HTTP caching never quite made sense, until AI tools made it legible enough to actually implement. And the reason it finally mattered: the audience had quietly changed.

I have a jar of screws on my workbench. For years, I would fish through it looking for the right size, usually not finding it.
Last week I sorted them, by type, by thread, by length. I used ChatGPT to help: photographed a handful, asked what I was looking at, got the taxonomy straight. Once I could name them, I could organise them. You can only sort what you understand.
HTTP caching was my jar of screws.

Thirty years of fog
I have been building for the web since the early nineties. Caching was always there, somewhere in the background, doing something. I knew enough to be aware of it, not enough to actually control it. Cache-Control headers, TTL values, edge behaviour, the difference between what a CDN caches and what a browser holds, what gets invalidated when and why. Every time I approached it seriously, I ran into a wall of context I did not quite have.
The documentation exists. The concepts are not secret. But caching is one of those domains where the gap between understanding the vocabulary and being able to apply it correctly is surprisingly wide. I would read, nod, implement something plausible, and move on with lingering doubt.
This year, working with Claude, that changed. The parallel is closer than it sounds. I had the pieces in front of me for years. What I was missing was someone to explain what I was looking at.
New instruments
We went through the whole thing together. What my Cloudflare Workers were actually doing. What headers were being sent and why. What a browser would cache versus what the edge would cache. Where the inconsistencies were. What a coherent strategy would look like for a site like mine: a moderate personal blog with a global readership, running on Ghost, served through Cloudflare.
It took an afternoon. Not because the subject got simpler, but because I had, for the first time, an instrument that could hold the full complexity with me. Ask a question, get an answer calibrated to my exact setup, follow a thread, revise, implement, check. The back-and-forth that used to require either a specialist or weeks of trial and error compressed into something manageable.
The result was a caching strategy I actually understand. Headers that mean what I intend. Edge behaviour that is consistent. Rules I can read back and explain.
The audience had already changed
The reason it finally felt urgent was not vanity metrics or pagespeed scores. It was a shift in who was actually reading.
Human visitors are still there. But a growing share of traffic to a site like mine now comes from crawlers: search indexers, AI training pipelines, retrieval systems that serve content to agents rather than browsers. These systems do not render pages. They do not wait for JavaScript. They send a request, receive a response, and move on. For them, caching is not a convenience. It is the primary mechanism that determines cost, latency, and reliability of access.
If you care about how your content moves through the world now, including through AI systems, you have to care about caching. Not as a performance optimisation for human browsers, but as infrastructure for machine readership.
That reframing changed what I was optimising for. HTML cached at the edge, globally, with consistent headers and predictable expiry. Not because I expect a person in Singapore to shave 200ms off their pageload, but because the next request for that page is more likely to come from a retrieval system than a browser, and the request after that, and the one after that.
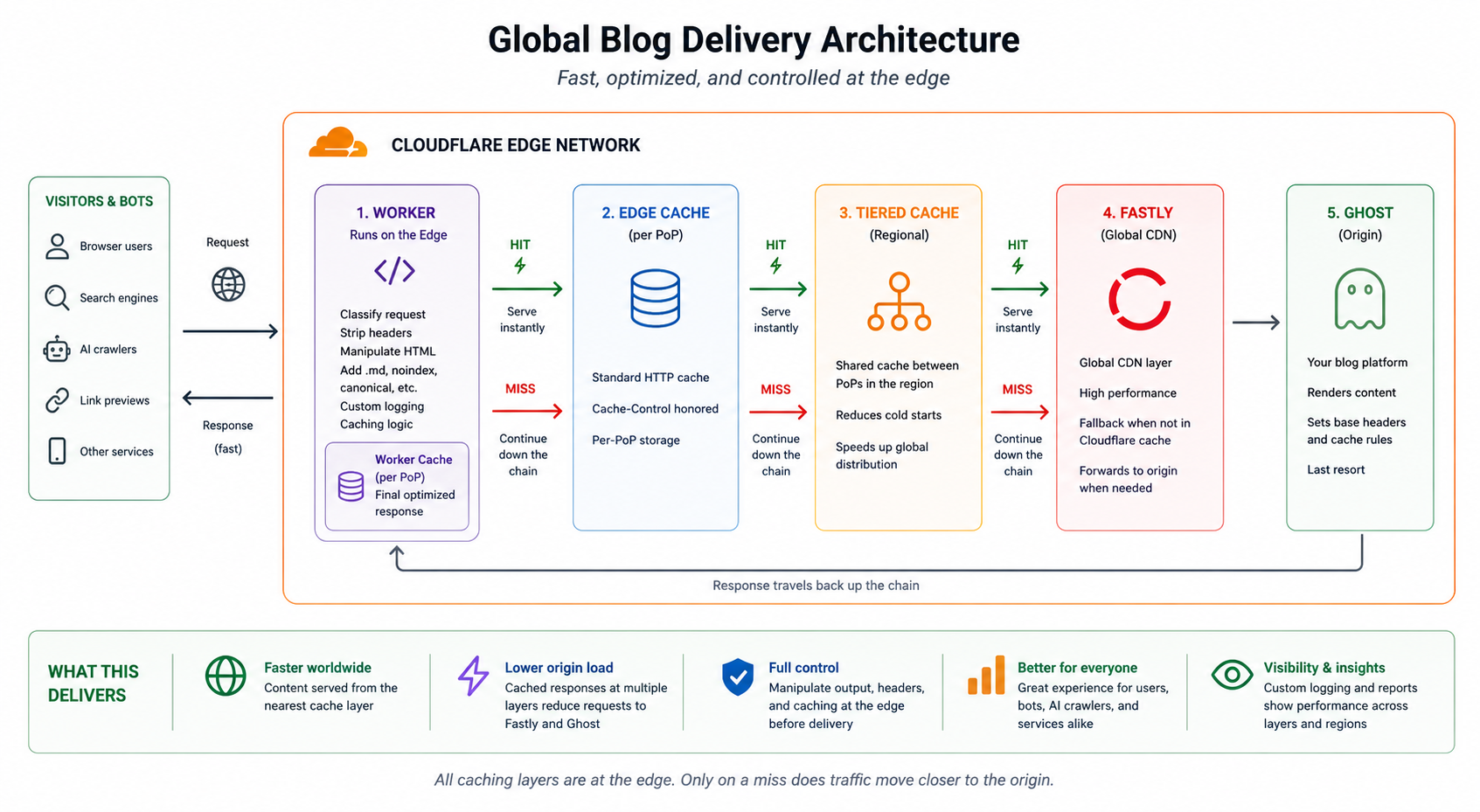
The caching itself is not new. The concepts are decades old. What changed is that I could finally see the system clearly enough to shape it. With the right instrument, a domain that had been opaque for thirty years became workable in a single session.
That is not a small thing. There are other jars of screws on the workbench.
🗒️
My Visitors Are Not All Human. That Is Fine.
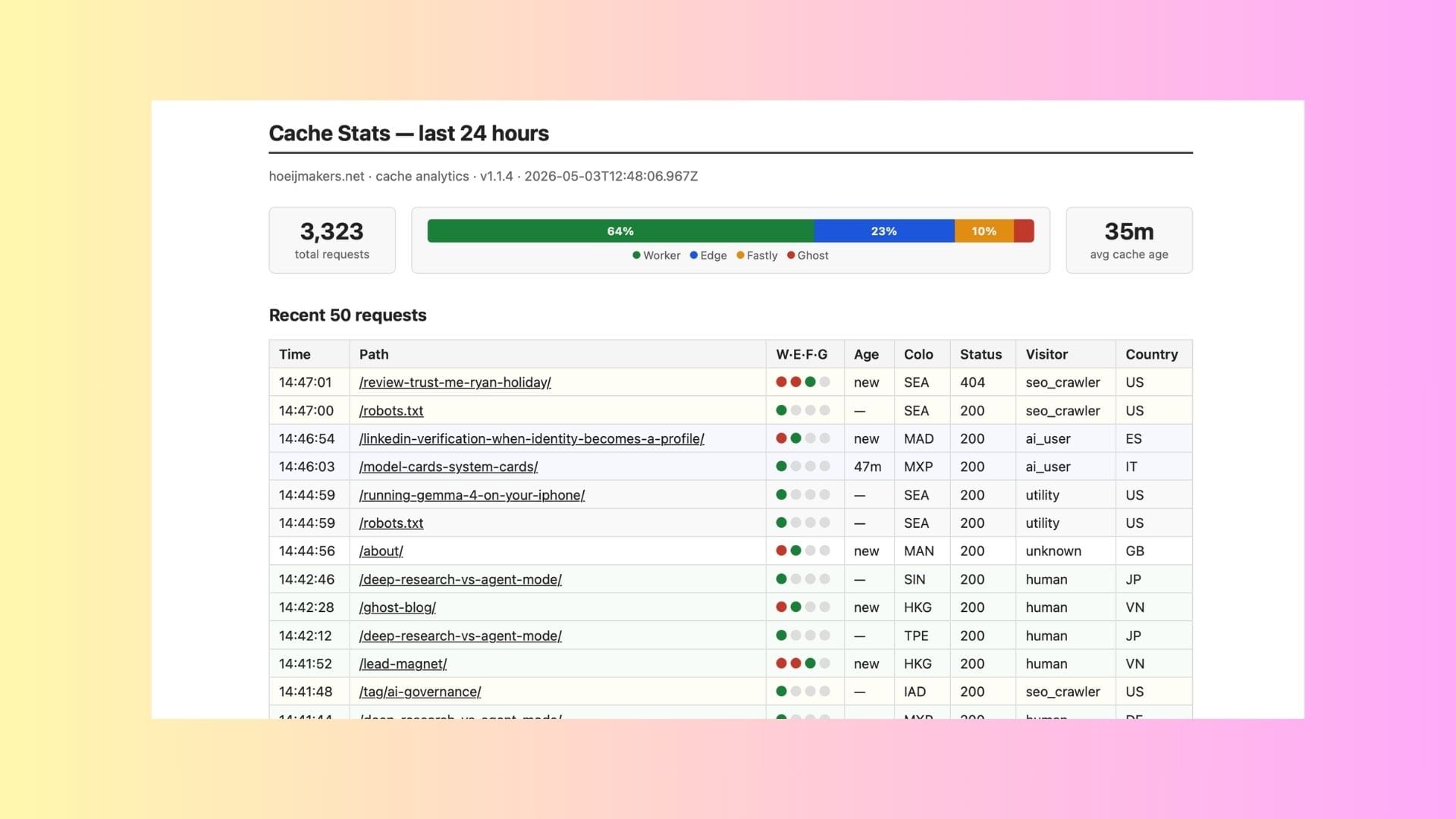
I built a traffic dashboard for my own site. What I found wasn’t alarming, it was interesting. A publisher’s notes on bots, borrowed identities, and editorial agency.
When Bots Become Readers: Publishing in the Age of AI Crawlers
Listening to Matthew Prince on Azim Azhar’s podcast made me reflect on who actually reads my blog. People (like you), machines, or both.
The End of Google Search (as we know it)
Google didn’t warn me. It just erased my blog. What looked like a bug turned out to be a glimpse into the future of search—and it’s not built for us anymore.