A $1,000,000+ competition towards open AGI progress.
AGI progress has stalled. New ideas are needed.
Intelligence vs Memorization
Modern AI (LLMs) have shown to be great memorization engines. They are able to memorize high-dimensional patterns in their training data and apply those patterns into adjacent contexts. This is also how their apparent reasoning capability works. LLMs are not actually reasoning. Instead they memorize reasoning patterns and apply those reasoning patterns into adjacent contexts. But they cannot generate new reasoning based on novel situations.
More training data lets you "buy" performance on memorization based benchmarks (MMLU, GSM8K, ImageNet, GLUE, etc.) But memorization alone is not general intelligence. General intelligence is the ability to efficiently acquire new skills.
More scale will not enable LLMs to learn new skills. We need new architectures or algorithms that enable AI systems to learn at test time. This is how humans are able to adapt to novel situations.
Beyond LLMs, for many years, we've had AI systems that can beat humans at poker, chess, go, and other games. However, no AI system trained to succeed at one game can simply be retrained toward another. Instead researchers have had to re-architect and rebuild entirely new systems per game.
This is a failure to generalize.
Without this capability, AI will forever be rate-limited by the human general intelligence in the loop. We want AGI that can discover and invent alongside humans to push humanity forward.
Given the success and proven economic utility of LLMs over the past 4 years, the above may seem like extraodinary claims. Strong claims require strong evidence.
ARC-AGI
Introduced by François Chollet in his influencial paper "On the Measure of Intelligence", ARC-AGI is the only AI eval which measures general intelligence: a system that can efficiently acquire new skills and solve novel, open-ended problems.
ARC-AGI was created in 2019 and the state-of-the-art (SOTA) high score was 20%. Today, only 34%.
Yet humans - even children - can master tasks quickly.
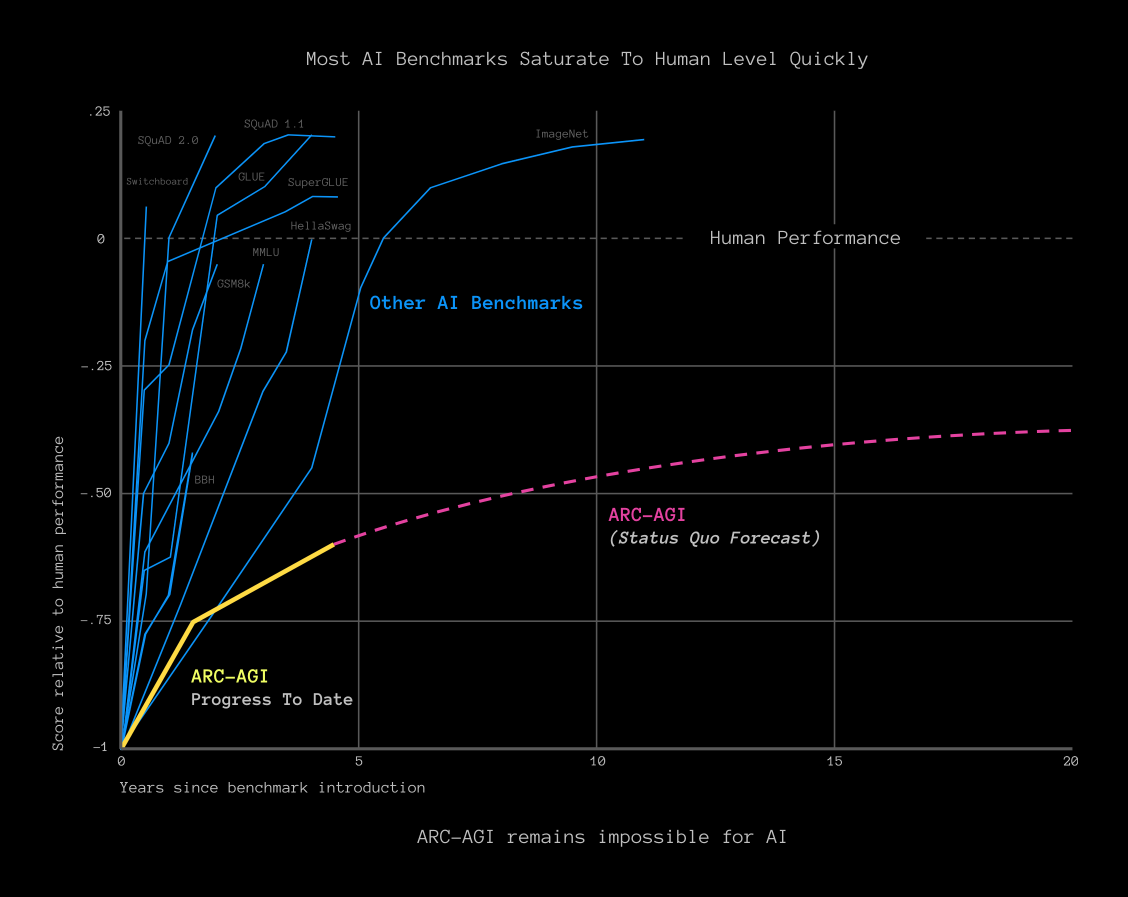
ARC-AGI is easy for humans and impossible for modern AI.
Most AI benchmarks rapidly saturate to human performance-level because they test only for memorization, which is something AI is superhuman at.
ARC-AGI is not saturating, in fact current pace is slowing down. It was designed to resist memorization and has proven extremely challenging for both the largest foundational transformer models as well as bespoke AI systems designed to defeat ARC-AGI.

A solution to ARC-AGI, at a minimum, opens up a completely new programming paradigm where programs can perfectly and reliably generalize from an arbitrary set of priors. We also believe a solution is on the critical path towards AGI

Open Source AGI Progress
If you accept new ideas are needed, let's consider how to increase the rate of new ideas. Unfortunately, trends in AI are going the wrong way.
Closed vs Open
Starting with the GPT-4 release, frontier AGI progress has gone closed source. The GPT-4 technical report surprisingly contains no technical details. OpenAI said "competitive" reasons were the first reason why. Google's Gemini technical report also contains no technical details on the long context window frontier innovation.
LLMs have also shifted the majority of research attention away from new architectures and new algorithms. Over $20B was deployed to non-general AI companies in 2023 and many frontier DeepMind researchers were restaffed to Gemini (in order to compete with OpenAI.)
Leading labs have strong incentives to loudly claim, "scale is all you need," and, "don't try to compete with us on frontier research," even though they all quietly believe new ideas are needed to reach AGI. Their bet is they can discover all the necessary new ideas within their labs.
LLM History
But let's look at the history of LLMs. Specifically the transformer architecture. Transformers emerged many years downstream of machine translation research (e.g., English to Spanish.)
- 2014: Sutskever et. al. (Google) published Seq2Seq Learning using RNNs and CNNs for variable length input vs output (English and Spanish words are not the same length.)
- 2016: Bahdanau et. al. (Jacobs University) popularized the concept of "attention" so a system could consider different parts of the input to predict output (English adjectives come before nouns, Spanish after.)
- 2017: Vaswani et. al. (Google) realized "attention is all you need", dropping RNNs and CNNs, optimizing the architecture, enabling new scale
- 2018: Radford et. al. (OpenAI) created GPT-2 built on top of the transformer architecture at frontier scale, showing emergent capabilities
The story of the transformer is the story of science. Researchers in different labs and teams publish and build on top of each other's work.
While it is possible one lab could discover AGI alone, it is highly unlikely. The global chance of AGI discovery has decreased and will keep decreasing if we accepting this as status quo.
Progress
I have spoken with many young students and would-be researchers over the past year. Many are depressed. There is a sense of dread that everything has been figured out already. But this is not true! The AI ecosystem is intentionally telling a partial-truth to boost their relative competitive positions to the detriment of actual progress towards AGI.
Worse, the inaccurate "scale is all you need" belief is now influencing the AI regulatory environment. Regulators are considering roadblocks to frontier AI research under the wrong assumption that AGI is imminent. The truth is no one knows how to build AGI.
We should be trying to incentivize new ideas, not slow them down. The internet and open source are the strongest innovation engines the world has ever seen.
By incentivizing open source we increase the rate of new ideas, increasing the chance we discover AGI, and ensure those new ideas are widely distributed to establish a more even playing field between small and large AI companies.
We hope ARC Prize can help counterbalance these trends.

ARC Prize
Announcing ARC Prize, a $1,000,000+ prize pool competition to beat and open-source a solution to the ARC-AGI eval.
Hosted by Mike Knoop and François Chollet. Presented by Infinite Monkey and Lab42.
ARC Prize Goals
- Increase the number of people working on frontier AGI research.
- Popularize an objective measure of AGI progress.
- Solve ARC-AGI and learn something new about the nature of intelligence.
Get Started
Ready to make the first significant leap towards AGI in years? No matter who you are, where you come from, what you do for a living, you are welcome to join this competition. New ideas might come from anywhere. Possibly you?
Find competition format and prize details on ARC Prize 2024 here.
For more information on how to get started solving ARC-AGI visit the guide.
To learn more how ARC-AGI measures general intelligence visit ARC-AGI.
Stay updated on ARC Prize progress and SOTA solutions on X/Twitter, YouTube, Email, and Discord. You can also contact us at [email protected].