When Intel designed the 80386, they gave it a trick for hiding memory latency: Early Start. Instead of waiting for an instruction to reach its memory micro-op, the 386 begins the next instruction's address work — effective address, segment relocation, the bus cycle — in the last cycle of the current instruction. Intel put it at about 9% of overall performance. It is also the source of the POPAD bug.
The z386 FPGA core I released in May ran the original 386 microcode but didn't have early start. Over the last month I added it along with a series of other optimizations, and z386 now reaches ao486-class performance:
| core | Doom (FPS) | 3DBench | Landmark |
|---|---|---|---|
| z386 0.1 (May) | 16.6 | 33.7 | 147 |
| z386 0.4 (June) | 23.0 | 44.5 | 170 |
| ao486 | 21.0 | 43.8 | 204 |
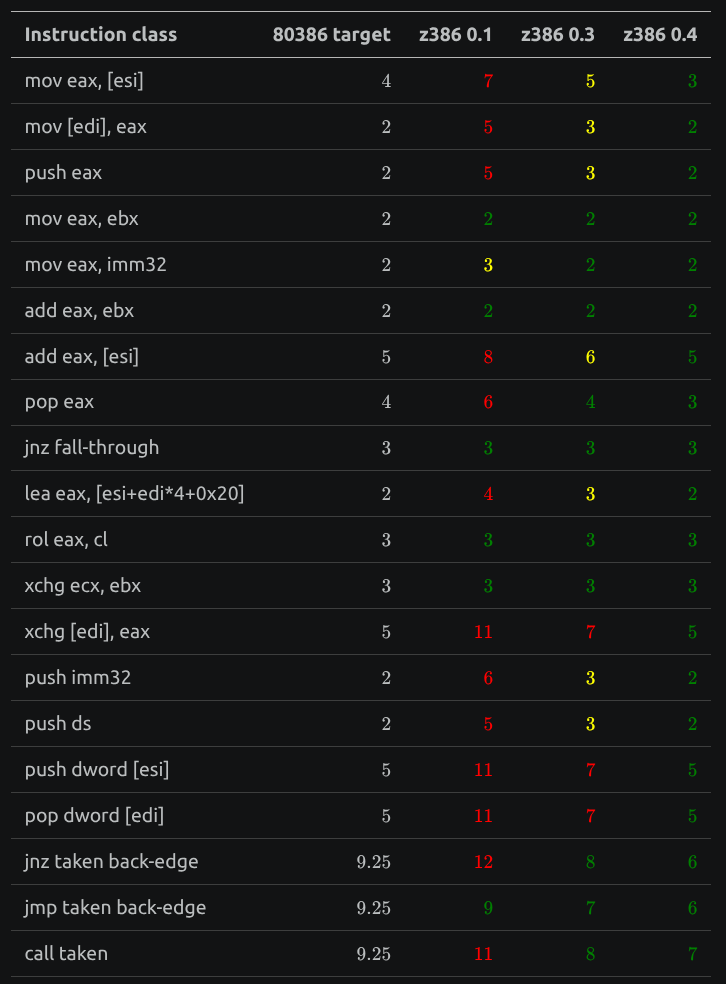
Doom (original, max details) went up ~39% (16.6 → 23.0), past ao486's 21.0, and the 16-bit 3DBench now edges past ao486 too. The board clock is unchanged from v0.1's 85 MHz, so the gains came entirely from cutting CPI, doing more work per clock. Per-instruction, z386 went from well above the 386's cycle counts to at or below them on nearly everything:

The memory pipeline post earlier in this series introduced Early Start as a concept. This post is about building it on an FPGA, plus the rest of the CPI work that got z386 to parity.
Early Start
Intel discussed Early Start in Slager's ICCD '86 paper, "Performance Optimizations of the 80386". The clue to how it works is in the microcode. Here is the entry for an ALU instruction that reads a memory operand (ADD reg, [mem]):
; ADD/OR/ADC/SBB/AND/SUB/XOR m,r
04A EFLAGS -> FLAGSB FLGSBA RD 9
04B DLY
04C OPR_R -> TMPB WRITE_RESULT JMP UNL
04D TMPB SRCREG +-&|^
The interesting thing is that the first micro-instruction, 04A, already issues RD — it starts the memory read. No micro-instruction before it computes the effective address, adds the segment base, or checks the limit. Address generation is implicit, done by hardwired logic. A concrete example makes this clearer:
add eax, 16
mov ebx, [eax+4]
In execution order, the microcode runs as in the table below. Line 023 runs the ALU (EAX + 16) and asserts RNI — "run next instruction" — so the machine is already committed to starting MOV r,m next. Line 024 writes the result back into EAX, and that same 024 cycle is the early-start window for the next instruction (the load):
| cycle | add eax, 16 |
mov ebx, [eax+4] |
|---|---|---|
| 1 | 023: EAX + 16 in the ALU, RNI |
— |
| 2 | 024: write EAX (= old EAX + 16) |
early-start window: peek at the next instruction, forward the just-produced EAX, compute EA = EAX + 4, relocate, and issue RD |
| 3 | — | 019: RD microcode |
| 4 | — | 01A: DLY data arriving, write OPR_R |
| 5 | — | 01B: RNI |
| 6 | — | 01C: OPR_R -> EBX |
This overlap starts the memory access at least one cycle earlier, cutting load/store latency. The subtlety is that the previous instruction's last micro-instruction may write back to a register, creating a data hazard. Here EAX is being written in that very cycle, so its new value isn't in the register file yet. The fix is the usual one — a forwarding network, so early-start sees the latest value. The 386DX's forwarding network had a corner-case bug that produced the famous POPAD bug: when POPAD is followed by an instruction using [EAX+...], the early-start machinery forwards the wrong value.
Another way to view early-start is coarse pipelining at the granularity of macro-instructions, where the last cycle of the previous instruction (RNI delay slot) is the write-back stage of that instruction, and it overlaps with the next instruction's first cycle, the early-start cycle.
Implementing Early Start
z386 tracks each instruction through a small lifecycle. The two events that matter here are i_pop — the cycle the instruction is pulled from the prefetch queue, which is the previous instruction's RNI delay slot — and i_first, the first cycle of its own microcode. i_pop is exactly the 386's early-start window in cycle 2 above.
So early start, in z386, is: compute the effective address and linear address combinationally at i_pop, forwarding the in-flight register write. The decoder produces the base/index/displacement selectors, and:
wire [31:0] ea_early = calc_ea_core(fwd_onehot_gpr(ea_dec_base_sel_r),
fwd_onehot_gpr(ea_dec_index_sel_r),
...);
fwd_onehot_gpr is the bypass. If the previous instruction's delay-slot writeback targets the EA's base or index register, it substitutes the writeback value (dest_value) for the register-file copy — handling byte, word, and dword writes separately, because a partial write only updates part of the register:
FWD_BLO: fwd_onehot_gpr = {cur[31:8], dest_value[7:0]}; // AL
FWD_W: fwd_onehot_gpr = {cur[31:16], dest_value[15:0]}; // AX
default: fwd_onehot_gpr = dest_value; // EAX
Stack pointers get the same treatment through forwarded_esp, so a push right after an instruction that adjusts ESP still sees the new value. ea_early is then registered into ea_reg at i_pop, ready for the load/store microcode at i_first. Functionally this is exactly the 386's hardwired EA generator, and it reproduces the same forwarding corner cases — including the POPAD one — that the microcode quietly relies on.
With the forwarded GPR and stack pointer ready, the early-start cycle computes the effective address and then the relocation (adding the segment base) to produce the linear address. That path turns out to be a timing hotspot — it took quite a few iterations to fit its length inside the cycle budget.
Further speeding up of memory accesses
Early-start's ~9% is significant, but getting past 30% required more work — most of it shortening the memory-access pipe:
Tightening the store queue. Stores were 3 cycles where the 386 takes 2. The usual way to cut write latency in a CPU is a store queue: instead of writing straight to memory, the CPU buffers the pending write in a small queue. z386 already had a 3-entry store queue, but its interface was too conservative and wasted a cycle. Releasing the delay (the DLY micro-op) earlier recovered that cycle.
Issuing the read/write at i_first. i_first is the first cycle of an instruction, and with early-start most reads and writes naturally issue here. But the old memory pipe sometimes split the TLB lookup and the memory/cache request across two cycles. Folding them both into the i_first cycle saves another cycle on top of early-start.
Here's an example of the memory pipe at work, with no stall if the cache hits:
; ADD/OR/ADC/SBB/AND/SUB/XOR r,m
i_pop forward GPR, set IND(early-EA), relocate
027 RD TLB, cache request
028 DLY tag compare, write OPR_R
029 OPR_R->TMPB OPR_R ready
02A RNI
02B SIGMA->DSTREG
Splitting the cache. Experimenting with cache geometry, I found a 16KB+16KB split design works best — twice the size of the ao486 caches, and with the new memory pipe a simpler PIPT (physically indexed, physically tagged) cache fits better, so I adopted that too. A split cache exploits the fact that code (read by the prefetcher) and data (read by the data path) seldom overlap; and the icache, being read-only, is more area-efficient. The one complication is keeping the two coherent with a snooping protocol — code is written by the data path, when a program is loaded or, more rarely, when it modifies itself.
Early branch redirect
It is not a goal for z386 to be 100% 80386 cycle-accurate. Instead, the goal is accurate behavior, and the original microcode does most of that work. When a little extra logic buys a lot of performance or when an FPGA primitive does the heavy lifting, I take the faster design. The multiplier was one such case, where the FPGA DSP block saved a lot of cycles. Early branch redirect is an example of getting faster than 386 with a bit of area.
For a direct relative branch like jmp rel, call rel, or a taken jcc, the target is just EIP + displacement, fully known at decode with no register or memory dependency. These are often performance-critical, yet the 386 only redirected the prefetcher after the microcode resolved the branch. So z386 now computes the target early at i_first and redirects immediately.
This is not branch prediction. The jcc condition is resolved at i_first from the settled flags, so the target is exact. It just starts the refill earlier. A taken jnz/jmp is now 6 cycles, well below the 386's 9.25, which helps CPI noticeably.
A wider frontend
This is a fun one. In the middle of the CPI improvements, it became clear that one major bottleneck had moved to the frontend: the decode queue empties after every taken branch, and decode-queue-empty was the #1 stall at ~20% of cycles. With the execution side now so much faster, it was draining decoded instructions faster than the frontend could supply them — Dhrystone alone takes about 35,000 branch flushes, around 6 cycles each, and most of those cycles are the frontend catching back up.
So I rebuilt the frontend to be wider and shallower. There are two queues between memory and execution — a prefetch queue of raw instruction bytes, and a decoded-instruction queue the execution unit pops from — with a decoder in between. All three got faster.
A 32-byte prefetch queue, refilled a whole line at a time. The queue is eight 32-bit words (32 bytes) of raw code, and on an instruction-cache hit a full 16-byte line is written into it in a single cycle — up to four queue words at once. The point is refill bandwidth: after a branch flushes the queue, it fills back up in a couple of cycles instead of trickling in a dword at a time.
A single-cycle structural decoder. The decoder looks at a 4-byte window at the queue head (opcode, modrm, sib, …) and, in the common case, produces a decoded instruction combinationally in one cycle. Opcode-only and opcode+ModR/M forms decode together. Only the rarer opcode+ModR/M+SIB form spends a second cycle. So the decoded-instruction queue refills as fast as the prefetcher delivers bytes; there is no deep decode pipeline to drain and refill on every branch.
This is basically moving the prefetcher and decoder towards the 486 frontend design. The 486 decoder (D1) can decode "up to 3 instruction bytes" in a single cycle (The i486 CPU: Executing Instructions in One Clock Cycle), including the opcode+modrm+sib case. So z386 is still a bit slower.
Together these took decode-queue-empty from ~20% down to under 10% of cycles.
Maintaining a high clock speed
Optimizations cost area and, worse, can hurt Fmax — and if the clock drops too far, an optimization defeats its own purpose. z386 held its clock through all of the above and runs at 85 MHz on the board, the same as v0.1.
One timing technique is worth some discussion: adder carry-chain fusion. The original 386 has a special case for the "complex effective address". When all three terms are present — EA = base + index<<scale + disp — it has to be computed in two cycles instead of one, because the same combinational path also carries a 32-bit adder for segment relocation, and three 32-bit adders in series are too slow for one clock. The lucky thing on the DE10-Nano is that the Altera ALM (the FPGA logic cell) supports a fast 3-input adder via a "shared arithmetic chain": a 3-input add uses one carry chain and is only slightly slower than a 2-input add. Taking advantage of that, z386 computes the complex EA in a single cycle without losing clock speed.
Beyond those, closing 85 MHz was a steady grind of smaller cleanups, each shaving a path: predecoding the microcode control bits in the ROM's output-register cycle, so they don't decode on the execution path; replicating registers to break large fanouts; flattening the microcode stalling logic from ~5 LUT levels to ~2. These don't change logic behavior but are necessary to maintain the CPI improvements.
Conclusion
The 80386 early-start feature is a good example of latency-hiding design. It trades a small amount of forwarding logic for 9% more performance, and could be viewed as a precursor to the 486's 5-stage pipeline design.
On the implementation side, z386 0.1 finished the basic machinery needed for the 386 microcode to execute (mostly) correctly. My other goal for the project has always been for it to be as fast as — or faster than — the other open-source x86 core, ao486, and I think z386 0.4 gets there. So there are now two fast open-source x86 cores: a pipelined one (ao486) and a non-pipelined one (z386). In theory a pipeline should win, but given x86's complexity, it is hard to get one both correct and well-optimized.
On correctness, z386 does not boot Windows yet — there's no fundamental reason it couldn't, x86 is just complicated. So help fixing bugs is very welcome. Please also report game-compatibility issues to z386_MiSTer, since those help improve the CPU core too.
Thanks for reading. You can follow me on X (@nand2mario) for updates, or use RSS.
Credits
The analysis of the 80386 in this post draws on the microcode disassembly and silicon reverse engineering work of reenigne, gloriouscow, smartest blob, and Ken Shirriff.