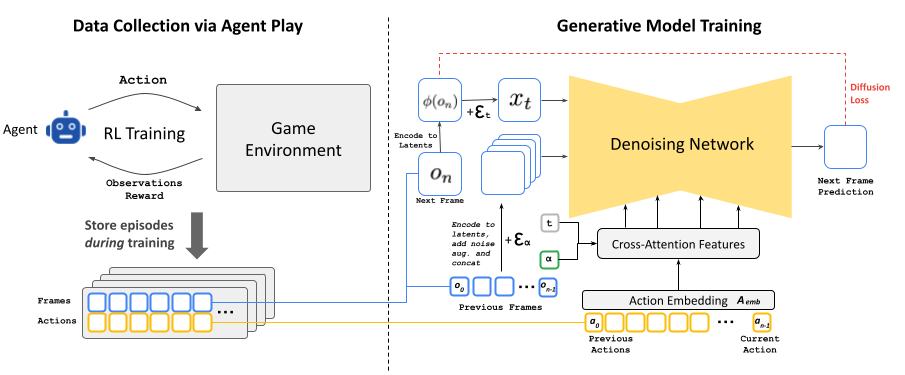

Data Collection via Agent Play: Since we cannot collect human gameplay at scale, as a first stage we train an automatic RL-agent to play the game, persisting it's training episodes of actions and observations, which become the training data for our generative model.
Training the Generative Diffusion Model: We re-purpose a small diffusion model, Stable Diffusion v1.4, and condition it on a sequence of previous actions and observations (frames). To mitigate auto-regressive drift during inference, we corrupt context frames by adding Gaussian noise to encoded frames during training. This allows the network to correct information sampled in previous frames, and we found it to be critical for preserving visual stability over long time periods.
Latent Decoder Fine-Tuning: The pre-trained auto-encoder of Stable Diffusion v1.4, which compresses 8x8 pixel patches into 4 latent channels, results in meaningful artifacts when predicting game frames, which affect small details and particularly the bottom bar HUD. To leverage the pre-trained knowledge while improving image quality, we train just the decoder of the latent auto-encoder using an MSE loss computed against the target frame pixels.