
|
|
|
| I think this is likely incorrect based on how much voice/audio distribution meta does today with facebook (and facebook live), instagram and whatsapp - moreso with whatsapp voice message and calling given it's considerable market share in countries with intermittent and low-reliability network connectivity. The fact it is more packet-loss robust and jitter-robust means that you can rely on protocols that have less error correction, segmenting and receive-reply overhead as well.
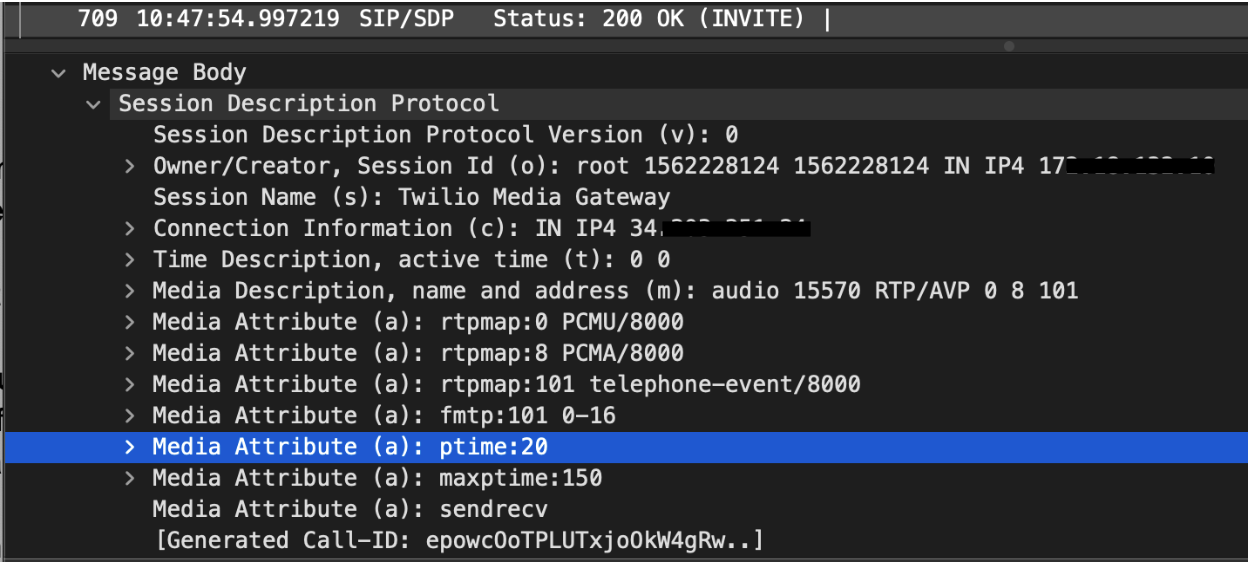
I don't think it's unreasonable to assume this could reduce their total audio-sourced bandwidth consumption by a considerable amount while maintaining/improving reliability and perceived "quality". Looking at wireshark review of whatsapp on an active call there was around 380 UDP packets sent from source to recipient during a 1 minute call, and a handful of TCP packets to whatsapp's servers. That would yield a transmission overhead of about 2.2kbps. quick edit to clarify why this is: you can see starting ptime (audio size per packet) set to 20ms here, but maxptime set to 150ms, which the clients can/will use opportunistically to reduce the number of packets being sent taking into consideration the latency between parties and bandwidth available. (image): https://www.twilio.com/content/dam/twilio-com/global/en/blog... |
{kind=link}
|
| I think you’re misreading OP, as he says 380 packets per minute, not second. That would give you an overhead of 253 bytes per second, sounds a lot more reasonable. |
|
| In my personal experience, Whatsapp's calling is subpar compared to Facetime audio, Skype or VoWIFI even. Higher latency, lower sound quality and very sensitive to spotty connections. |
|
| I racked my brain and couldn’t think of a single example of something released by Microsoft Research offhand, so I proceeded to visit their website. It can be found at https://www.microsoft.com/en-us/research/
I found exactly zero things that they have provided to the world. Literally none, and I really came in with an open mind. All I found was marketer drivel telling me how I should feel about the impact of the marketing copy I was currently reading. No concrete examples after fanning out 3 links deep into every article posted on that site. I must be missing something so can you point me to at least one example of work that’s come out of Microsoft Research on the same scale as Meta’s LLM models or ReactJS? |
|
| This is a surprisingly negative take, you should look a little further. Microsoft Research has done an incredible amount of high quality research. I've mostly read papers from them on programming languages, they have or did employ leading researchers behind C#, F#, Typescript (of course), as well as Haskell (Simon Peyton Jones and Simon Marlow spent a long time there), F*, and Lean (built by Leonardo de Moura while at MSR). MSR's scope has been much broader than just languages, of course.
You could look at their blog: https://www.microsoft.com/en-us/research/blog/ Or their list of publications: https://www.microsoft.com/en-us/research/publications/ Here's a (no longer updated, apparently) list of awards given to researchers at Microsoft: https://www.microsoft.com/en-us/research/awards-archive/ I've heard in interviews that MSR's culture is not what it used to be (like Bell Labs, maybe), but over time they've funded a ton of highly influential research. |
|
| You will need to provide citations on the last point as Facebook are widely known to have broken the gentleman's agreement between Apple and Google that was suppressing tech pay in the early 2010s. |
|
| The lack of any reference or comparison to Codec2 immediately leads me to question the real value and motivation of this work. The world doesn't need another IP-encumbered audio codec in this space. |
|
| Can hardly try that out if this PR piece does not contain any code. We can judge it as well as you can from the couple examples they showed off |
|
| Only slightly OT:
ELI5: Why is a typical phone call today less intelligible than a 8kHz 8-bit μ-law with ADPCM from the '90s did? [edit] s/sound worse/less intelligible/ |
|
| There’s a section (“Our motivation for building a new codec”) in the article that directly addresses this. Assuming you have >32 kbps bandwidth available is a bad assumption. |
|
| Perhaps you know this already (not really clear on what your comment is saying), but Dave Taht is one of the authors of FQ-CoDel, which is what the author of CoDel recommends using when available. |
|
| It appears to be entirely closed source at the moment. This is just the announcement of development of in-house tech. Nothing public yet that could even be licensed. |
|
| Can't we have an audio codec that first sends a model of the particular voice, and then starts to send bits corresponding to the actual speech? |
|
| This is actually an old idea, minus the AI angle (1930s). It’s what voders and vocoders were originally designed for, before Kraftwerk et al. found out you can use them to make cool robot voices. |
|
| You need a bunch of bandwidth upfront for that, which you might not have, and enough compute available at the other end to reconstruct it, which you really might not have. |
|
| Maybe SiriusXM can pick this up. The audio quality is generally awful but especially on news/talk channels like Bloomberg and CNBC. There is no depth or richness to the voices. |
|
| That is a marked improvement compared to the other examples provided. Nice to see it also has less compute resources required for that higher quality output. |
|
| Starlink is in a better position as their satellites are in a low earth orbit - 30 times closer than geostationary. It correlates to 1000 times (30dB) stronger signal on both sides. |
|
| This is amazing.
So you could have about 9 voice streams over a 56K modem. Incredible. Great for stuffing audio recordings into little devices like greeting card audio players and microcontrollers. |
To keep latency low in real-time communications, the packet rate needs to be relatively high, and at some point the overhead of UDP, IP, and lower layers starts dominating over the actual payload.
As an example, consider (S)RTP (over UDP and IP): RTP adds at least 12 bytes of overhead (let's ignore the SRTP authentication tag for now); UDP adds 8 byte, and IPv4 adds 20, for a total of 40. At at typical packet rate of 50 per second (for a serialization delay of 1/50 = 20ms), that's 16 kbps of overhead alone!
It might still be acceptable to reduce the packet rate to 25 per second, which would cut this in half for an overhead of 8 kbps, but the overhead would still be dominating the total transmission rate.
Where codecs like this can really shine, though, is circuit-switched communication (some satphones use bitrates of around 2 kbps, which currently sound awful!), or protocol-aware VoIP systems that can employ header compression such as that used by LTE and 5G in IMS (most of the 40 bytes per frame are extremely predictable).