Back in November last year, I started a new job at Intercom, and one of the first projects I got to work on was improving the Intercom monolith CI with some of my new colleagues.
Interestingly, I never got around to talking about CI on this blog, even though I consider it to be one of my main areas of expertise. That topic is way beyond the subject I’d like to talk about here, but just to give a bit of context, a key driver in CI performance and user experience is how fast you can get a Ruby process ready to run tests.
When working with very large test suites, it becomes essential to run tests in parallel. If you have a test suite that runs in say, 1 hour, on paper, you can run it in 15 minutes on 4 workers, or in 6 minutes on 10 workers, and 1 minute on 60 workers.
But that’s a bit too simplistic, in practice, a CI test runner has two phases.
First, a setup phase that all runners have to go through, which includes fetching the source code, getting backing services like the database ready, and booting the application. Once the setup phase is done, the workers can start doing the actually useful work of running tests.
So using the same 1-hour test suite, but now with a 1-minute setup phase, will now take 16 minutes if you are using 4 workers but 2 minutes if you are using 60 parallel workers. That’s a much worse user experience, but also means half of your compute isn’t spent doing the actual work, likely increasing your costs.
All this to say that parallelizing test suites has diminishing returns that are entirely tied to how costly setting up a worker is. The worker setup time is like a fixed cost toll, hence reducing it both improves user experience and reduces cost.
Given that the Intercom monolith CI runs with 1350 parallel workers by default, one second is optimized out of the setup time has 1350 times more impact than a second optimized out of a particular test, and saves over 20 minutes of compute per build.
Hence, while the team also worked on speeding up various slow tests and factories, I personally was very focused on reducing the setup time, shaving every second or even split seconds I could find.
As part of this effort, I looked into speeding up the application boot time, and if you’re a Rubyist, you probably know about Bootsnap.
What Does Bootsnap Even Do?
While Bootsnap has been in the default Rails gemfile for almost a decade now, and is very popular even in non-Rails codebases, based on chats I had with people online or at conferences, I suspect many people don’t quite understand exactly what it is doing. So let me explain just one of the optimizations it performs.
When you require a file (what is internally referred to as a “feature”), Ruby has to perform a very expensive linear search in its load path, something that looks a bit like this:
def search_load_path(feature)
if path.end_with?(".rb", ".so")
$LOAD_PATH.each do |load_path|
absolute_path = File.join(load_path, feature)
return absolute_path if File.exist?(absolute_path)
end
return nil
else
search_load_path("#{path}.rb", "#{path}.so")
end
end
def require_internal(feature)
return false if $LOADED_FEATURES.include?(feature)
absolute_path = if File.absolute_path?(feature)
feature
else
search_load_path(feature)
end
unless absolute_path
raise LoadError, "cannot load such file: #{feature}"
end
load(absolute_path)
end
The problem with this code loading mechanism is that, while simple, it scales very badly.
A clean Ruby process starts with approximately 8 paths in its load path, so require is relatively cheap,
worst case scenario, Ruby will query the file system 16 times.
But then, every single gem you add to your gemfile adds one extra entry in $LOAD_PATH, and will in turn likely call require
even more times.
Meaning that starting a Ruby program isn’t linear, but much worse. The cost is roughly O(N*M) with N being $LOAD_PATH.size and M being $LOADED_FEATURES.size.
In other words, an application with 400 gems is likely way more than twice as slow to boot compared to an application with 200 gems.
That’s a problem Aaron Patterson explained in his GORUCO 2015 talk,
and that talk in turn inspired me to write bootscale,
which we used with success in the Shopify monolith for a while, but while very effective, it was quite brittle, so it remained
mostly confidential.
Later on, my former colleague Burke Libbey, reimplemented the same idea, but in a much more robust and cleaner way,
giving birth to bootsnap, and facilitating its adoption across the community.
But enough history, let’s dive into what it does.
Load Path Caching.
While this is not the only thing Bootsnap does, its main feature is load path caching.
The idea is simple, instead of repeatedly testing the existence of files over and over, Bootsnap eagerly
scan all directories in $LOAD_PATH to build a large map of all potentially requirable files, as to provide a way to
look them up with just a O(1) hash lookup.
It’s a bit over-simplified, but in essence, Bootsnap’s cache is just a big hash:
@cache = {
"active_support/core_ext.rb" => "/gems/activesupport-8.1.2/lib/active_support/core_ext.rb",
"active_support/json.rb" => "/gems/activesupport-8.1.2/lib/active_support/json.rb",
...
}
Which then allows to decorate Kernel.require, as to cheaply translate relative paths into absolute ones,
hence entirely sidestepping Ruby’s slow search mechanism:
def require(feature)
unless File.absolute_path?(feature)
if feature.end_with(".rb", ".so")
feature = Bootsnap::LoadPathCache.lookup(feature)
else
feature = Bootsnap::LoadPathCache.lookup("#{feature}.rb") || Bootsnap::LoadPathCache.lookup("#{feature}")
end
end
require_without_bootsnap(feature)
end
There are, of course, many subtle corner cases Bootsnap has to deal with to reproduce Ruby’s behavior as accurately as possible, but conceptually, Bootsnap is quite simple and reliable.
Thanks to this cache, instead of scanning and checking the existence of up to 2*N files in every require call, we only
need to pay a one-time cost, which is quickly amortized.
Cache Invalidation
Now, the problem with adding a cache is that you need to know when it’s no longer valid, and as the famous maxim says, cache invalidation is one of the hardest problems in programming.
Hence, Bootsnap can’t just persist its cache across CI builds, as any added or removed file in any of the load paths MUST invalidate the cache.
The way Bootsnap does it is that in the cache, it records the mtime of the scanned directories.
Whenever you add or remove a file in a directory, the directory’s mtime is updated.
However, its parent directory mtime is left unchanged:
require "fileutils"
FileUtils.rm_rf("/tmp/test/")
FileUtils.mkdir_p("/tmp/test/dir/subdir")
p File.mtime("/tmp/test/dir").to_f # 1776351416.5027087
p File.mtime("/tmp/test/dir/subdir").to_f # 1776351416.5027075
File.write("/tmp/test/dir/subdir/file.txt", "1")
p File.mtime("/tmp/test/dir").to_f # 1776351416.5027087
p File.mtime("/tmp/test/dir/subdir").to_f # 1776351416.502805
If file and directory mtime were updated recursively, that would be extremely powerful for many tools like Bootsnap,
however I suspect it wasn’t done this way out of performance concerns.
As such, Bootsnap has to recursively check the mtime of all directories in all load paths whenever it needs to revalidate the cache.
That’s cheaper than rebuilding the full cache, but still potentially thousands of stat(2) syscalls, so quite costly.
More importantly, on CI systems it’s relatively common to check out code using git, and git doesn’t care about mtime.
Which means in many cases, this cache won’t be re-usable across builds or machines, hence it will need to be rebuilt every time,
making the scanning performance important.
N+1 Syscalls
On the Intercom monorepo, scanning all load paths was just shy of a second, and as I said previously, even a split second was important to me, given it was part of the “setup time”. So I was keen on finding ways to improve it.
To understand the issue, let’s look at a very simplified implementation of Bootsnap’s load path scanner:
def scan(dir_path, requirables = [], directories = [])
Dir.foreach(dir_path) do |name|
path = "#{absolute_dir_path}/#{name}"
if File.directory?(path)
directory << path
scan(path, requirables, directories)
elsif name.end_with?(".rb", ".so")
requirables << name
end
end
end
Simply put, for each entry of a directory, if it’s also a directory, we record it in the list and recurse, otherwise,
if it has an extension we care about (.rb, .so, .bundle, etc) we add it to the list of requirable files.
At that stage, you might wonder why all this code isn’t just Dir["**/*.{rb,so}"], but Bootsnap needs to exactly match Ruby’s behavior
otherwise it could change the behavior of programs.
So while it is far fetched to imagine a project with directories named something.rb or somethingelse.so, assuming such
directories don’t exist would be a correctness bug.
There’s also some other subtleties, like needing to keep a list of all directories, even the ones not yet containing requirable files, so as to be able to revalidate the cache.
As mentioned, the real version is noticeably more complex, but from a performance standpoint, they’re equivalent.
Anyways, the problem with that path scanner, is that it’s essentially the system programming equivalent to what N+1 queries are to web programming, except with system calls.
While they’re much faster than a database query, syscalls are still something you wish to avoid or minimize when working at this level of abstraction, as they involve a context switch into the kernel.
The actual cost of a syscall depends on which system the program work on.
For instance, Linux syscalls are generally much faster than macOS ones, and some calls don’t even need a context switch.
On the other side, some macOS syscalls like open(2) have a massive overhead because of some security features.
In this specific case, for each entry in the directory, we’ll call File.directory?, which results in a stat(2) syscall.
But this N+1 syscall was a long-known issue even in early UNIX programs written in C, that’s why at least on Linux and BSD,
readdir(3), which is the API to read the content of a directory, exposes a d_type member, allowing us to know whether that
directory entry is a directory, a regular file, or something else without needing to issue a stat(2) call.
Unfortunately, while Ruby does use d_type internally to speed up methods like Dir[], it doesn’t expose it to the Dir.foreach
block.
This wasn’t a new issue for me, I knew about that problem back in 2020, as back then, I was already looking at speeding
up Bootsnap and Zeitwerk (which have the same issue).
That’s why back then, I opened a feature request for a Dir.scan method,
unfortunately that ticket never got any traction.
So I thought it was time to try again.
Implementing Dir.scan
Instead of reviving the old ticket, I decided to try again from scratch, and this time to include a prototype implementation.
Instead of adding a new method, I decided extend the existing Dir methods like foreach, so that they’d yield a second parameter to
represent the file type as a symbol.
This initial prototype sped up recursively walking directories by about 2x.
Soon after, Nobuyoshi Nakada, AKA nobu noticed my pull request and implemented
an alternative version that yielded File::Stat objects instead of symbols,
which I thought was much more elegant, so I opened a new feature request proposing his API.
But from experience, I knew that even in the best-case scenario, I’d need to wait for the next developer meeting before I’d get an OK from Matz, which means it would only make it into Ruby 4.1.
Waiting a full year to improve Bootsnap wasn’t very satisfactory, but since Bootsnap already ships with a C extension, I thought I could just implement that API in Bootsnap itself, to get the performance improvement immediately.
Benchmarked on Intercom’s monolith (only the repo, not the dependencies) showed the same 2x improvement:
ruby 3.4.4 (2025-05-14 revision a38531fd3f) +PRISM [arm64-darwin25]
Warming up --------------------------------------
orig 1.000 i/100ms
opt 1.000 i/100ms
Calculating -------------------------------------
orig 1.988 (± 0.0%) i/s (502.94 ms/i) - 10.000 in 5.031382s
opt 4.297 (± 0.0%) i/s (232.70 ms/i) - 22.000 in 5.120236s
Comparison:
orig: 2.0 i/s
opt: 4.3 i/s - 2.16x faster
Bootsnap was now able to scan ~32k files in ~10k repositories in 230ms, while the previous implementation needed
500ms.
Later on, my Ruby feature request was discussed at the developer meeting, and a few concerns were raised, notably it was considered that changing the signature of existing methods could cause backward compatibility issues.
Instead, after a few rounds of discussion, we settled on a new method: Dir.scan:
Dir.scan(path) do |name, type|
case type
when :directory
# ...
when :link
# ...
when :file
# ...
end
end
This new feature will be available in Ruby 4.1.0.
Other Path Methods
While this N+1 issue was definitely the main hotspot, and this 2x win felt good, I tend to treat performance gains like
mushroom hunting.
When you find a mushroom, it usually means that it’s an area where they grow well, and that no other mushroom hunter has passed by recently.
Well, in my experience, unoptimized code is the same. If you find a piece of code that is much slower than it could be, it suggests nobody ever needed it to be faster, hence it’s likely the same for other pieces of code in the same area.
In this case, another Ruby method Bootsnap calls a lot was File.join, and while it wasn’t a major hotspot, it still was
visible on boot profile, so I figured it was worth looking into.
But how are you supposed to tell if some code is slower than it should be?
What commonly slows down a given method is its handling of corner cases, so a good comparison point is a naive implementation
that only considers the happy path.
In our case, the most common usage of File.join by far is basically just a concatenation:
def file_join(parent, child)
"#{parent}/#{child}"
end
So if we benchmark this simplistic implementation against the real File.join, we should have a vague idea of how much
performance is left on the table:
# frozen_string_literal: true
require "benchmark/ips"
dir = "/Users/byroot/src/github.com/byroot/ruby/build"
entry = "path/to/file.txt"
Benchmark.ips do |x|
x.report("File.join") { File.join(dir, entry) }
x.report("interpolation") { "#{dir}/#{entry}" }
x.compare!(order: :baseline)
end
ruby 4.0.2 (2026-03-17 revision d3da9fec82) +YJIT +PRISM [arm64-darwin25]
Warming up --------------------------------------
File.join 429.375k i/100ms
interpolation 1.560M i/100ms
Calculating -------------------------------------
File.join 4.336M (± 0.2%) i/s (230.65 ns/i) - 21.898M in 5.050870s
interpolation 17.501M (± 0.5%) i/s (57.14 ns/i) - 88.905M in 5.079969s
Comparison:
File.join: 4335527.0 i/s
interpolation: 17501462.6 i/s - 4.04x faster
Bingo!
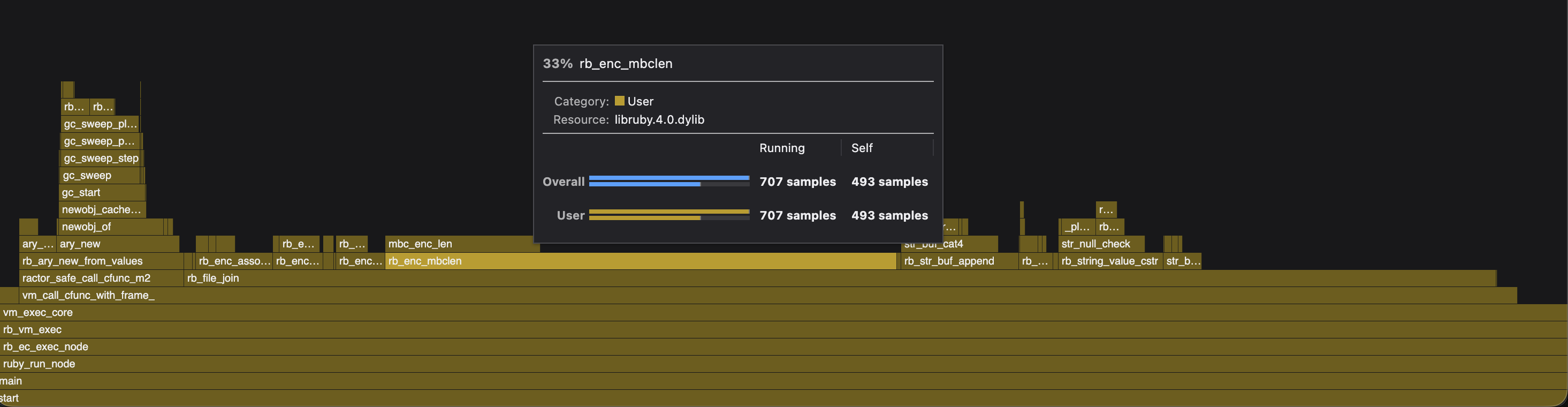
A 4x difference really didn’t pass the smell test, so I immediately profiled File.join called 10 million times in a loop:

What immediately surprised me was that File.join was spending over half its time in encoding-related functions (rb_enc_*),
most notably 33% in rb_enc_mbclen:
/**
* Queries the number of bytes of the character at the passed pointer.
*
* @param[in] p Pointer to a character's first byte.
* @param[in] e End of the string that has `p`.
* @param[in] enc Encoding of the string.
* @return If the character at `p` does not end until `e`, number of bytes
* between `p` and `e`. Otherwise the number of bytes that the
* character at `p` is encoded.
*
* @internal
*
* Strictly speaking there are chances when `p` points to a middle byte of a
* wide character. This function returns "the number of bytes from `p` to
* nearest of either `e` or the next character boundary", if you go strict.
*/
int rb_enc_mbclen(const char *p, const char *e, rb_encoding *enc);
Without even looking at the code, this told me there was a large potential for an easy optimization, because File.join,
like all other Ruby methods handling paths, rejects paths encoded with non-ASCII compatible encodings:
>> File.join("a".encode(Encoding::UTF_16LE), "b".encode(Encoding::UTF_16LE))
# => 'File.join': path name must be ASCII-compatible (UTF-16LE): "a" (Encoding::CompatibilityError)
So I thought this could be some leftover from a long time ago that could be pruned, hence I started digging into the git history,
and found that this multi-byte encoding support was added by nobu in January 2012 (commit ed469831),
whereas the code that rejects non-ASCII compatible encoding was only added in October 2012 (commit ad54de2a), again by nobu.
Unfortunately, neither commit message was really explicit in its intent, nor linked to a bug ticket or anything like that. Still, it did look like back in 2012, nobu tried to solve some issues with multi-byte paths, but it was ultimately decided to only accept ASCII-compatible encodings and reject the others.
But a few years of working on Ruby taught me never to assume nobu made a mistake, so before jumping to that conclusion, I figured I’d ask him, just in case:

And after a few hours, he answered me:

Indeed, it was no mistake, but some sort of corner case I didn’t know about involving the Japanese Shift JIS encoding. This wasn’t the first time it happened to me, and probably won’t be the last.
Anyways, in such cases, there is a Wikipedia page that helped me multiple times: Japanese language and computers. But let me explain the problem here.
ASCII Compatibility
Ruby supports over a hundred string encodings, and some of them are defined as “ASCII-compatible”, which isn’t a very well-defined concept. According to Ruby, both UTF-8 and Shift JIS are ASCII-compatible:
>> Encoding::UTF_8.ascii_compatible?
=> true
>> Encoding::Shift_JIS.ascii_compatible?
=> true
Which in a way isn’t wrong, because both are ASCII superset, meaning valid ASCII is both valid UTF-8 and valid Shift JIS.
However, UTF-8’s killer feature is that it’s way more ASCII compatible than previous multi-byte encodings.
All UTF-8 multibyte characters only use codes outside the ASCII range (so higher than 127).
Thanks to this, simple ASCII operations like searching for a specific character in the ASCII range can remain simple fixed-length operations:
def backslash?(string)
string.each_byte do |byte|
return true if byte == 0x5c # `\` is 0x5c in ASCII
end
false
end
In other words, with UTF-8, if you see a 0x5c byte, you know for sure it’s a backslash character, whereas with Shift-JIS,
it may be a backslash character, or it may be a continuation byte of a multi-byte character.
For example, 構 is encoded as 0x8d 0x5c.
Hence, you can’t efficiently treat Shift-JIS as ASCII, you must use a lookup table to check the width of every character,
which is what rb_enc_mbclen does (mbclen -> multi-byte character length), and it’s a very costly operation compared to
just iterating over a stream of bytes.
But ultimately, it’s fair to assume the overwhelming majority of paths passed to File.join are encoded in UTF-8 or even pure-ASCII,
as such, I could implement a fast path for these encodings and keep the more complex algorithm for the others.
That’s something I already did a few years prior for various string methods, such that Ruby already had a helper to check for such encodings:
static inline bool
rb_str_encindex_fastpath(int encindex)
{
// The overwhelming majority of strings are in one of these 3 encodings,
// which are all either ASCII or perfect ASCII supersets.
// Hence you can use fast, single byte algorithms on them, such as `memchr` etc,
// without all the overhead of fetching the rb_encoding and using functions such as
// rb_enc_mbminlen etc.
// Many other encodings could qualify, but they are expected to be rare occurrences,
// so it's better to keep that list small.
switch (encindex) {
case ENCINDEX_ASCII_8BIT:
case ENCINDEX_UTF_8:
case ENCINDEX_US_ASCII:
return true;
default:
return false;
}
}
Using this helper, I implemented a fastpath for File.join,
using single byte comparisons, and that’s when I realized the multi-byte checks weren’t the only thing slowing down File.join
and several other path handling methods.
Reverse Search
After every path segment it concatenates, File.join would call chompdirsep to find whether
the segment had a trailing path separator.
That’s necessary because File.join avoids duplicate separators:
>> File.join("foo/", "/bar")
=> "foo/bar"
But there was something very wrong with its implementation:
static char *
chompdirsep(const char *path, const char *end, rb_encoding *enc)
{
while (path < end) {
if (isdirsep(*path)) {
const char *last = path++;
while (path < end && isdirsep(*path)) path++;
if (path >= end) return (char *)last;
}
else {
Inc(path, end, enc);
}
}
return (char *)path;
}
As you can see, the function receives the start and end pointers of the string, and is supposed to
return the position of the last meaningful separator, so that extra trailing separators are eliminated by File.join:
>> File.join("foo///", "/bar")
=> "foo/bar"
The logical way to implement such a function would be to start looking from the back of the string, but here it was scanning the entire string, meaning longer paths were disproportionately slower to join than shorter paths.
I’m not one hundred percent sure why it was implemented that way, probably because the multi-byte aware Inc macro
was readily available, and implementing a Dec macro would have been a bit trickier, but technically it should have been doable.
In my case, I only cared about optimizing the fast path, so I inlined a single-byte version of it, which searches for duplicate separators from the end of the string:
long trailing_seps = 0;
while (isdirsep(name[len - trailing_seps - 1])) {
trailing_seps++;
}
rb_str_set_len(result, len - trailing_seps);
And while I was in there, I kept looking for other opportunities.
C Strings
The profile was showing 6.7% of time spent in rb_string_value_cstr, which, after fixing the multi-byte encoding, was now a much bigger deal.
What that function does is that it ensures that a given Ruby string is also a valid “C string”, which implies two things:
- The string is
NULLterminated. - The string does not contain any
NULLbytes.
Most Ruby methods dealing with path, do reject strings containing NULL bytes because that’s not valid for a file or directory name:
>> File.join("foo\0bar", "baz")
(irb):1:in 'File.join': string contains null byte (ArgumentError)
However, we actually don’t really care here if the string is NULL-terminated or not, as all we’re doing is concatenating it,
we’re not passing it to any C-level API that expects a NULL-terminated string.
So rb_string_value_cstr wasn’t really the right function to call, hence I could replace it with rb_str_null_check, which only checks
the content of the string.
Variadic Arguments
Another hotpot from the profile was the 10% spent in rb_ary_new_from_values, which, as its name indicates, creates a new
array.
The reason is that File.join has some pretty flexible arguments:
>> File.join("a", "b", "c") == File.join("a", ["b", ["c"]])
=> true
So to simplify the implementation, File.join was defined to receive all its arguments in an args Array:
static VALUE
rb_file_s_join(VALUE klass, VALUE args)
{
return rb_file_join(args);
}
To avoid that extra allocation and copying, I changed it to not create the Array object, and instead receive a pointer into the stack and the number of arguments:
static VALUE
rb_file_s_join(int argc, VALUE *argv, VALUE klass)
{
return rb_file_join(argc, argv);
}
Allowing for not allocating that extra array in the simpler cases.
Result
All this combined made the common usages of File.join over 7 times faster:
compare-ruby: ruby 4.1.0dev (2026-01-17T14:40:03Z master 00a3b71eaf) +PRISM [arm64-darwin25]
built-ruby: ruby 4.1.0dev (2026-01-18T12:55:15Z spedup-file-join 5948e92e03) +PRISM [arm64-darwin25]
warming up....
| |compare-ruby|built-ruby|
|:-------------|-----------:|---------:|
|two_strings | 2.477M| 19.317M|
| | -| 7.80x|
|many_strings | 547.577k| 10.298M|
| | -| 18.81x|
|array | 515.280k| 523.291k|
| | -| 1.02x|
|mixed | 621.840k| 635.422k|
| | -| 1.02x|
And now, on Ruby 4.1.0dev, using File.join for two simple paths is faster than using string interpolation:
ruby 4.1.0dev (2026-04-11T18:26:22Z compact-ar-table 06507da144) +YJIT +PRISM [arm64-darwin25]
Warming up --------------------------------------
File.join 1.944M i/100ms
interpolation 1.716M i/100ms
Calculating -------------------------------------
File.join 21.750M (± 0.4%) i/s (45.98 ns/i) - 108.860M in 5.005112s
interpolation 19.012M (± 0.6%) i/s (52.60 ns/i) - 96.111M in 5.055419s
Comparison:
File.join: 21750287.3 i/s
interpolation: 19012105.0 i/s - 1.14x slower
If you are curious, you can read the full pull request.
Other Methods
After finding such low-hanging fruits in File.join, I figured other path handling methods likely had similar issues,
and I applied similar optimizations to:
Not that any of these were massive hotspots to my knowledge, but I saw no reason not to optimize them too.