## GitHub 可用性更新与用户反应
GitHub 最近发布了一篇博文,解决了持续的可用性问题,并概述了提高弹性的措施。该博文详细说明了 AI 代理推送代码带来的增加的负载,以及向多云基础设施迁移的计划——似乎承认了 Microsoft Azure 存在的局限性。
用户反应大多表示怀疑。许多人质疑所提供数据的透明度,并认为解释与他们经历的停机时间不符。一些人推测,转向多云表明对 Azure 可靠性的不满。
讨论还集中在 AI 驱动的代码贡献对平台造成的压力,以及 GitHub 是否优先考虑新业务(AI 训练数据)而非现有用户体验。 联邦锻造(例如 Forgejo)等替代方案被认为是未来的可能性,提供更大的控制权和可靠性。 尽管承认 GitHub 过去的扩展成就,但许多人仍然持批评态度,而另一些人则建议考虑到前所未有的增长和复杂性,给予一些宽容。
相关文章
原文
I wanted to give an update on GitHub’s availability in light of two recent incidents. Both of those incidents are not acceptable, and we are sorry for the impact they had on you. I wanted to share some details on them, as well as explain what we’ve done and what we’re doing to improve our reliability.
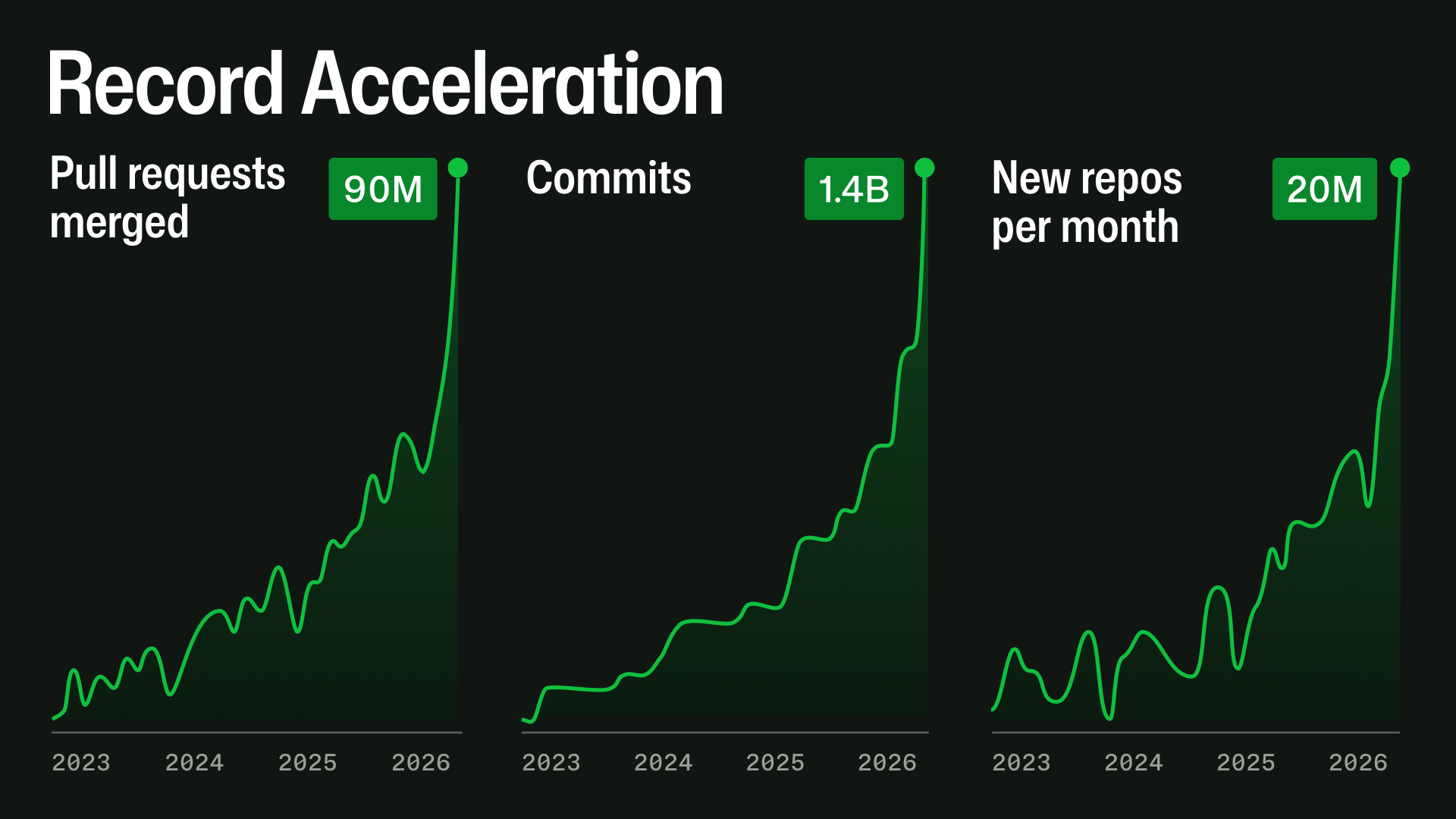
We started executing our plan to increase GitHub’s capacity by 10X in October 2025 with a goal of substantially improving reliability and failover. By February 2026, it was clear that we needed to design for a future that requires 30X today’s scale.
The main driver is a rapid change in how software is being built. Since the second half of December 2025, agentic development workflows have accelerated sharply. By nearly every measure, the direction is already clear: repository creation, pull request activity, API usage, automation, and large-repository workloads are all growing quickly.
This exponential growth does not stress one system at a time. A pull request can touch Git storage, mergeability checks, branch protection, GitHub Actions, search, notifications, permissions, webhooks, APIs, background jobs, caches, and databases. At high scale, small inefficiencies compound: queues deepen, cache misses become database load, indexes fall behind, retries amplify traffic, and one slow dependency can affect several product experiences.
Our priorities are clear: availability first, then capacity, then new features. We are reducing unnecessary work, improving caching, isolating critical services, removing single points of failure, and moving performance-sensitive paths into systems designed for these workloads. This is distributed systems work: reducing hidden coupling, limiting blast radius, and making GitHub degrade gracefully when one subsystem is under pressure. We’re making progress quickly, but these incidents are examples of where there’s still work to do.
What we’re doing
Short term, we had to resolve a variety of bottlenecks that appeared faster than expected from moving webhooks to a different backend (out of MySQL), redesigning user session cache to redoing authentication and authorization flows to substantially reduce database load. We also leveraged our migration to Azure to stand up a lot more compute.
Next we focused on isolating critical services like git and GitHub Actions from other workloads and minimizing the blast radius by minimizing single points of failure. This work started with careful analysis of dependencies and different tiers of traffic to understand what needs to be pulled apart and how we can minimize impact on legitimate traffic from various attacks. Then we addressed those in order of risk. Similarly, we accelerated parts of migrating performance or scale sensitive code out of Ruby monolith into Go.
While we were already in progress of migrating out of our smaller custom data centers into public cloud, we started working on path to multi cloud. This longer-term measure is necessary to achieve the level of resilience, low latency, and flexibility that will be needed in the future.
The number of repositories on GitHub is growing faster than ever, but a much harder scaling challenge is the rise of large monorepos. For the last three months, we’ve been investing heavily in response to this trend both within git system and in the pull request experience.
We will have a separate blog post soon describing extensive work we’ve done and the new upcoming API design for greater efficiency and scale. As part of this work, we have invested in optimizing merge queue operations, since that is key for repos that have many thousands of pull requests a day.
Recent incidents
The two recent incidents were different in cause and impact, but both reflect why we are increasing our focus on availability, isolation, and blast-radius reduction.
April 23 merge queue incident
On April 23, pull requests experienced a regression affecting merge queue operations.
Pull requests merged through merge queue using the squash merge method produced incorrect merge commits when a merge group contained more than one pull request. In affected cases, changes from previously merged pull requests and prior commits were inadvertently reverted by subsequent merges.
During the impact window, 230 repositories and 2,092 pull requests were affected. We initially shared slightly higher numbers because our first assessment was intentionally conservative. The issue did not affect pull requests merged outside merge queue, nor did it affect merge queue groups using merge or rebase methods.
There was no data loss: all commits remained stored in Git. However, the state of affected default branches was incorrect, and we could not safely repair every repository automatically. More details are available in the incident root cause analysis.
This incident exposed multiple process failures, and we are changing those processes to prevent this class of issue from recurring.
April 27 search-related incident
On April 27, an incident affected our Elasticsearch subsystem, which powers several search-backed experiences across GitHub, including parts of pull requests, issues, and projects.
We are still completing the root cause analysis and will publish it shortly. What we know now is that the cluster became overloaded (likely due to a botnet attack) and stopped returning search results. There was no data loss, and Git operations and APIs were not impacted. However, parts of the UI that depended on search showed no results, which caused a significant disruption.
This is one of the systems we had not yet fully isolated to eliminate as a single point of failure, because other areas had been higher in our risk-prioritized reliability work. That impact is unacceptable, and we are using the same dependency and blast-radius analysis described above to reduce the likelihood and impact of this type of failure in the future.
Increasing transparency
We have also heard clear feedback that customers need greater transparency during incidents.
We recently updated the GitHub status page to include availability numbers. We have also committed to statusing incidents both large and small, so you do not have to guess whether an issue is on your side or ours.
We are continuing to improve how we categorize incidents so that the scale and scope are easier to understand. We are also working on better ways for customers to report incidents and share signals with us during disruptions.
Our commitment
GitHub’s role has always been to support developers on an open and extensible platform.
The team at GitHub is incredibly passionate about our work. We hear the pain you’re experiencing. We read every email, social post, support ticket, and we take it all to heart. We’re sorry.
We are committed to improving availability, increasing resilience, scaling for the future of software development, and communicating more transparently along the way.
Written by
Vladimir Fedorov is GitHub's Chief Technology Officer, bringing decades of experience in engineering leadership and innovation. A passionate advocate for developer productivity, Vlad is leading GitHub’s engineering team to shape the future of developer tools and innovation with a developer-first mindset.
Before joining GitHub, Vlad co-founded UserClouds, a startup specializing in data governance and privacy. He spent 12 years at Facebook, now Meta, as Senior Vice President, leading engineering teams of over 2,000 across Privacy, Ads, and Platform. Earlier in his career, Vlad worked at Microsoft and earned both his BS and MS in Computer Science from Caltech. He currently serves on the board of Codepath.org, an organization dedicated to reprogramming higher education to create the first AI-native generation of engineers, CTOs, and founders.
Vlad lives in the Bay Area and when not working enjoys spending time outside and on the water with his family.