I work at Red Hat on GCC, the GNU Compiler Collection. For the last five releases of GCC, I've been working on -fanalyzer, a static analysis pass that tries to identify various problems at compile-time, rather than at runtime. It performs "symbolic execution" of C source code—effectively simulating the behavior of the code along the various possible paths of execution through it.
This article summarizes what's new with -fanalyzer in GCC 14, which I hope will be officially released sometime in April 2024.
Solving the halting problem?
Obviously I'm kidding with the title here, but for GCC 14 I've implemented a new warning: -Wanalyzer-infinite-loop that's able to detect some simple cases of infinite loops.
For example, consider the following C code:
void test (int m, int n)
{
float arr[m][n];
for (int i = 0; i < m; i++)
for (int j = 0; j < n; i++)
arr[i][j] = 0.f;
/* etc */
}
If you look closely, you'll see that the user probably made the second for statement by copying the first one, but forgot to change the increment clause from an i to a j.
GCC 14's -fanalyzer option successfully detects this, with this output:
warning: infinite loop [CWE-835] [-Wanalyzer-infinite-loop]
5 | for (int j = 0; j < n; i++)
| ~~^~~
'test': events 1-5
|
| 5 | for (int j = 0; j < n; i++)
| | ~~^~~ ~~~
| | | |
| | | (4) looping back...
| | (1) infinite loop here
| | (2) when 'j < n': always following 'true' branch...
| | (5) ...to here
| 6 | arr[i][j] = 0.f;
| | ~~~~~~~~~
| | |
| | (3) ...to here
|
The output could be more readable here—you have to read the events in order of their numbers, from (1) to (5). For GCC 15 I hope to improve this, perhaps with ASCII art that highlights the path taken by control flow.
I find the Compiler Explorer website very useful for trying out code snippets with different compilers and options. You can try the above example on it here.
Visualizing buffer overflows
The analyzer gained support in GCC 13 for bounds checking with a -Wanalyzer-out-of-bounds warning.
For example, given the out-of-bounds write in strcat in:
#include <string.h>
void test (void)
{
char buf[10];
strcpy (buf, "hello");
strcat (buf, " world!");
}
The analyzer emits this message:
<source>: In function 'test':
<source>:7:3: warning: stack-based buffer overflow [CWE-121] [-Wanalyzer-out-of-bounds]
7 | strcat (buf, " world!");
| ^~~~~~~~~~~~~~~~~~~~~~~
'test': events 1-2
|
| 5 | char buf[10];
| | ^~~
| | |
| | (1) capacity: 10 bytes
| 6 | strcpy (buf, "hello");
| 7 | strcat (buf, " world!");
| | ~~~~~~~~~~~~~~~~~~~~~~~
| | |
| | (2) out-of-bounds write from byte 10 till byte 12 but 'buf' ends at byte 10
|
<source>:7:3: note: write of 3 bytes to beyond the end of 'buf'
7 | strcat (buf, " world!");
| ^~~~~~~~~~~~~~~~~~~~~~~
<source>:7:3: note: valid subscripts for 'buf' are '[0]' to '[9]'
I've been unhappy with the readability of these messages: it describes some aspects of the problem, but it's hard for the user to grasp exactly what the analyzer is "thinking."
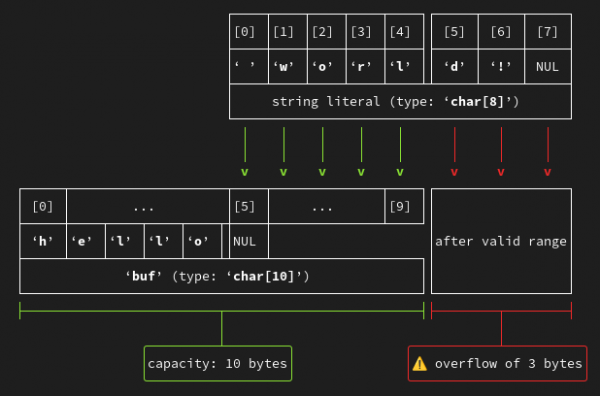
So for GCC 14, I've added the ability for the analyzer to emit text-based diagrams visualizing the spatial relationships in a predicted buffer overflow. For the above example (which you can try here in Compiler Explorer) it emits the diagram shown in Figure 1.

This diagram shows the destination buffer populated by the content from the strcpy call, and thus the existing terminating NUL byte used for the start of the strcat call.
For non-ASCII strings such as this:
#include <string.h>
void test (void)
{
char buf[11];
strcpy (buf, "サツキ");
strcat (buf, "メイ");
}
It can show the UTF-8 representation of the characters (Figure 2).

This demonstrates that the overflow happens partway through the メ character (U+30E1). (Link to Compiler Explorer).
Analyzing C string operations
I've put some work into better tracking C string operations in GCC 14's analyzer.
One of the improvements is that the analyzer now simulates APIs that scan a buffer expecting a null terminator byte, and will complain about code paths where a pointer to a buffer that isn't properly terminated is passed to such an API.
I've added a new function attribute null_terminated_string_arg(PARAM_IDX) for telling the analyzer (and human readers of the code) about parameters that are expected to be null-terminated strings. For example, given this buggy code:
extern char *
example_fn (const char *p)
__attribute__((null_terminated_string_arg (1)))
__attribute__((nonnull));
char *
test_unterminated_str (void)
{
char str[3] = "abc";
return example_fn (str);
}
Here, the analyzer correctly complains that str doesn't have a null terminator byte, and thus example_fn will presumably read past the end of the buffer:
<source>: In function 'test_unterminated_str':
<source>:10:10: warning: stack-based buffer over-read [CWE-126] [-Wanalyzer-out-of-bounds]
10 | return example_fn (str);
| ^~~~~~~~~~~~~~~~
'test_unterminated_str': events 1-3
|
| 9 | char str[3] = "abc";
| | ^~~
| | |
| | (1) capacity: 3 bytes
| 10 | return example_fn (str);
| | ~~~~~~~~~~~~~~~~
| | |
| | (2) while looking for null terminator for argument 1 ('&str') of 'example_fn'...
| | (3) out-of-bounds read at byte 3 but 'str' ends at byte 3
|
<source>:10:10: note: read of 1 byte from after the end of 'str'
10 | return example_fn (str);
| ^~~~~~~~~~~~~~~~
<source>:10:10: note: valid subscripts for 'str' are '[0]' to '[2]'
┌─────────────────┐
│ read of 1 byte │
└─────────────────┘
^
│
│
┌─────────────────┬────────────────┬────────────────┐┌─────────────────┐
│ [0] │ ... │ [2] ││ │
├─────────────────┴────────────────┴────────────────┤│after valid range│
│ 'str' (type: 'char[3]') ││ │
└───────────────────────────────────────────────────┘└─────────────────┘
├─────────────────────────┬─────────────────────────┤├────────┬────────┤
│ │
╭──────┴──────╮ ╭───────────┴──────────╮
│size: 3 bytes│ │ over-read of 1 byte │
╰─────────────╯ ╰──────────────────────╯
<source>:2:1: note: argument 1 of 'example_fn' must be a pointer to a null-terminated string
2 | example_fn (const char *p)
| ^~~~~~~~~~
Again, you can try this example in Compiler Explorer here.
Taint analysis
The analyzer has a form of "taint analysis", which tracks attacker-controlled inputs, places where they are sanitized, and places where they are used without sanitization. In previous GCC releases this was too buggy to enable by default, with lots of false positives, so I hid it behind an extra command-line argument. I've fixed many bugs with this, so for GCC 14 I've enabled this by default when -fanalyzer is selected. This also enables these 6 taint-based warnings:
For example, here's an excerpt from CVE-2011-2210 from the Linux kernel:
extern struct hwrpb_struct *hwrpb;
SYSCALL_DEFINE5(osf_getsysinfo, unsigned long, op, void __user *, buffer,
unsigned long, nbytes, int __user *, start, void __user *, arg)
{
/* [...snip...] */
/* case GSI_GET_HWRPB: */
if (nbytes < sizeof(*hwrpb))
return -1;
if (copy_to_user(buffer, hwrpb, nbytes) != 0)
return -2;
return 1;
/* [...snip...] */
}
You can see a more full version at Compiler Explorer. In particular, I added __attribute__((tainted_args)) to the __SYSCALL_DEFINEx macro to indicate to the analyzer that the arguments to osf_getsysinfo are coming from across a trust boundary, and thus should be considered tainted.
With GCC 14, the analyzer is able to detect the vulnerability (again, edited somewhat for brevity):
<source>: In function 'sys_osf_getsysinfo':
<source>:55:21: warning: use of attacker-controlled value 'nbytes' as size without upper-bounds checking [CWE-129] [-Wanalyzer-tainted-size]
55 | if (copy_to_user(buffer, hwrpb, nbytes) != 0)
| ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
'sys_osf_getsysinfo': event 1
|
| 28 | long sys##name(__SC_DECL##x(__VA_ARGS__))
| | ^~~
| | |
| | (1) function 'sys_osf_getsysinfo' marked with '__attribute__((tainted_args))'
|
+--> 'sys_osf_getsysinfo': event 2
|
| 28 | long sys##name(__SC_DECL##x(__VA_ARGS__))
| | ^~~
| | |
| | (2) entry to 'sys_osf_getsysinfo'
|
'sys_osf_getsysinfo': events 3-6
|
| 52 | if (nbytes < sizeof(*hwrpb))
| | ^
| | |
| | (3) 'nbytes' has its lower bound checked here
| | (4) following 'false' branch (when 'nbytes > 31')...
|......
| 55 | if (copy_to_user(buffer, hwrpb, nbytes) != 0)
| | ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
| | |
| | (5) ...to here
| | (6) use of attacker-controlled value 'nbytes' as size without upper-bounds checking
|
<source>:11:13: note: parameter 3 of 'copy_to_user' marked as a size via attribute 'access (write_only, 1, 3)'
11 | extern long copy_to_user(void __user *to, const void *from, unsigned long n)
| ^~~~~~~~~~~~
The issue is that the attempt to sanitize nbytes was written as
if (nbytes < sizeof(*hwrpb))
when it should have been
if (nbytes > sizeof(*hwrpb))
With a fixed version of that conditional, the analyzer is silent.
I'm continuing to work on running the analyzer on the kernel to look for vulnerabilities (and fix false positives in the analyzer).
Try it out!
We're still fixing bugs, but we hope that GCC 14 will be ready to officially release (as 14.1) sometime in April 2024.
With my "downstream" hat on, we're already using the prerelease (GCC 14.0) within Fedora 40 Beta.
Finally, you can use the excellent Compiler Explorer site to play with the new compiler. Have fun!
Last updated: April 4, 2024