C++26 ships with std::simd (P1928), a library-based portable SIMD abstraction. The pitch is seductive: write SIMD code once, compile it for AVX2, AVX-512, NEON, SVE. No more #ifdef __AVX512F__ spaghetti. No more intrinsics. Just std::simd<float> and let the compiler figure out the rest.
A satirical repository by NoNaeAbC recently made the rounds, presenting “6 reasons to use std::simd” — each one a verified demonstration of a real deficiency. I reproduced the benchmarks and dug deeper. It compiles 10x slower, runs slower than scalar loops, defaults to the wrong vector width, and can’t express the operations that actually matter in real SIMD code. The compiler’s auto-vectorizer, the thing std::simd was supposed to replace, beats it on every metric that counts.
The story of std::simd starts with one person: Matthias Kretz, a researcher at GSI Helmholtzzentrum für Schwerionenforschung (the German heavy-ion research center in Darmstadt). Around 2009-2010, Kretz built the Vc library — “portable, zero-overhead C++ types for explicitly data-parallel programming” — to vectorize high-energy physics simulations. Vc was a serious project: 5,000+ commits, used at CERN, and one of the earliest attempts at a clean C++ SIMD abstraction. The idea was right: express parallelism through the type system rather than through intrinsics or new control structures.
Kretz then took Vc’s design to the C++ committee. The proposal went through a remarkably long standardization journey. P0214 (”Data-Parallel Vector Types & Operations”) appeared around 2016 and went through at least nine revisions. It was published as part of the Parallelism TS 2 (ISO/IEC TS 19570:2018) — a Technical Specification, which is the committee’s way of saying “we think this is interesting but we’re not ready to commit.” GCC 11 shipped an experimental implementation under <experimental/simd> in 2021, and Kretz maintained a standalone version at VcDevel/std-simd.
Then came P1928, the proposal to promote std::simd from experimental TS into the C++26 standard proper. This is where things get interesting. The proposal had been in some form of committee discussion for nearly a decade by the time it was voted into C++26. During that decade, the competitive landscape shifted dramatically under its feet. Auto-vectorizers in GCC, Clang, and MSVC improved enormously. ISPC proved that language-level SIMD could generate better code than library-level abstractions. ARM shipped SVE, a scalable-width SIMD ISA that fundamentally challenges fixed-width abstractions. And compiler support for -march=native matured to the point where scalar loops routinely auto-vectorize to the widest available registers.
Kretz’s original vision — write SIMD code once, compile it everywhere — was and remains a worthy goal. The Vc library in 2012 was genuinely ahead of its time. The problem is that std::simd in 2026 is the 2012 solution arriving after the world moved on. The committee spent a decade polishing a library-based approach while compilers solved the easy cases automatically and ISPC solved the hard cases with language-level support. By the time std::simd graduates from experimental to standard, it’s competing against tools that do its job better — and those tools have a decade head start.
While std::simd was working its way through the committee, the open-source ecosystem didn’t wait. Several libraries now occupy the exact space std::simd was designed for — and they do it better, because they can iterate on actual user feedback instead of committee consensus.
Google Highway is the most serious competitor. It bills itself as “performance-portable, length-agnostic SIMD with runtime dispatch.” That last part matters: Highway can detect the CPU at runtime and dispatch to the best available SIMD implementation — SSE4, AVX2, AVX-512, or NEON/SVE — without recompilation. std::simd has no runtime dispatch story at all. Highway is length-agnostic, meaning it works naturally with ARM SVE’s scalable vectors, which std::simd‘s fixed-width model can’t express. The adoption list speaks for itself: Chromium, Firefox, JPEG XL (libjxl), libaom (AV1 codec), Jpegli, libvips. When Google needed portable SIMD for production image and video codecs, they built Highway — not std::simd.
Highway isn’t without problems, though. The API is verbose and idiosyncratic — everything goes through tag-dispatched free functions like hn::Mul(d, a, b) instead of operator overloads, which makes even simple arithmetic read like assembly pseudocode. The runtime dispatch mechanism requires structuring your code around HWY_DYNAMIC_DISPATCH macros that fragment your source across multiple compilation targets. It’s a Google project with Google-scale maintenance, but the bus factor is real — the core development is driven by a small team, and if Google’s priorities shift (as they do), the library’s future gets uncertain. And being length-agnostic means you can’t easily express fixed-width algorithms that depend on knowing the vector size at compile time, which is common in cryptography and codec work.
SIMDe (SIMD Everywhere) takes a completely different approach. Instead of abstracting away intrinsics, it provides portable implementations of them. You write _mm256_shuffle_epi8() and SIMDe makes it work on ARM by translating to NEON/SVE equivalents. This means existing intrinsics code gains portability without a rewrite. It covers the cross-lane operations, shuffles, and width-specific arithmetic that std::simd doesn’t touch. The philosophy is pragmatic: developers already know intrinsics, so make intrinsics portable rather than inventing a new abstraction.
The flip side is that SIMDe locks you into Intel’s mental model. Your “portable” code is still structured around 128-bit and 256-bit fixed-width operations — there’s no way to express scalable-width SVE algorithms natively. The translations from x86 intrinsics to ARM equivalents aren’t always one-to-one; some _mm256_* operations decompose into multiple NEON instructions with overhead that wouldn’t exist if you’d written ARM-native code. You’re also inheriting Intel’s API warts — the inconsistent naming, the implicit width assumptions, the baroque shuffle semantics. SIMDe is an excellent migration tool for getting x86 SIMD code running on ARM, but writing new cross-platform code in Intel intrinsics because SIMDe will translate them is solving portability backwards.
xsimd covers SSE through AVX-512, NEON, SVE, WebAssembly SIMD, Power VSX, and RISC-V vectors. It’s the SIMD backend for the xtensor numerical computing ecosystem and provides batch types similar to std::simd but with a faster iteration cycle and broader architecture coverage. That said, xsimd shares the same library-level optimizer opacity as std::simd and EVE — the compiler sees batch<float, avx2> templates, not vector instructions. The project is tightly coupled to the xtensor ecosystem, which means development priorities track numerical computing use cases rather than the codec/image/HFT workloads where SIMD matters most. Documentation is thin, the community is small compared to Highway, and you’ll be reading source code more than docs when something goes wrong.
EVE (Expressive Vector Engine) deserves special attention because of who built it. Joel Falcou is a C++ committee participant who co-authored papers on SIMD and parallelism — he saw std::simd from the inside and built something different. EVE is a C++20 ground-up rewrite of his earlier Boost.SIMD library (published at PACT 2012), using concepts and modern template techniques. It covers SSE2 through AVX-512, NEON, ASIMD, and SVE with fixed register sizes.
But here’s the thing: EVE suffers from many of the same structural problems as std::simd. It’s still a library-based approach, which means the optimizer opacity problem doesn’t go away — the compiler still sees template instantiations, not SIMD primitives. SVE support is limited to fixed sizes (128, 256, 512 bits), not the dynamic scalable vectors that are the whole point of SVE. There’s no runtime dispatch like Highway provides. Visual Studio support is listed as “TBD” — meaning the most widely used C++ compiler on the most widely used desktop OS can’t compile it. The project’s own README calls it “a research project first and an open-source library second” and hasn’t reached version 1.0, reserving the right to break the API at any time. PowerPC support is partial. And the adoption story is thin — no major production users comparable to Highway’s Chromium/Firefox/JPEG XL roster. EVE is a better-designed std::simd built by someone who knows the committee’s limitations, but a better-designed library abstraction is still a library abstraction. The fundamental problem — that wrapping SIMD in C++ templates costs you optimizer visibility — doesn’t care how elegant your concepts are.
Agner Fog’s Vector Class Library has been a staple for over a decade — thin C++ wrappers around intrinsics with manual control over vector width, used heavily in scientific computing. It predates Vc and has always prioritized predictable codegen over abstraction. VCL’s weakness is the mirror image of its strength: it’s x86-only. No ARM, no NEON, no SVE, no WebAssembly. If your code ever needs to run on Apple Silicon, AWS Graviton, or Android NDK, VCL is a dead end. It’s also essentially a one-person project — Agner Fog maintains it, and when he stops, development stops. The library doesn’t pretend to be portable, which is honest, but it means VCL solves a shrinking problem as the world moves toward heterogeneous architectures.
And then there’s ISPC, which as we’ll discuss later, solves the problem at the language level rather than the library level — and generates better code than all of the above for control-flow-heavy SIMD workloads. ISPC isn’t a C++ library at all — it’s a separate compiler with its own language syntax, which means it requires a separate build step, separate debugging tools, and a mental context switch for developers. You can’t template over ISPC functions, you can’t use C++ classes inside ISPC kernels, and the interop boundary between ISPC and C++ is a flat C ABI. For projects that are 95% C++ with a few hot SIMD kernels, that integration cost is justified. For projects that need SIMD scattered across many small functions, the overhead of maintaining two languages gets painful.
The pattern is clear: every major project that actually needs portable SIMD in production chose a third-party library or a different language. Nobody waited for std::simd. By the time it ships in C++26, these libraries will have a decade of production battle-testing, real user feedback, and cross-platform coverage that std::simd can’t match on day one. And the most damning data point might be EVE itself — a committee member looked at std::simd, decided it wasn’t good enough, and built his own library. Even then, the library approach hits the same walls.
Including <experimental/simd> pulls in deeply nested template machinery — simd.h, simd_x86.h, simd_builtin.h, and friends. A trivial function computing sin on a SIMD vector takes about 2.2 seconds to compile. The equivalent scalar for-loop? 0.2 seconds.
That’s a 10x compile time penalty per translation unit, and this is the experimental header in GCC 14, currently the most mature implementation. Every file that touches std::simd pays this cost. In a trading system with hundreds of translation units processing market data, this adds up to minutes of wasted build time for code that, as we’ll see, runs slower anyway.
The template-heavy implementation also means the error messages are atrocious. Try using std::simd<std::float16_t> with a where() expression and you get 138 lines of template instantiation errors referencing internal types like _SimdWrapper<_Float16, 8, void> and _VectorTraitsImpl. Your source code is 6 lines. A language-level SIMD feature could produce targeted diagnostics. A library-based approach leaks its entire implementation the moment something goes wrong.
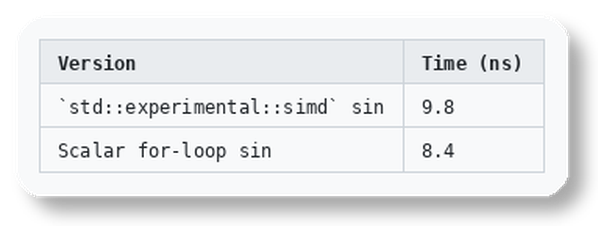
Here’s where it gets embarrassing. With -O3 -ffast-math -march=native, a scalar sin loop auto-vectorizes and beats the explicit std::simd version:

The compiler knows about -fveclib=libmvec and can route scalar math calls through optimized SIMD implementations. The std::simd path doesn’t benefit from the same optimizations because the optimizer can’t see through the template abstraction layer.
This isn’t a one-off with transcendental functions. Consider sqrt(x) * sqrt(x) with -ffast-math. The compiler simplifies this to just x for scalar code — the entire function body becomes a single ret instruction. The std::simd version? It emits actual vsqrtps + vmulps because the optimizer can’t perform algebraic simplification through opaque template function calls:
Any optimization that requires reasoning about mathematical properties — constant folding, strength reduction, algebraic identities — is hindered by the library abstraction. The compiler sees std::experimental::simd::operator*, not “multiplication.” This matters enormously for hot paths.
This is the most consequential design flaw and the one that will silently destroy performance in production code.
std::simd<int>::size() returns the “ABI-safe” native width. On an AVX2 machine with 256-bit registers (8 ints), this returns 4. On AVX-512 with 512-bit registers (16 ints), still 4. The default std::simd type uses 128-bit SSE width regardless of what the hardware actually supports. Meanwhile, a scalar for-loop with -march=native auto-vectorizes to the full machine width.
The benchmark results are brutal:
Net of baseline overhead, the std::simd version takes ~326ns versus ~137ns for the scalar loop. The “portable SIMD” code is 2.4x slower than a plain for-loop. And the std::simd version requires roughly 3x more source code: manual loop tiling, explicit load/store with alignment tags, where() for masking the tail, and a scalar remainder loop.
You can fix this by requesting a specific width — std::simd<int, 8> for AVX2 — but then you’ve hardcoded the width and lost the portability that was the entire selling point. Or you can use std::native_simd<int>, but this maps to the “native ABI” width which, again, is 128-bit on most implementations. The whole abstraction is fighting against you.
The portability story gets worse when you look at ARM. On aarch64 with SVE (Scalable Vector Extension), a scalar for-loop auto-vectorizes using SVE predicated instructions — whilelo, ld1w, st1w, incw — the most efficient SIMD idiom on modern ARM hardware.
The std::simd version compiles fine on ARM, but emits fixed-width 128-bit NEON instructions (ldr q, cmeq, bif, str q) with manually unrolled loops. The generated assembly is roughly 3x longer and doesn’t use SVE at all. The irony is perfect: std::simd‘s portability means it compiles everywhere but optimizes for nowhere. A scalar for-loop with the right compiler flags adapts to the target architecture better than the explicit SIMD abstraction.
This isn’t a compiler maturity issue that gets fixed with better implementations. It’s a structural consequence of the library-based approach. SVE is a scalable-width ISA — the vector length is determined at runtime, not compile time. std::simd is fundamentally a fixed-width abstraction. These don’t compose.
Everything discussed so far concerns element-wise (vertical) operations — lane N of the output depends only on lane N of the inputs. This is the easy part of SIMD. The auto-vectorizer already handles it. Real-world SIMD code is dominated by operations that std::simd doesn’t support at all.
Cross-lane operations — shuffles, permutes, horizontal reductions, byte-level table lookups — are where SIMD programming actually happens in practice. Consider what ffmpeg does in its codec DSP kernels: _mm256_shuffle_epi8 for pixel format conversion, _mm_sad_epu8 for motion estimation, _mm256_permutevar8x32_epi32 for channel deinterleaving, _mm256_maddubs_epi16 for fixed-point multiply-accumulate. None of these have std::simd equivalents.
Width-specific arithmetic is equally absent. Pack/unpack operations (_mm256_packus_epi16) for narrowing 16-bit intermediates to 8-bit pixels, saturating arithmetic (_mm_adds_epu8) for pixel clamping, movemask for extracting comparison results into a bitmask — these are the bread and butter of image processing, video codecs, string search, and compression algorithms. std::simd provides none of them.
A project like ffmpeg could maybe rewrite 5-10% of its SIMD code with std::simd — the trivial element-wise parts that auto-vectorization already handles perfectly. The remaining 90%+ that actually needs hand-written SIMD — codec DSP, pixel format converters, filter kernels — requires operations std::simd doesn’t expose. The abstraction covers the easy cases and abandons you for the hard ones.
The C++ committee chose a library-based approach for std::simd. This decision has consequences that no amount of implementation quality can overcome.
No optimizer integration. The compiler sees template instantiations and function calls, not SIMD primitives. It cannot simplify, constant-fold, or instruction-schedule through the abstraction. The assembly examples above aren’t bugs — they’re the inherent cost of wrapping intrinsics in templates.
No type system support for alignment. SIMD code cares deeply about whether a pointer is 16-byte, 32-byte, or 64-byte aligned. In std::simd, alignment is specified via runtime tags (element_aligned, vector_aligned) at load/store time. It’s not part of the type, so the optimizer can’t propagate alignment information through function boundaries. What we actually need is something like aligned_ptr<float, 64> that the type system can reason about.
Integer promotion still breaks everything. int8_t + int8_t produces int32_t in C++. This is one of the oldest pain points for SIMD programmers working with image data, where 8-bit and 16-bit arithmetic dominates. std::simd inherits this problem because it’s a library on top of the language, not a fix to the language. Writing a pixel blending operation with std::simd<uint8_t> means fighting integer promotion at every step.
No SIMD control flow. Real SIMD code needs predicated execution — “do this operation only on lanes where the mask is true.” ISPC, Intel’s SPMD compiler, makes this a language-level construct and generates excellent code. std::simd offers where(mask, v) = expr, which is a poor library-level approximation. It can’t express early exit, divergent branches, or predicated memory access patterns naturally.
The frustrating part is that the problems are well-understood. SIMD programmers have been asking for the same things for years, and none of them are in std::simd.
Fix integer promotion for narrow types. This is the single oldest pain point in SIMD C++ code. You’re processing 8-bit pixels, doing arithmetic that should stay 8-bit, and C++ promotes everything to int:
If uint8_t + uint8_t produced uint8_t, half the misery of writing SIMD image processing code would evaporate. This is a language fix, not a library feature. std::simd inherits the promotion rules because it’s built on top of the language, not a fix to it.
Make alignment part of the type system. Right now, alignment is invisible to the optimizer across function boundaries. You alignas(64) your buffer, call a function, and the callee has no idea:
This would help both hand-written SIMD and auto-vectorization. The compiler could propagate alignment through call chains, across virtual dispatch, through function pointers. std::simd uses runtime tags (element_aligned, vector_aligned) at load/store time, which is the worst of both worlds — verbose source code with no optimization benefit across boundaries.
Provide portable shuffle/permute primitives. This is the single most impactful missing feature. Cross-lane operations are where real SIMD programming happens, and std::simd has nothing for them:
Even this one primitive — a portable byte shuffle — would cover pixel format conversion, channel deinterleaving, LUT-based parsing, and half the operations in string search algorithms. Instead, std::simd only supports element-wise operations that the auto-vectorizer already handles.
Fix aliasing at the language level. The optimizer needs to know when two pointers don’t alias, and the current options are terrible:
Without aliasing information, the compiler can’t vectorize aggressively — it must assume out might overlap with a or b and insert runtime checks or fall back to scalar code. Every C++ SIMD programmer has fought this. __restrict__ works but it’s non-standard, not part of the type system, and doesn’t compose with templates or generic code. A language-level noalias or restrict qualifier that the committee could standardize would do more for vectorization than std::simd ever will.
Look at what ISPC did. ISPC solved the “portable SIMD” problem a decade ago by making it a language-level concern. Here’s what ISPC code looks like versus std::simd:
That foreach is not a regular loop — it executes across SIMD lanes with proper predicated masking. The while loop with a divergent condition generates masked execution automatically. ISPC compiles this to AVX2, AVX-512, or NEON with no source changes and generates better code than either intrinsics or std::simd. The C++ committee could learn from ISPC’s design instead of shipping a template library that loses to a for-loop.
That’s the question I keep coming back to. The intrinsics programmers working on codecs, image processing, and HFT market data parsers need precise control over shuffle patterns, lane widths, and instruction selection. std::simd doesn’t give them that. The application programmers writing scalar loops already have auto-vectorization, and it produces better code than std::simd with less source complexity.
std::simd occupies an awkward middle ground — too high-level for the people who need SIMD, too low-level for the people who don’t. It’s a portable abstraction that compiles everywhere and optimizes nowhere. The committee shipped a solution to a problem that auto-vectorizers solved years ago, while ignoring the problems that actually keep SIMD programmers reaching for intrinsics.
The compiler’s auto-vectorizer is not perfect. But it’s improving every release, it works on existing code without modification, it adapts to the target architecture at compile time, and it lets the optimizer do what optimizers do best — reason about your code as a whole. std::simd takes that away by hiding the code behind templates and gives nothing meaningful in return.
If you’re writing SIMD code for performance-critical systems, keep using intrinsics for the hard parts and let the auto-vectorizer handle the easy parts. That strategy has worked for twenty years and nothing in C++26 changes the calculus.