I'm in the Maasai Mara about half the year, in three-month stretches. Animals out the front of the lodge, motorcycles, friends in the Maasai villages, kids who think a drone is the funniest thing they have ever seen. That's one half of my year. The other half is sixteen-hour days in front of a terminal, Silicon Valley hacker brain on Africa time. Both real, both consuming attention.
The first half is a constant flood of footage from the iPhone, the DJI Pocket, the drone, the Nikon Z8, and lately the Ray-Ban Metas too. There's always something being recorded. Every photographer or videographer I know is sitting on the same problem: an archive that grows faster than they can edit it. The second half is why mine never gets touched.
 Airport security somewhere between Nairobi and Spain. Two trays of cameras, headphones, drone bits, batteries, SSDs, more cables than anyone needs. Most of it records something. Almost none of what they record gets touched again any time soon.
Airport security somewhere between Nairobi and Spain. Two trays of cameras, headphones, drone bits, batteries, SSDs, more cables than anyone needs. Most of it records something. Almost none of what they record gets touched again any time soon.
Three months ago the lodge's social channels went dark. Not for lack of content; the lodge has years of raw footage across multiple SSDs. The bottleneck was editing time, and my time disappeared. Claude Code with Opus 4.5 (and then 4.6) hit the point in February where you could leave agents running for hours and come back to merged PRs. KaribuKit was going live with its first paying property in the same window. I stopped sleeping properly, started running three or four agents in parallel in the background, and the months when I would have cut reels turned into months when I shipped software instead.
So one weekend I sat down to fix it. The first thing I tried was wrong.
The wrong layer
The initial pitch (to myself, after about an hour of research) was a SaaS stack: Eddie AI for iterative editing, Higgsfield MCP for generative B-roll, Submagic for captions, Buffer for cross-posting. About $140 a month, slick on paper.
Two problems showed up before I ran any of it.
First, generative AI video has no place on a real travel brand. Guests pay $300 a night and up to see the actual place, and mislabeled AI shots equals TripAdvisor crucifixion. Higgsfield out.
Second, 3-5 posts a week was aggressive for me, and the realistic floor was more like 2-3. The pitch was optimistic in a way that would have me failing by week two.
Then I remembered I already own DaVinci Resolve Studio, and Resolve 21 ships IntelliSearch (semantic clip search), Smart Bins (auto-organizing folders), and Voice to Subtitle that produces 90-95% accurate captions on the timeline. That's roughly 70% of what Eddie sells, so Eddie was out too.
What I was left with was Claude Code driving Resolve via the open-source DaVinci Resolve MCP, with ElevenLabs handling voiceover on informational clips where it earned its place, and the cost had dropped from $140 a month to $22.
But the deeper thing only landed once I tried to actually use any of this. Every AI video editor on the market assumes your footage is already labeled. Mine is IMG_*.mov and DJI_*.mp4 across folders with names like Mara june 2024 backup final FINAL. Eddie can search by transcript, but none of these tools can find "the elephant on the hill at golden hour" against an unlabeled archive.
The AI editor is solving the wrong problem. Or more precisely, it's solving the second problem; the first problem is the index.
The question
I asked it out loud: how does the agent know what's in each clip?
There's no answer for an unlabeled archive. You can throw transcripts at it, GPS coordinates, filenames, parent folders. None of that gives you "the wide shot at sunrise with the giraffe in the frame" unless something has actually looked at the pixels.
The leverage is upstream. Build the index first, make the archive queryable in English, and the editor on top becomes a thin layer doing what it was designed to do.
So I built the index, locally.
The build
This is the kind of AI-native build I do for clients at SimbaStack, except I was both the client and the engineer this time, which made the decision tree a lot shorter.
Four constraints set the shape:
- Local-first. The Mara Hilltop archive is on physical SSDs, and most of the personal stuff is on my laptop. Cloud upload was a non-starter both for cost (thousands of files, many gigabytes per clip) and for not handing the entire visual record of my life to a third party.
- Sidecars, not a central database. A
.description.mdper clip, living next to it, plain text and grep-able. Survives if my indexer breaks tomorrow, and travels with the data when files move between drives. - One vision call captures everything. The expensive operation is the vision pass over the extracted frames, so anything I might want to know about a clip later has to come out of that one call. The schema is exhaustive on day one: rating, technical quality, lighting, time of day, color palette, audio quality, people count, keywords, faces, location, transcript, prose description. All of it in one shot.
- Three vision backends. Claude via my Max subscription's CLI as default (zero marginal cost), the Anthropic API for speed when I need it, and a local backend pointed at LM Studio for the bulk pass. The local one is the one that matters.
The per-clip pipeline:
ffprobefor metadata.exiftoolfor GPS lat/lon/altitude. Works on iPhone, DJI Pocket, drone footage, all the same.- Reverse-geocode via Nominatim. Free, rate-limited, no API key.
ffmpegextracts five evenly-spaced frames at 1920px.- WhisperX transcribes with word-level alignment and pyannote speaker diarization. Hindi, English, Swahili, 97 languages.
insightfacedetects faces and stores 512-dim ArcFace embeddings in a centralized SQLite face DB for cross-archive person queries later.- Vision model reads the frames, transcript snippet, and folder context, and returns YAML frontmatter plus a prose description.
- Sidecar written to disk.
Here's what that looks like on a real clip from the Mara Hilltop archive.
 One frame from
One frame from IMG_1103.MOV. Ellie on the deck of one of the luxury tents at the lodge, midday. None of that context lives in the filename.
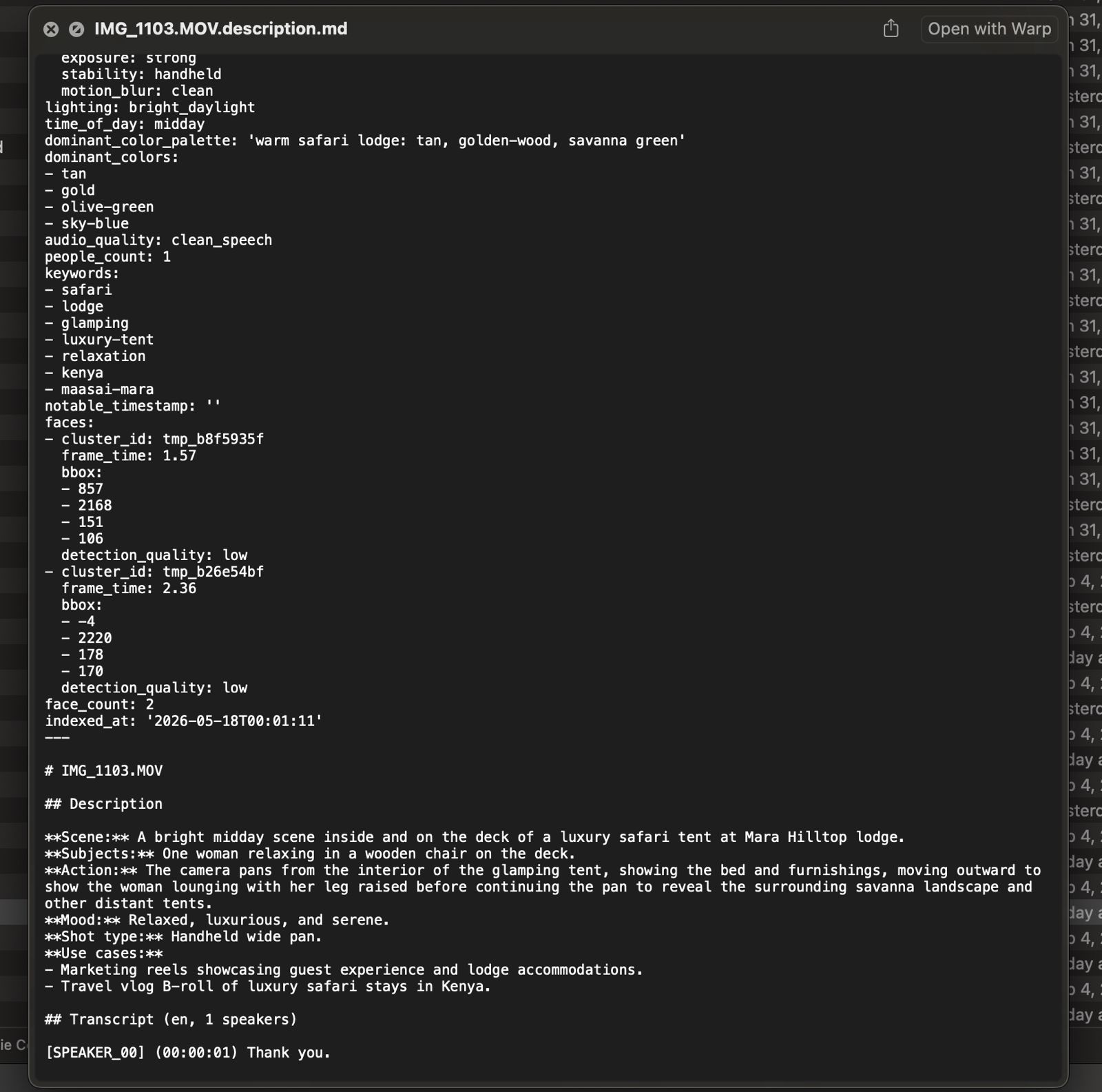 The sidecar Gemma wrote for the same clip. YAML on top (lighting enum, time-of-day enum, color palette, face embeddings, GPS), prose
The sidecar Gemma wrote for the same clip. YAML on top (lighting enum, time-of-day enum, color palette, face embeddings, GPS), prose ## Description below. It picked up the safari-tent setting, the camera pan from interior to savanna, the shot type, and suggested two use cases (marketing reels and travel-vlog B-roll). The filename had IMG_1103.MOV; the sidecar has the rest of what I needed to find it again.
The whole thing is a Claude Code skill at ~/.claude/skills/video-index/, about 1,400 lines of Python. Claude Code wrote almost all of it. My work was the architecture, the prompts, the schema design, and the bug triage when things went wrong.
The absurdity
This is the part that actually surprised me.
I bought a 16-inch MacBook Pro M1 Max with 64GB of RAM in 2021, and the reason had nothing to do with LLMs. I'd been hitting 32GB limits on my previous machine for a while. A messy hacker brain running hundreds of Chrome tabs alongside DaVinci Resolve, Slack, Discord, and Drive was too much for pre-unified-memory hardware to handle without paging constantly. I maxed out the RAM on the new M1 Max because the old one wouldn't stop killing my workflow and I had the money to fix it.
Five years later, that same laptop is running Gemma 4 31B Q4 in LM Studio against a year of video footage.
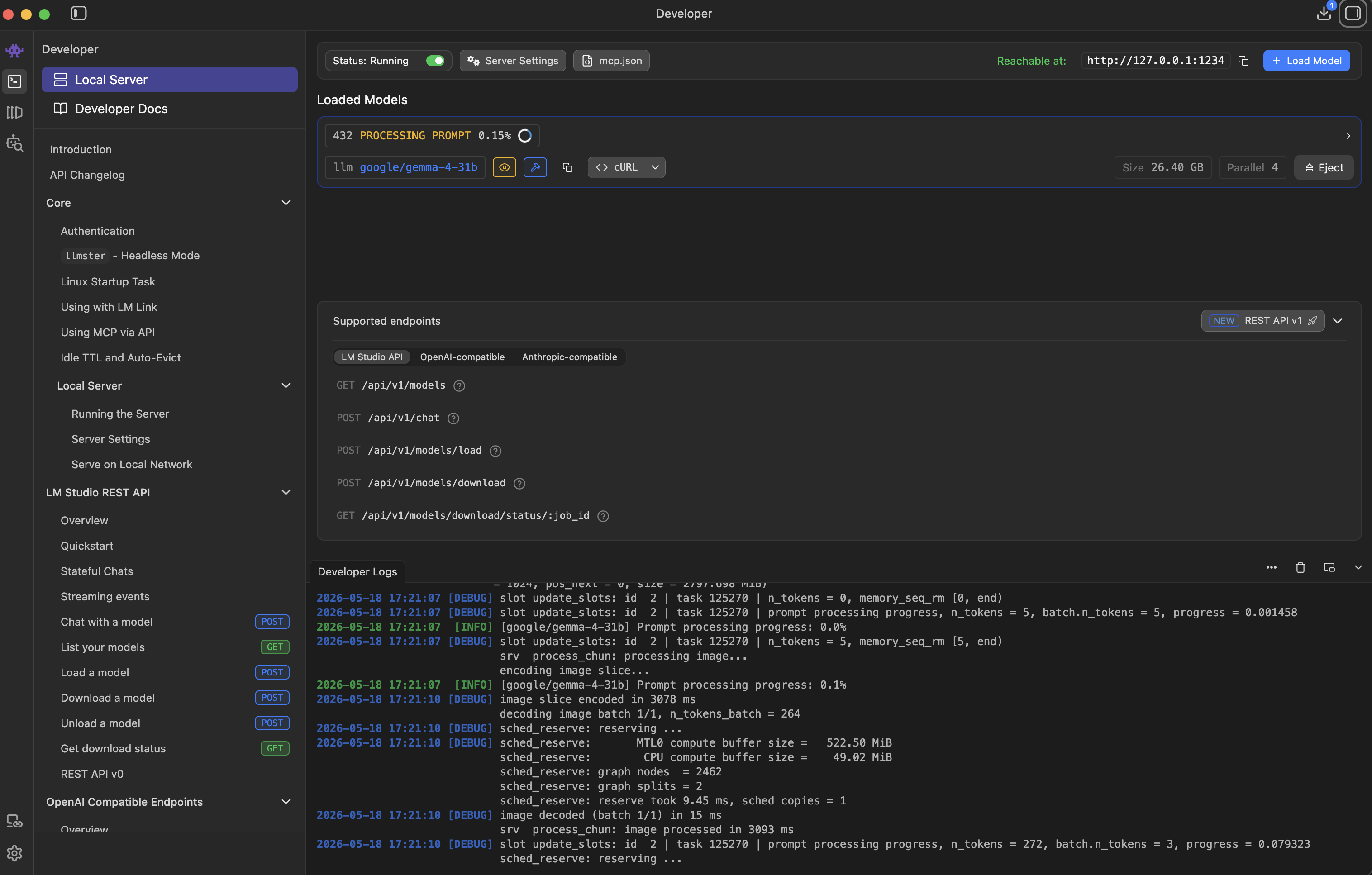 LM Studio with Gemma 4 31B Q4 loaded. 28.40 GB of model in memory, REST API at
LM Studio with Gemma 4 31B Q4 loaded. 28.40 GB of model in memory, REST API at 127.0.0.1:1234. The bottom panel is the server log during a real bulk run, encoding frames one clip at a time.
The bulk run pushed the laptop past where 64GB of RAM alone would carry it. Activity Monitor reported 50.89 GB of swap at the peak.
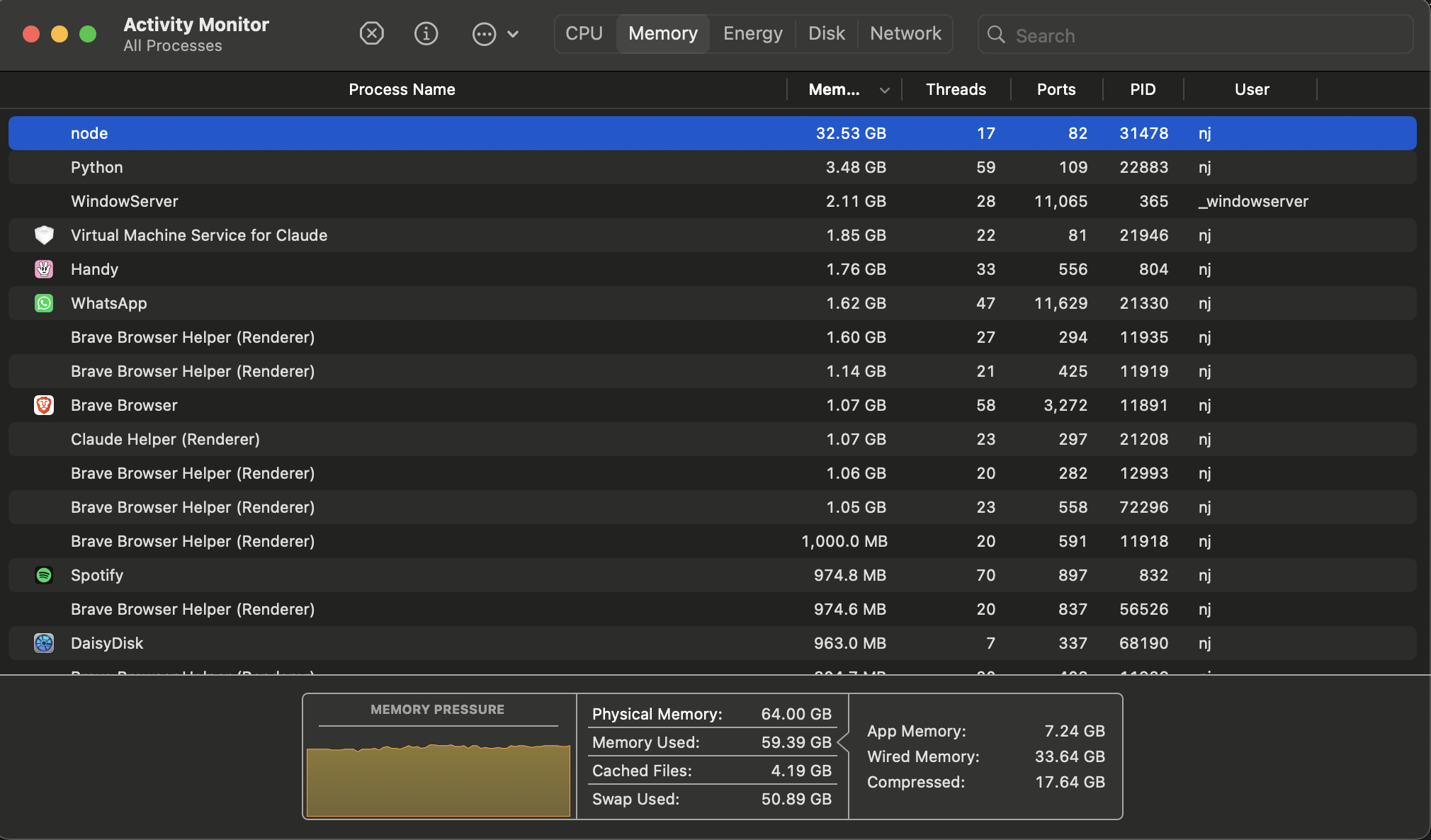 64 GB of physical RAM, 50.89 GB of swap used. Memory pressure in the yellow band, the kind of state you absolutely should not run on a normal Tuesday. Apple's swap is designed for it, and the fans were loud.
64 GB of physical RAM, 50.89 GB of swap used. Memory pressure in the yellow band, the kind of state you absolutely should not run on a normal Tuesday. Apple's swap is designed for it, and the fans were loud.
I Googled whether that would damage the SSD, and apparently for a day or two it's fine. Don't make it your normal operating state, but a weekend of pushing the machine hard is well within tolerance. My laptop ran hot, the fans spun up, and it kept producing sidecars while I worked on other things.
The M1 Max 16-inch is, honestly, legendary. People in the Mac community talk about it that way for good reason: five years on, it's running 31B-parameter models at usable speed with the kind of headroom that should not exist on hardware this old. I expect another three to five years out of this thing, comfortably, because local LLMs only get more efficient and the hardware is the floor, not the ceiling.
I bought it for Chrome. It's running a model that didn't exist when I bought it.
Four bugs, four lessons
The build was mostly Claude Code holding the pen. The interesting work was the four times it almost shipped something wrong.
WhisperX 3.8 broke its diarization API between when I last touched it and now. Two breaking changes had landed: whisperx.DiarizationPipeline moved to the whisperx.diarize submodule, and the constructor kwarg use_auth_token was renamed to token (inherited from pyannote 3.x). The fix was signature introspection: the script tries token= first and falls back to use_auth_token= if the constructor raises a TypeError, so it survives the next API shuffle automatically. Lesson: when shelling out to AI libraries that move fast, defensive constructor calls are cheap insurance.
The Claude CLI returns permission errors as successful responses. On the first test of the CLI backend, all four sidecars came back identical with the text "I need permission to read the image frames...", and the script's success check passed because exit code was 0 and the output wasn't empty. The cause was that in non-interactive mode without --permission-mode bypassPermissions, the CLI returns the permission-denial text as the response body instead of prompting, which means the failure mode looks exactly like success unless you string-match for it. The fix was adding the flag plus a defensive check that flags any short response containing "I need permission" as an error rather than a description. Lesson: when scripting AI tools, the non-interactive permission flow is where silent failures hide.
Gemma returned people_count: "many" instead of an integer. My vision prompt literally said integer or the string "many" if >10. Gemma followed instructions correctly; the bug was schema design. The fix was a stricter prompt (integer 0-99 with explicit guidance to estimate) plus a coercion in the parser for the legacy "many" responses. Don't union-type schema fields. Pick always-int or always-string, never "int or this one specific string," because every downstream consumer pays for the choice.
The motorcycle clip that shouldn't have been culled. My initial cull prompt was photographer-portfolio-shaped: heavy motion blur, soft focus, and jittery stability got rated cull. Technically correct. Then I tested it on a handheld nighttime motorcycle clip from a Spain trip and it culled it. I caught it: that's a fun memory, the blur is the vibe. I reframed the cull criteria to "not a real recording" only (lens cap, pocket footage, two-second test clips, fully clipped exposure), not "imperfect capture." Lesson: photo archives cull aggressively, video memories cull permissively. Same schema, different criteria; be explicit about which mode you're in.
The actual take
Three things I now believe more strongly than I did a week ago.
Enum constraints beat instructions for confabulation prevention. I tested Gemma 4 E4B on a coworking-space photo I'd taken at night, and it described the scene as "brightly lit, abundant natural light, floor-to-ceiling windows" — except the windows were pitch black outside, because it was night. Then I tested 31B with a structured schema prompt that forces the model to pick from golden_hour | bright_daylight | overcast | dim_interior | nighttime | mixed | unclear, and both thinking-off and thinking-on recovered nighttime correctly. A model can lie about open-ended prose, but it can only mis-pick from an enum, never invent a new value. Use schemas, not instructions.
Local 31B with structured prompts closes most of the gap to cloud. Gemma 4 31B Q4 thinking-off against a structured schema produces output that's hard to distinguish from Sonnet 4.6 on most of my test clips. The cloud premium earns its keep on the hard 10-20%. Bulk indexing at scale (thousands of clips overnight) should run local; cloud is the re-rate pass on clips local flagged as review. That two-tier setup is the one that scales.
AI video editors are pitched one layer too high. The valuable layer is the index. Once your archive is queryable in plain English ("show me handheld interior clips from Mara, golden hour, with people, longer than 8 seconds"), the editor on top is straightforward. Most of the AI-editor space is competing for the surface above an index that doesn't exist, and the index is the prerequisite they're all skipping past.
What's next
Looking back, the thing that kept this from getting fixed sooner wasn't really time. I had every AI superpower currently available pointed at the work side of my life: Claude Code refactoring codebases overnight, Codex writing most of my pull requests, the agentic stack I'd just spent three months using to ship KaribuKit. On the editing side, I was using none of it. The not-getting-to-it had become its own small, low-grade frustration that lived in the back of my head all year, the kind of thing you notice every time you open a folder on the SSD and close it again without doing anything. What clicked one Saturday wasn't that I needed to find time. It was that the editing problem was a tooling problem, and tooling is the one kind of problem I happen to be well-equipped to fix right now.
This weekend I'm building the editor: Claude Code as the orchestrator, DaVinci Resolve MCP for the cuts, ElevenLabs for voiceover on informational clips. There's one hard rule baked into the tooling: the voice clone is for utility content only. Directions, room descriptions, multilingual versions, factual stuff I'd say in person anyway. Never for testimonials or founder messages. Disclosure laws are real in 2026, and trust in a hospitality brand is too easy to lose.
The index makes all of that tractable. Without it, I would still be scrubbing through 47GB of DJI Pocket footage looking for the sunrise wide.
For now: a year of Mara Hilltop footage is queryable in English on a five-year-old laptop. Cost was a weekend of my time and 50GB of swap. The remaining years across older SSDs are next.
A fair check on all of this: Mara Hilltop's social channels are still dead today. The indexer solves only half the problem (finding the right clip); the editor that turns those clips into finished reels is the other half, and that's the part I'm building this weekend. If it works, the channels light back up and I write part two. If it doesn't, I write about why.
In all honesty, the right answer here might be to hire someone. Finding an editor with the right sensibility for Mara Hilltop (warm, observational, no over-cut MTV-energy reels) is harder than writing another skill. If you know someone who works in that register, send them my way.
The skill is open at ~/.claude/skills/video-index/. If you're working on something similar (indexing personal archives, getting a local model to do real archival work, building agents that drive editing tools), I'd be glad to compare notes.
— NJ
Building KaribuKit (AI-native PMS for hospitality), running Mara Hilltop (eco-lodge in the Maasai Mara), and consulting through SimbaStack.
#local-llm#claude-code#video-archive#mara-hilltop#simbastack