
Agents are not ready to autonomously ship every integration end-to-end.
But with the right scaffolding, tools, constraints, and verification, they can reliably complete a meaningful slice of integration work.
We’re excited to make our background agent available to all Nango customers, and can’t wait to see what the next generation of models will improve!