As you may, or may not know, I wrote paraLLEl-RDP back in 2020. It aimed at implementing the N64 RDP in Vulkan compute. Lightning fast, and extremely accurate, plus the added support of up-scaling on top. I’m quite happy how it turned out. Of course, the extreme accuracy was due to Angrylion being used as reference and I could aim for bit-exactness against that implementation.
Since then, there’s been the lingering idea of doing the same thing, but for PlayStation 2. Until now, there’s really only been one implementation in town, GSdx, which has remained the state-of-the-art for 20 years.
paraLLEl-GS is actually not the first compute implementation of the PS2 GS. An attempt was made back in 2014 for OpenCL as far as I recall, but it was never completed. At the very least, I cannot find it in the current upstream repo anymore.
The argument for doing compute shader raster on PS2 is certainly weaker than on N64. Angrylion was – and is – extremely slow, and N64 is extremely sensitive to accuracy where hardware acceleration with graphics APIs is impossible without serious compromises. PCSX2 on the other hand has a well-optimized software renderer, and a pretty solid graphics-based renderer, but that doesn’t mean there aren’t issues. The software renderer does not support up-scaling for example, and there are a myriad bugs and glitches with the graphics-based renderer, especially with up-scaling. As we’ll see, the PS2 GS is quite the nightmare to emulate in its own way.
My main motivation here is basically “because I can”. I already had a project lying around that did “generic” compute shader rasterization. I figured that maybe we could retro-fit this to support PS2 rendering.
I didn’t work on this project alone. My colleague, Runar Heyer, helped out a great deal in the beginning to get this started, doing all the leg-work to study the PS2 from various resources, doing the initial prototype implementation and fleshing out the Vulkan GLSL to emulate PS2 shading. Eventually, we hit some serious roadblocks in debugging various games, and the project was put on ice for a while since I was too drained dealing with horrible D3D12 game debugging day in and day out. The last months haven’t been a constant fire fight, so I’ve finally had the mental energy to finish it.
My understanding of the GS is mostly based on what Runar figured out, and what I’ve seen by debugging games. The GSdx software renderer does not seem like it’s hardware bit-accurate, so we were constantly second-guessing things when trying to compare output. This caused a major problem when we had the idea of writing detailed tests that directly compared against GSdx software renderer, and the test-driven approach fell flat very quickly. As a result, paraLLEl-GS isn’t really aiming for bit-accuracy against hardware, but it tries hard to avoid obvious accuracy issues at the very least.
Basic GS overview
Again, this is based on my understanding, and it might not be correct. 😀
GS is a pixel-pushing monster
The GS is infamous for its insane fill-rate and bandwidth. It could push over a billion pixels per second (in theory at least) back in 2000 which was nuts. While the VRAM is quite small (4 MiB), it was designed to be continuously streamed into using the various DMA engines.
Given the extreme fill-rate requirements, we have to design our renderer accordingly.
GS pixel pipeline is very basic, but quirky
In many ways, the GS is actually simpler than N64 RDP. Single texture, and a single cycle combiner, where N64 had a two stage combiner + two stage blender. Whatever AA support is there is extremely basic as well, where N64 is delightfully esoteric. The parts of the pixel pipeline that is painful to implement with traditional graphics APIs is:
Blending goes beyond 1.0
Inherited from PS1, 0x80 is treated as 1.0, and it can go all the way up to 0xff (almost 2). Shifting by 7 is easier than dividing by 255 I suppose. I’ve seen some extremely ugly workarounds in PCSX2 before to try working around this since UNORM formats cannot support this as is. Textures are similar, where alpha > 1.0 is representable.
There is also wrapping logic that can be used for when colors or alpha goes above 0xFF.
Destination alpha testing
The destination alpha can be used as a pseudo-stencil of sorts, and this is extremely painful without programmable blending. I suspect this was added as PS1 compatibility, since PS1 also had this strange feature.
Conditional blending
Based on the alpha, it’s possible to conditionally disable blending. Quite awkward without programmable blending … This is another PS1 compat feature. With PS1, it can be emulated by rendering every primitive twice with state changes in-between, but this quickly gets impractical with PS2.
Alpha correction
Before alpha is written out, it’s possible to OR in the MSB. Essentially forcing alpha to 1. It is not equivalent to alphaToOne however, since it’s a bit-wise OR of the MSB.
Alpha test can partially discard
A fun thing alpha tests can do is to partially discard. E.g. you can discard just color, but keep the depth write. Quite nutty.
AA1 – coverage-to-alpha – can control depth write per pixel
This is also kinda awkward. The only anti-alias PS2 has is AA1 which is a coverage-to-alpha feature. Supposedly, less than 100% coverage should disable depth writes (and blending is enabled), but the GSdx software renderer behavior here is extremely puzzling. I don’t really understand it yet.
32-bit fixed-point Z
I’ve still yet to see any games actually using this, but technically, it has D32_UINT support. Fun! From what I could grasp, GSdx software renderer implements this with FP64 (one of the many reasons I refuse to believe GSdx is bit-accurate), but FP64 is completely impractical on GPUs. When I have to, I’ll implement this with fixed-point math. 24-bit Z and 16-bit should be fine with FP32 interpolation I think.
Pray you have programmable blending
If you’re on a pure TBDR GPU most of this is quite doable, but immediate mode desktop GPUs quickly degenerates into ROV or per-pixel barriers after every primitive to emulate programmable blending, both which are horrifying for performance. Of course, with compute we can make our own TBDR to bypass all this. 🙂
D3D9-style raster rules
Primitives are fortunately provided in a plain form in clip-space. No awkward N64 edge equations here. The VU1 unit is supposed to do transforms and clipping, and emit various per-vertex attributes:
X/Y: 12.4 unsigned fixed-point
Z: 24-bit or 32-bit uint
FOG: 8-bit uint
RGBA: 8-bit, for per-vertex lighting
STQ: For perspective correct texturing with normalized coordinates. Q = 1 / w, S = s * Q, T = t * Q. Apparently the lower 8-bits of the mantissa are clipped away, so bfloat24? Q can be negative, which is always fun. No idea how this interacts with Inf and NaN …
UV: For non-perspective correct texturing. 12.4 fixed-point un-normalized.
- Triangles are top-left raster, just like modern GPUs.
- Pixel center is on integer coordinate, just like D3D9. (This is a common design mistake that D3D10+ and GL/Vulkan avoids).
- Lines use Bresenham’s algorithm, which is not really feasible to upscale, so we have to fudge it with rect or parallelogram.
- Points snap to nearest pixel. Unsure which rounding is used though … There is no interpolation ala gl_PointCoord.
- Sprites are simple quads with two coordinates. STQ or UV can be interpolated and it seems to assume non-rotated coordinates. To support rotation, you’d need 3 coordinates to disambiguate.
All of this can be implemented fairly easily in normal graphics APIs, as long as we don’t consider upscaling. We have to rely on implementation details in GL and Vulkan, since these APIs don’t technically guarantee top-left raster rules.
Since X/Y is unsigned, there is an XY offset that can be applied to center the viewport where you want. This means the effective range of X/Y is +/- 4k pixels, a healthy guard band for 640×448 resolutions.
Vertex queue
The GS feels very much like old school OpenGL 1.0 with glVertex3f and friends. It even supports TRIANGLE_FAN! Amazing … RGBA, STQ and various registers are set, and every XYZ register write forms a vertex “kick” which latches vertex state and advances the queue. An XYZ register write may also be a drawing kick, which draws a primitive if the vertex queue is sufficiently filled. The vertex queue is managed differently depending on the topology. The semantics here seem to be pretty straight forward where strip primitives shift the queue by one, and list primitives clear the queue. Triangle fans keep the first element in the queue.
Fun swizzling formats
A clever idea is that while rendering to 24-bit color or 24-bit depth, there is 8 bits left unused in the MSBs. You can place textures there, because why not. 8H, 4HL, 4HH formats support 8-bit and 4-bit palettes nicely.
Pixel coordinates on PS2 are arranged into “pages”, which are 8 KiB, then subdivided into 32 blocks, and then, the smaller blocks are swizzled into a layout that fits well with a DDA-style renderer. E.g. for 32-bit RGBA, a page is 64×32 pixels, and 32 8×8 blocks are Z-order swizzled into that page.
Framebuffer cache and texture cache
There is a dedicated cache for framebuffer rendering and textures, one page’s worth. Games often abuse this to perform feedback loops, where they render on top of the pixels being sampled from. This is the root cause of extreme pain. N64 avoided this problem by having explicit copies into TMEM (and not really having the bandwidth to do elaborate feedback effects), and other consoles rendered to embedded SRAM (ala a tiler GPU), so these feedbacks aren’t as painful, but the GS is complete YOLO. Dealing with this gracefully is probably the biggest challenge. Combined with the PS2 being a bandwidth monster, developers knew how to take advantage of copious blending and blurring passes …
Texturing
Texturing on the GS is both very familar, and arcane.
On the plus side, the texel-center is at half-pixel, just like modern APIs. It seems like it has 4-bit sub-texel precision instead of 8 however. This is easily solved with some rounding. It also seems to have floor-rounding instead of nearest-rounding for bi-linear.
The bi-linear filter is a normal bi-linear. No weird 3-point N64 filter here.
On the weirder side, there are two special addressing modes.
REGION_CLAMP supports an arbitrary clamp inside a texture atlas (wouldn’t this be nice in normal graphics APIs? :D). It also works with REPEAT, so you can have REPEAT semantics on border, but then clamp slightly into the next “wrap”. This is trivial to emulate.
REGION_REPEAT is … worse. Here we can have custom bit-wise computation per coordinate. So something like u’ = (u & MASK) | FIX. This is done per-coordinate in bi-linear filtering, which is … painful, but solvable. This is another weird PS1 feature that was likely inherited for compatibility. At least on PS1, there was no bi-linear filtering to complicate things 🙂
Mip-mapping is also somewhat curious. Rather than relying on derivatives, the log2 of interpolated Q factor, along with some scaling factors are used to compute the LOD. This is quite clever, but I haven’t really seen any games use it. The down-side is that triangle-setup becomes rather complex if you want to account for correct tri-linear filtering, and it cannot support e.g. anisotropic filtering, but this is 2000, who cares! Not relying on derivatives is a huge boon for the compute implementation.
Formats are always “normalized” to RGBA8_UNORM. 5551 format is expanded to 8888 without bit-replication. There is no RGBA4444 format.
It’s quite feasible to implement the texturing with plain bindless.
CLUT
This is a 1 KiB cache that holds the current palette. There is an explicit copy step from VRAM into that CLUT cache before it can be used. Why hello there, N64 TMEM!
The CLUT is organized such that it can hold one full 256 color palette in 32-bit colors. On the other end, it can hold 32 palettes of 16 colors at 16 bpp.
TEXFLUSH
There is an explicit command that functions like a “sync and invalidate texture cache”. In the beginning I was hoping to rely on this to guide the hazard tracking, but oh how naive I was. In the end, I simply had to ignore TEXFLUSH. Basically, there are two styles of caching we could take with GS.
With “maximal” caching, we can assume that frame buffer caches and texture caches are infinitely large. The only way a hazard needs to be considered is after an explicit flush. This … breaks hard. Either games forget to use TEXFLUSH (because it happened to work on real hardware), or they TEXFLUSH way too much.
With “minimal” caching, we assume there is no caching and hazards are tracked directly. Some edge case handling is considered for feedback loops.
I went with “minimal”, and I believe GSdx did too.
Poking registers with style – GIF
The way to interact with the GS hardware is through the GIF, which is basically a unit that reads data and pokes the correct hardware registers. At the start of a GIF packet, there is a header which configures which registers should be written to, and how many “loops” there are. This maps very well to mesh rendering. We can consider something like one “loop” being:
- Write RGBA vertex color
- Write texture coordinate
- Write position with draw kick
And if we have 300 vertices to render, we’d use 300 loops. State registers can be poked through the Address + Data pair, which just encodes target register + 64-bit payload. It’s possible to render this way too of course, but it’s just inefficient.
Textures are uploaded through the same mechanism. Various state registers are written to set up transfer destinations, formats, etc, and a special register is nudged to transfer 64-bit at a time to VRAM.
Hello Trongle – GS
If you missed the brain-dead simplicity of OpenGL 1.0, this is the API for you! 😀
For testing purposes, I added a tool to generate a .gs dump format that PCSX2 can consume. This is handy for comparing implementation behavior.
First, we program the frame buffer and scissor:
TESTBits test = {};
test.ZTE = TESTBits::ZTE_ENABLED;
test.ZTST = TESTBits::ZTST_GREATER; // Inverse Z, LESS is not supported.
iface.write_register(RegisterAddr::TEST_1, test);
FRAMEBits frame = {};
frame.FBP = 0x0 / PAGE_ALIGNMENT_BYTES;
frame.PSM = PSMCT32;
frame.FBW = 640 / BUFFER_WIDTH_SCALE;
iface.write_register(RegisterAddr::FRAME_1, frame);
ZBUFBits zbuf = {};
zbuf.ZMSK = 0; // Enable Z-write
zbuf.ZBP = 0x118000 / PAGE_ALIGNMENT_BYTES;
iface.write_register(RegisterAddr::ZBUF_1, zbuf);
SCISSORBits scissor = {};
scissor.SCAX0 = 0;
scissor.SCAY0 = 0;
scissor.SCAX1 = 640 - 1;
scissor.SCAY1 = 448 - 1;
iface.write_register(RegisterAddr::SCISSOR_1, scissor);
Then we nudge some registers to draw:
struct Vertex
{
PackedRGBAQBits rgbaq;
PackedXYZBits xyz;
} vertices[3] = {};
for (auto &vert : vertices)
{
vert.rgbaq.A = 0x80;
vert.xyz.Z = 1;
}
vertices[0].rgbaq.R = 0xff;
vertices[1].rgbaq.G = 0xff;
vertices[2].rgbaq.B = 0xff;
vertices[0].xyz.X = p0.x << SUBPIXEL_BITS;
vertices[0].xyz.Y = p0.y << SUBPIXEL_BITS;
vertices[1].xyz.X = p1.x << SUBPIXEL_BITS;
vertices[1].xyz.Y = p1.y << SUBPIXEL_BITS;
vertices[2].xyz.X = p2.x << SUBPIXEL_BITS;
vertices[2].xyz.Y = p2.y << SUBPIXEL_BITS;
PRIMBits prim = {};
prim.TME = 0; // Turn off texturing.
prim.IIP = 1; // Interpolate RGBA (Gouraud shading)
prim.PRIM = int(PRIMType::TriangleList);
static const GIFAddr addr[] = { GIFAddr::RGBAQ, GIFAddr::XYZ2 };
constexpr uint32_t num_registers = sizeof(addr) / sizeof(addr[0]);
constexpr uint32_t num_loops = sizeof(vertices) / sizeof(vertices[0]);
iface.write_packed(prim, addr, num_registers, num_loops, vertices);
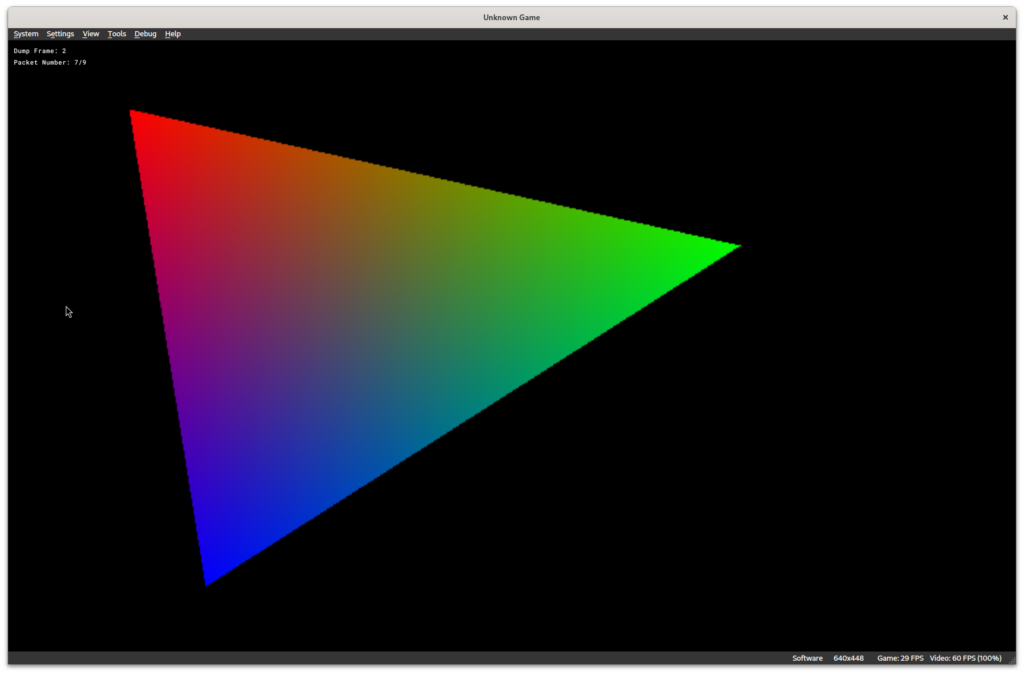
This draws a triangle. We provide coordinates directly in screen-space.
And finally, we need to program the CRTC. Most of this is just copy-pasta from whatever games tend to do.
auto &priv = iface.get_priv_register_state(); priv.pmode.EN1 = 1; priv.pmode.EN2 = 0; priv.pmode.CRTMD = 1; priv.pmode.MMOD = PMODEBits::MMOD_ALPHA_ALP; priv.smode1.CMOD = SMODE1Bits::CMOD_NTSC; priv.smode1.LC = SMODE1Bits::LC_ANALOG; priv.bgcolor.R = 0x0; priv.bgcolor.G = 0x0; priv.bgcolor.B = 0x0; priv.pmode.SLBG = PMODEBits::SLBG_ALPHA_BLEND_BG; priv.pmode.ALP = 0xff; priv.smode2.INT = 1; priv.dispfb1.FBP = 0; priv.dispfb1.FBW = 640 / BUFFER_WIDTH_SCALE; priv.dispfb1.PSM = PSMCT32; priv.dispfb1.DBX = 0; priv.dispfb1.DBY = 0; priv.display1.DX = 636; // Magic values that center the screen. priv.display1.DY = 50; // Magic values that center the screen. priv.display1.MAGH = 3; // scaling factor = MAGH + 1 = 4 -> 640 px wide. priv.display1.MAGV = 0; priv.display1.DW = 640 * 4 - 1; priv.display1.DH = 448 - 1; dump.write_vsync(0, iface); dump.write_vsync(1, iface);
When the GS is dumped, we can load it up in PCSX2 and voila:

And here’s the same .gs dump is played through parallel-gs-replayer with RenderDoc. For debugging, I’ve spent a lot of time making it reasonably convenient. The images are debug storage images where I can store before and after color, depth, debug values for interpolants, depth testing state, etc, etc. It’s super handy to narrow down problem cases. The render pass can be split into 1 or more triangle chunks as needed.

To add some textures, and flex the capabilities of the CRTC a bit, we can try uploading a texture:
int chan;
auto *buf = stbi_load("/tmp/test.png", &w, &h, &chan, 4);
iface.write_image_upload(0x300000, PSMCT32, w, h, buf,
w * h * sizeof(uint32_t));
stbi_image_free(buf);
TEX0Bits tex0 = {};
tex0.PSM = PSMCT32;
tex0.TBP0 = 0x300000 / BLOCK_ALIGNMENT_BYTES;
tex0.TBW = (w + BUFFER_WIDTH_SCALE - 1) / BUFFER_WIDTH_SCALE;
tex0.TW = Util::floor_log2(w - 1) + 1;
tex0.TH = Util::floor_log2(h - 1) + 1;
tex0.TFX = COMBINER_DECAL;
tex0.TCC = 1; // Use texture alpha as blend alpha
iface.write_register(RegisterAddr::TEX0_1, tex0);
TEX1Bits tex1 = {};
tex1.MMIN = TEX1Bits::LINEAR;
tex1.MMAG = TEX1Bits::LINEAR;
iface.write_register(RegisterAddr::TEX1_1, tex1);
CLAMPBits clamp = {};
clamp.WMS = CLAMPBits::REGION_CLAMP;
clamp.WMT = CLAMPBits::REGION_CLAMP;
clamp.MINU = 0;
clamp.MAXU = w - 1;
clamp.MINV = 0;
clamp.MAXV = h - 1;
iface.write_register(RegisterAddr::CLAMP_1, clamp);
While PS2 requires POT sizes for textures, REGION_CLAMP is handy for NPOT. Super useful for texture atlases.
struct Vertex
{
PackedUVBits uv;
PackedXYZBits xyz;
} vertices[2] = {};
for (auto &vert : vertices)
vert.xyz.Z = 1;
vertices[0].xyz.X = p0.x << SUBPIXEL_BITS;
vertices[0].xyz.Y = p0.y << SUBPIXEL_BITS;
vertices[1].xyz.X = p1.x << SUBPIXEL_BITS;
vertices[1].xyz.Y = p1.y << SUBPIXEL_BITS;
vertices[1].uv.U = w << SUBPIXEL_BITS;
vertices[1].uv.V = h << SUBPIXEL_BITS;
PRIMBits prim = {};
prim.TME = 1; // Turn on texturing.
prim.IIP = 0;
prim.FST = 1; // Use unnormalized coordinates.
prim.PRIM = int(PRIMType::Sprite);
static const GIFAddr addr[] = { GIFAddr::UV, GIFAddr::XYZ2 };
constexpr uint32_t num_registers = sizeof(addr) / sizeof(addr[0]);
constexpr uint32_t num_loops = sizeof(vertices) / sizeof(vertices[0]);
iface.write_packed(prim, addr, num_registers, num_loops, vertices);
Here we render a sprite with un-normalized coordinates.
Finally, we use the CRTC to do blending against white background.
priv.pmode.EN1 = 1; priv.pmode.EN2 = 0; priv.pmode.CRTMD = 1; priv.pmode.MMOD = PMODEBits::MMOD_ALPHA_CIRCUIT1; priv.smode1.CMOD = SMODE1Bits::CMOD_NTSC; priv.smode1.LC = SMODE1Bits::LC_ANALOG; priv.bgcolor.R = 0xff; priv.bgcolor.G = 0xff; priv.bgcolor.B = 0xff; priv.pmode.SLBG = PMODEBits::SLBG_ALPHA_BLEND_BG; priv.smode2.INT = 1; priv.dispfb1.FBP = 0; priv.dispfb1.FBW = 640 / BUFFER_WIDTH_SCALE; priv.dispfb1.PSM = PSMCT32; priv.dispfb1.DBX = 0; priv.dispfb1.DBY = 0; priv.display1.DX = 636; // Magic values that center the screen. priv.display1.DY = 50; // Magic values that center the screen. priv.display1.MAGH = 3; // scaling factor = MAGH + 1 = 4 -> 640 px wide. priv.display1.MAGV = 0; priv.display1.DW = 640 * 4 - 1; priv.display1.DH = 448 - 1;

Glorious 256×179 logo 😀
Implementation details
The rendering pipeline
Before we get into the page tracker, it’s useful to define a rendering pipeline where synchronization is implied between each stage.
- Synchronize CPU copy of VRAM to GPU. This is mostly unused, but happens for save state load, or similar
- Upload data to VRAM (or perform local-to-local copy)
- Update CLUT cache from VRAM
- Unswizzle VRAM into VkImages that can be sampled directly, and handle palettes as needed, sampling from CLUT cache
- Perform rendering
- Synchronize GPU copy of VRAM back to CPU. This will be useful for readbacks. Then CPU should be able to unswizzle directly from a HOST_CACHED_BIT buffer as needed
This pipeline matches what we expect a game to do over and over:
- Upload texture to VRAM
- Upload palette to VRAM
- Update CLUT cache
- Draw with texture
- Trigger unswizzle from VRAM into VkImage if needed
- Begins building a “render pass”, a batch of primitives
When there are no backwards hazards here, we can happily keep batching and defer any synchronization. This is critical to get any performance out of this style of renderer.
Some common hazards here include:
Copy to VRAM which was already written by copy
This is often a false positive, but we cannot track per-byte. This becomes a simple copy barrier and we move on.
Copy to VRAM where a texture was sampled from, or CLUT cache read from
Since the GS has a tiny 4 MiB VRAM, it’s very common that textures are continuously streamed in, sampled from, and thrown away. When this is detected, we have to submit all vram copy work, all texture unswizzle work and then begin a new batch. Primitive batches are not disrupted.
This means we’ll often see:
- Copy xN
- Barrier
- Unswizzle xN
- Barrier
- Copy xN
- Barrier
- Unswizzle xN
- Barrier
- Rendering
Sample texture that was rendered to
Similar, but here we need to flush out everything. This basically breaks the render pass and we start another one. Too many of these is problematic for performance obviously.
Copy to VRAM where rendering happened
Basically same as sampling textures, this is a full flush.
Other hazards are ignored, since they are implicitly handled by our pipeline.
Page tracker
Arguably, the hardest part of GS emulation is dealing with hazards. VRAM is read and written to with reckless abandon and any potential read-after-write or write-after-write hazard needs to be dealt with. We cannot rely on any game doing this for us, since PS2 GS just deals with sync in most cases, and TEXFLUSH is the only real command games will use (or forget to use).
Tracking per byte is ridiculous, so my solution is to first subdivide the 4 MiB VRAM into pages. A page is the unit for frame buffers and depth buffers, so it is the most meaningful place to start.
PageState
On page granularity, we track:
- Pending frame buffer write?
- Pending frame buffer read? (read-only depth)
Textures and VRAM copies have 256 byte alignment, and to avoid a ton of false positives, we need to track on a per-block basis. There are 32 blocks per page, so a u32 bit-mask is okay.
- VRAM copy writes
- VRAM copy reads
- Pending read into CLUT cache or VkImage
- Blocks which have been clobbered by any write, on next texture cache invalidate, throw away images that overlap
As mentioned earlier, there are also cases where you can render to 24-bit color, while sampling from the upper 8-bits without hazard. We need to optimize for that case too, so there is also:
- A write mask for framebuffers
- A read mask for textures
In the example above, FB write mask is 0xffffff and texture cache mask is 0xff000000. No overlap, no invalidate 😀
For host access, there are also timeline semaphore values per page. These values state which sync point to wait for if the host desires mapped read or mapped write access. Mapped write access may require more sync than mapped read if there are pending reads on that page.
Caching textures
Every page contains a list of VkImages which have been associated with it. When a page’s textures has been invalidated, the image is destroyed and has to be unswizzled again from VRAM.
There is a one-to-many relationship with textures and pages. A texture may span more than one page, and it’s enough that only one page is clobbered before the texture is invalidated.
Overall, there are a lot of micro-details here, but the important things to note here is that conservative and simple tracking will not work on PS2 games. Tracking at a 256 byte block level and considering write/read masks is critical.
Special cases
There are various situations where we may have false positives due to how textures work. Since textures are POT sized, it’s fairly common for e.g. a 512×448 texture of a render target to be programmed as a 512×512 texture. The unused region should ideally be clamped out with REGION_CLAMP, but most games don’t. A render target might occupy those unused pages. As long as the game’s UV coordinates don’t extend into the unused red zone, there are no hazards, but this is very painful to track. We would have to analyze every single primitive to detect if it’s sampling into the red zone.
As a workaround, we ignore any potential hazard in that red zone, and just pray that a game isn’t somehow relying on ridiculous spooky-action-at-a-distance hazards to work in the game’s favor.
There are more spicy special cases, especially with texture sampling feedback, but that will be for later.
Updating CLUT in a batched way
Since we want to batch texture uploads, we have to batch CLUT uploads too. To make this work, we have 1024 copies of CLUT, a ring buffer of snapshots.
One workgroup loops through the updates and writes them to an SSBO. I did a similar thing for N64 RDP’s TMEM update, where TMEM was instanced. Fortunately, CLUT update is far simpler than TMEM update.
shared uint tmp_clut[512];
// ...
// Copy from previous instance to allow a
// CLUT entry to be partially overwritten and used later
uint read_index = registers.read_index * CLUT_SIZE_16;
tmp_clut[gl_LocalInvocationIndex] =
uint(clut16.data[read_index]);
tmp_clut[gl_LocalInvocationIndex + 256u] =
uint(clut16.data[read_index + 256u]);
barrier();
for (uint i = 0; i < registers.clut_count; i++)
{
// ...
if (active_lane)
{
// update tmp_clut. If 256 color, all threads participate.
// 16 color update is a partial update.
}
// Flush current CLUT state to SSBO.
barrier();
clut16.data[gl_LocalInvocationIndex + clut.instance * CLUT_SIZE_16] =
uint16_t(tmp_clut[gl_LocalInvocationIndex]);
clut16.data[gl_LocalInvocationIndex + clut.instance * CLUT_SIZE_16 + 256u] =
uint16_t(tmp_clut[gl_LocalInvocationIndex + 256u]);
barrier();
}
One potential optimization is that for 256 color / 32 bpp updates, we can parallelize the CLUT update, since nothing from previous iterations will be preserved, but the CLUT update time is tiny anyway.
Unswizzling textures from VRAM
Since this is Vulkan, we can just allocate a new VkImage, suballocate it from VkDeviceMemory and blast it with a compute shader.

Using Vulkan’s specialization constants, we specialize the texture format and all the swizzling logic becomes straight forward code.
REGION_REPEAT shenanigans is also resolved here, so that the ubershader doesn’t have to consider that case and do manual bilinear filtering.
Even for render targets, we roundtrip through the VRAM SSBO. There is not really a point going to the length of trying to forward render targets into textures. Way too many bugs to squash and edge cases to think about.
Triangle setup and binning
Like paraLLEl-RDP, paraLLEl-GS is a tile-based renderer. Before binning can happen, we need triangle setup. As inputs, we provide attributes in three arrays.
Position
struct VertexPosition
{
ivec2 pos;
float z; // TODO: Should be uint for 32-bit Z.
int padding; // Free real-estate?
};
Per-Vertex attributes
struct VertexAttribute
{
vec2 st;
float q;
uint rgba; // unpackUnorm4x8
float fog; // overkill, but would be padding anyway
u16vec2 uv;
};
Per-primitive attributes
struct PrimitiveAttribute
{
i16vec4 bb; // Scissor
// Index into state UBO, as well as misc state bits.
uint state;
// Texture state which should be scalarized. Affects code paths.
// Also holds the texture index (for bindless).
uint tex;
// Texture state like lod scaling factors, etc.
// Does not affect code paths.
uint tex2;
uint alpha; // AFIX / AREF
uint fbmsk;
uint fogcol;
};
For rasterization, we have a straight forward barycentric-based rasterizer. It is heavily inspired by https://fgiesen.wordpress.com/2011/07/06/a-trip-through-the-graphics-pipeline-2011-part-6/, which in turn is based on A Parallel Algorithm for Polygon Rasterization (Paneda, 1988) and describes the “standard” way to write a rasterizer with parallel hardware. Of course, the PS2 GS is DDA, i.e. a scanline rasterizer, but in practice, this is just a question of nudging ULPs of precision, and since I’m not aware of a bit-exact description of the GS’s DDA, this is fine. paraLLEl-RDP implements the raw DDA form for example. It’s certainly possible if we have to.
As an extension to a straight-forward triangle rasterizer, I also need to support parallelograms. This is used to implement wide-lines and sprites. Especially wide-line is kinda questionable, but I’m not sure it’s possible to fully solve up-scaling + Bresenham in the general case. At least I haven’t run into a case where this really matters.
Evaluating coverage and barycentric I/J turns into something like this:
bool evaluate_coverage_single(PrimitiveSetup setup,
bool parallelogram,
ivec2 parallelogram_offset,
ivec2 coord, inout float i, inout float j)
{
int a = idot3(setup.a, coord);
int b = idot3(setup.b, coord);
int c = idot3(setup.c, coord);
precise float i_result = float(b) * setup.inv_area + setup.error_i;
precise float j_result = float(c) * setup.inv_area + setup.error_j;
i = i_result;
j = j_result;
if (parallelogram && a.x < 0)
{
b += a + parallelogram_offset.x;
c += a + parallelogram_offset.y;
a = 0;
}
return all(greaterThanEqual(ivec3(a, b, c), ivec3(0)));
}
inv_area is computed in a custom fixed-point RCP, which is ~24.0 bit accurate. Using the standard GPU RCP would be bad since it’s just ~22.5 bit accurate and not consistent across implementations. There is no reason to skimp on reproducibility and accuracy, since we’re not doing work per-pixel.
error_i and error_j terms are caused by the downsampling of the edge equations and tie-break rules. As a side effect of the GS’s [-4k, +4k] pixel range, the range of the cross-product requires 33-bit in signed integers. By downsampling a bit, we can get 32-bit integer math to work just fine with 8 sub-pixel accuracy for super-sampling / multi-sampling. Theoretically, this means our upper up-sampling limit is 8×8, but that’s ridiculous anyway, so we’re good here.
The parallelogram offsets are very small numbers meant to nudge the tie-break rules in our favor as needed. The exact details of the implementation escape me. I wrote that code years ago. It’s not very hard to derive however.
Every primitive gets a struct of transformed attributes as well. This is only read if we actually end up shading a primitive, so it’s important to keep this separate to avoid polluting caches with too much garbage.
struct TransformedAttributes
{
vec4 stqf0;
vec4 stqf1;
vec4 stqf2;
uint rgba0;
uint rgba1;
uint rgba2;
uint padding;
vec4 st_bb;
};
Using I/J like this will lead to small inaccuracies when interpolating primitives which expect to land exactly on the top-left corner of a texel with NEAREST filtering. To combat this, a tiny epsilon offset is used when snapping texture coordinates. Very YOLO, but what can you do. As far as I know, hardware behavior is sub-texel floor, not sub-texel round.
precise vec2 uv_1 = uv * scale_1;
// Want a soft-floor here, not round behavior.
const float UV_EPSILON_PRE_SNAP = 1.0 / 16.0;
// We need to bias less than 1 / 512th texel, so that linear filter will RTE to correct subpixel.
// This is a 1 / 1024th pixel bias to counter-act any non-POT inv_scale_1 causing a round-down event.
const float UV_EPSILON_POST_SNAP = 16.0 / 1024.0;
if (sampler_clamp_s)
uv_1.x = texture_clamp(uv_1.x, region_coords.xz, LOD_1);
if (sampler_clamp_t)
uv_1.y = texture_clamp(uv_1.y, region_coords.yw, LOD_1);
// Avoid micro-precision issues with UV and flooring + nearest.
// Exact rounding on hardware is somwhat unclear.
// SotC requires exact rounding precision and is hit particularly bad.
// If the epsilon is too high, then FF X save screen is screwed over,
// so ... uh, ye.
// We likely need a more principled approach that is actually HW accurate in fixed point.
uv_1 = (floor(uv_1 * 16.0 + UV_EPSILON_PRE_SNAP) + UV_EPSILON_POST_SNAP) *
inv_scale_1 * 0.0625;
Binning
This is mostly uninteresting. Every NxN pixel block gets an array of u16 primitive indices to shade. This makes the maximum number of primitives per render pass 64k, but that’s enough for PS2 games. Most games I’ve seen so far tend to be between 10k and 30k primitives for the “main” render pass, but I haven’t tested the real juggernauts of primitive grunt yet, but even so, having to do a little bit of incremental rendering isn’t a big deal.
NxN is usually 32×32, but it can be dynamically changed depending on how heavy the geometry load is. For large resolutions and high primitive counts, the binning and memory cost is unacceptable if the resolution is just 16×16 for example. One subgroup is responsible for iterating through all primitives in a block.
Since binning and triangle is state-less, triangle-setup and binning for back-to-back passes are batched up nicely to avoid lots of silly barriers.
The ubershader
A key difference between N64 and PS2 is fill-rate and per-pixel complexity. For N64, the ideal approach is to specialize the rasterizing shader, write out per-pixel color + depth + coverage + etc, then merge that data in a much simpler ubershader that only needs to consider depth and blend state rather than full texturing state and combiner state. This is very bandwidth intensive on the GPU, but the alternative is the slowest ubershader written by man. We’re saved by the fact that N64 fill-rate is abysmal. Check out this video by Kaze to see how horrible it is.
The GS is a quite different beast. Fill-rate is very high, and per-pixel complexity is fairly low, so a pure ubershader is viable. We can also rely on bindless this time around too, so texturing complexity becomes a fraction of what I had to deal with on N64.
Fine-grained binning
Every tile is 4×4, 4×8 and 8×8 for subgroup sizes 16, 32 and 64 respectively. For super-sampling it’s even smaller (it’s 4×4 / 4×8 / 8×8 in the higher resolution domain instead).
In the outer loop, we pull in up to SubgroupSize’s worth of primitives, and bin them in parallel.
for (int i = 0; i < tile.coarse_primitive_count;
i += int(gl_SubgroupSize))
{
int prim_index = i + int(gl_SubgroupInvocationID);
bool is_last_iteration = i + int(gl_SubgroupSize) >=
tile.coarse_primitive_count;
// Bin primitives to tile.
bool binned_to_tile = false;
uint bin_primitive_index;
if (prim_index < tile.coarse_primitive_count)
{
bin_primitive_index =
uint(coarse_primitive_list.data[
tile.coarse_primitive_list_offset + prim_index]);
binned_to_tile = primitive_intersects_tile(bin_primitive_index);
}
// Iterate per binned primitive, do per pixel work now.
// Scalar loop.
uvec4 work_ballot = subgroupBallot(binned_to_tile);
In the inner loop, we can do a scalarized loop which checks coverage per-pixel, one primitive at a time.
// Scalar data
uint bit = subgroupBallotFindLSB(work_ballot);
if (gl_SubgroupSize == 64)
{
if (bit >= 32)
work_ballot.y &= work_ballot.y - 1;
else
work_ballot.x &= work_ballot.x - 1;
}
else
{
work_ballot.x &= work_ballot.x - 1;
}
shade_primitive_index = subgroupShuffle(bin_primitive_index, bit);
Early Z
We can take advantage of early-Z testing of course, but we have to be careful if there are rasterized pixels we haven’t resolved yet, and there are Z-writes in flight. In this case we have to defer to late Z to perform test.
// We might have to remove opaque flag.
bool pending_z_write_can_affect_result =
(pixel.request.z_test || !pixel.request.z_write) &&
pending_shade_request.z_write;
if (pending_z_write_can_affect_result)
{
// Demote the pixel to late-Z,
// it's no longer opaque and we cannot discard earlier pixels.
// We need to somehow observe the previous results.
pixel.opaque = false;
}
Deferred on-tile shading
Since we’re an uber-shader, all pixels are “on-chip”, i.e. in registers, so we can take advantage of culling pixels that won’t be visible anyway. The basic idea here is that after rasterization, if a pixel is considered opaque, it will simply replace the shading request that exists for that framebuffer coordinate. It won’t be visible at all anyway.
Lazy pixel shading
We only need to perform shading when we really have to, i.e., we’re shading a pixel that depends on the previous pixel’s results. This can happen for e.g. alpha test (if test fails, we preserve existing data), color write masks, or of course, alpha blending.
If our pixel remains opaque, we can just kill the pending pixel shade request. Very nice indeed. The gain here wasn’t as amazing as I had hoped since PS2 games love blending, but it helps culling out a lot of shading work.
if (pixel.request.coverage > 0)
{
need_flush = !pixel.opaque && pending_shade_request.coverage > 0;
// If there is no hazard, we can overwrite the pending pixel.
// If not, defer the update until we run a loop iteration.
if (!need_flush)
{
set_pending_shade_request(pixel.request, shade_primitive_index);
pixel.request.coverage = 0;
pixel.request.z_write = false;
}
}
If we have flushes that need to happen, we do so if one pixel needs it. It’s just as fast to resolve all pixels anyway.
// Scalar branch
if (subgroupAny(need_flush))
{
shade_resolve();
if (has_work && pixel.request.coverage > 0)
set_pending_shade_request(pixel.request, shade_primitive_index);
}
The resolve is a straight forward waterfall loop that stays in uniform control flow to be well defined on devices without maximal reconvergence support.
while (subgroupAny(has_work))
{
if (has_work)
{
uint state_index =
subgroupBroadcastFirst(pending_shade_request.state);
uint tex = subgroupBroadcastFirst(prim_tex);
if (state_index == pending_shade_request.state && prim_tex == tex)
{
has_work = false;
shade_resolve(pending_primitive_index, state_index, tex);
}
}
}
This scalarization ensures that all branches on things like alpha test mode, blend modes, etc, are purely scalar, and GPUs like that. Scalarizing on the texture index is technically not that critical, but it means we end up hitting the same branches for filtering modes, UBOs for scaling factors are loaded uniformly, etc.
When everything is done, the resulting framebuffer color and depth is written out to SSBO. GPU bandwidth is kept to a minimum, just like a normal TBDR renderer.
Super-sampling
Just implementing single sampled rendering isn’t enough for this renderer to be really useful. The software renderer is certainly quite fast, but not fast enough to keep up with intense super-sampling. We can fix that now.
For e.g. 8x SSAA, we keep 10 versions of VRAM on the GPU.
- 1 copy represents the single-sampled VRAM. It is super-sampled.
- 1 copy represents the reference value for single-sampled VRAM. This allows us to track when we should discard the super-samples and splat the single sample to all. This can happen if someone copies to VRAM over a render target for whatever reason.
- 8 copies which each represent the super-samples. Technically, we can reconstruct a higher resolution image from these samples if we really want to, but only the CRTC could easily do that.
When rendering super-sampled, we load the single-sampled VRAM and reference. If they match, we load the super-sampled version. This is important for cases where we’re doing incremental rendering.
On tile completion we use clustered subgroup ops to do multi-sample resolve, then write out the super-samples, and the two single-sampled copies.
uvec4 ballot_color = subgroupBallot(fb_color_dirty);
uvec4 ballot_depth = subgroupBallot(fb_depth_dirty);
// No need to mask, we only care about valid ballot for the
// first sample we write-back.
if (NUM_SAMPLES >= 16)
{
ballot_color |= ballot_color >> 8u;
ballot_depth |= ballot_depth >> 8u;
}
if (NUM_SAMPLES >= 8)
{
ballot_color |= ballot_color >> 4u;
ballot_depth |= ballot_depth >> 4u;
}
if (NUM_SAMPLES >= 4)
{
ballot_color |= ballot_color >> 2u;
ballot_depth |= ballot_depth >> 2u;
}
ballot_color |= ballot_color >> 1u;
ballot_depth |= ballot_depth >> 1u;
// GLSL does not accept cluster reduction as spec constant.
if (NUM_SAMPLES == 16)
fb_color = packUnorm4x8(subgroupClusteredAdd(
unpackUnorm4x8(fb_color), 16) / 16.0);
else if (NUM_SAMPLES == 8)
fb_color = packUnorm4x8(subgroupClusteredAdd(
unpackUnorm4x8(fb_color), 8) / 8.0);
else if (NUM_SAMPLES == 4)
fb_color = packUnorm4x8(subgroupClusteredAdd(
unpackUnorm4x8(fb_color), 4) / 4.0);
else
fb_color = packUnorm4x8(subgroupClusteredAdd(
unpackUnorm4x8(fb_color), 2) / 2.0);
fb_color_dirty = subgroupInverseBallot(ballot_color);
fb_depth_dirty = subgroupInverseBallot(ballot_depth);
The main advantage of super-sampling over straight up-scaling is that up-scaling will still have jagged edges, and super-sampling retains a coherent visual look where 3D elements have similar resolution as UI elements. One of my pet peeves is when UI elements have a significantly different resolution from 3D objects and textures. HD texture packs can of course alleviate that, but that’s a very different beast.
Super-sampling also lends itself very well to CRT post-processing shading, which is also a nice bonus.
Dealing with super-sampling artifacts
It’s a fact of life that super-sampling always introduces horrible artifacts if not handled with utmost care. Mitigating this is arguably easier with software renderers over traditional graphics APIs, since we’re not limited by the fixed function interpolators. These tricks won’t make it perfect by any means, but it greatly mitigates jank in my experience, and I already fixed many upscaling bugs that GSdx Vulkan backend does not solve as we shall see later.
Sprite primitives should always render at single-rate
Sprites are always UI elements or similar, and games do not expect us to up-scale them. Doing so either results in artifacts where we sample outside the intended rect, or we risk overblurring the image if bilinear filtering is used.
The trick here is just to force-snap the pixel coordinate we use when rasterizing and interpolating. This is very inefficient of course, but UI shouldn’t take up the entire screen. And if it does (like in a menu), the GPU load is tiny anyway.
const uint SNAP_RASTER_BIT = (1u << STATE_BIT_SNAP_RASTER); const uint SNAP_ATTR_BIT = (1u << STATE_BIT_SNAP_ATTRIBUTE); if (SUPER_SAMPLE && (prim_state & SNAP_RASTER_BIT) != 0) fb_pixel = tile.fb_pixel_single_rate; res.request.coverage = evaluate_coverage( prim, fb_pixel, i, j, res.request.multisample, SAMPLING_RATE_DIM_LOG2);
Flat primitives should interpolate at single-pixel coordinate
Going further, we can demote SSAA interpolation to MSAA center interpolation dynamically. Many UI elements are unfortunately rendered with normal triangles, so we have to be a bit more careful. This snap only affects attribute interpolation, not Z of course.
res.request.st_bb = false;
if (SUPER_SAMPLE &&
(prim_state & (SNAP_RASTER_BIT | SNAP_ATTR_BIT)) == SNAP_ATTR_BIT)
{
vec2 snap_ij = evaluate_barycentric_ij(
prim.b, prim.c, prim.inv_area,
prim.error_i, prim.error_j, tile.fb_pixel_single_rate,
SAMPLING_RATE_DIM_LOG2);
i = snap_ij.x;
j = snap_ij.y;
res.request.st_bb = true;
}
Here, we snap interpolation to the top-left pixel. This fixes any artifacts for primitives which align their rendering to a pixel center, but some games are mis-aligned, so this snapping can cause texture coordinates to go outside the expected area. To clean this up, we compute a bounding box of final texture coordinates. Adding bounding boxes can technically cause notorious block-edge artifacts, but that was mostly a thing on PS1 since emulators like to convert nearest sampling to bilinear.
The heuristic for this is fairly simple. If perspective is used, if all vertices in a triangle have exact same Q, we assume it’s a flat UI primitive. The primitive’s Z coordinates must also match. This is done during triangle setup on the GPU. There can of course be false positives here, but it should be rare. In my experience this hack works well enough in the games I tried.
Results
Here’s a good example of up-sampling going awry in PCSX2. This is with Vulkan backend:


Notice the bloom on the glass being mis-aligned and a subtle (?) rectangular pattern being overlaid over the image. This is caused by a post-processing pass rendering in a page-like pattern, presumably to optimize for GS caching behavior.

With 8x SSAA in paraLLEl-GS it looks like this instead. There is FSR1 post-upscale in effect here which changes the look a bit, but the usual trappings of bad upscale cannot be observed here. This is another reason to do super-sample; texture mis-alignment has a tendency to fix itself.
Also, if you’re staring at the perf numbers, this is RX 7600 in a low power state :’)
Typical UI issues can be seen in games as well. Here’s native resolution:

and 4x upscale, which … does not look acceptable.

This UI is tricky to render in upscaled mode, since it uses triangles, but the MSAA snap trick above works well and avoids all artifacts. With straight upscale, this is hard to achieve in normal graphics APIs since you’d need interpolateAtOffset beyond 0.5 pixels, which isn’t supported. Perhaps you could do custom interpolation with derivatives or something like that, but either way, this glitch can be avoided. The core message is basically to never upscale UI beyond plain nearest neighbor integer scale. It just looks bad.
There are cases where PCSX2 asks for high blending accuracy. One example is MGS2, and I found a spot where GPU perf is murdered. My desktop GPU cannot keep 60 FPS here at 4x upscale. PCSX2 asks you to turn up blend-accuracy for this game, but …

What happens here is we hit the programmable blending path with barrier between every primitive. Ouch! This wouldn’t be bad for the tiler mobile GPUs, but for a desktop GPU, it is where perf goes to die. The shader in question does subpassLoad and does programmable blending as expected. Barrier, tiny triangle, barrier, tiny triangle, hnnnnnnng.

paraLLEl-GS on the other hand always runs with 100% blend accuracy (assuming no bugs of course). Here’s 16xSSAA (equivalent to 4x upscale). This is just 25 W and 17% GPU utilization on RX 7600. Not bad.

Other difficult cases include texture sampling feedback. One particular case I found was in Valkyrie Profile 2.

This game has a case where it’s sampling it’s own pixel’s alpha as a palette index. Quirky as all hell, and similar to MGS2 there’s a barrier between every pixel.
In paraLLEl-GS, this case is detected, and we emit a magical texture index, which resolved to just looking at in-register framebuffer color instead. Programmable blending go brr. These cases have to be checked per primitive, which is quite rough on CPU time, but it is what it is. If we don’t hit the good path, GPU performance completely tanks.
The trick here is to analyze the effective UV coordinates, and see if UV == framebuffer position. If we fall off this path, we have to go via texture uploads, which is bad.
ivec2 uv0_delta = uv0 - pos[0].pos;
ivec2 uv1_delta = uv1 - pos[1].pos;
ivec2 min_delta = min(uv0_delta, uv1_delta);
ivec2 max_delta = max(uv0_delta, uv1_delta);
if (!quad)
{
ivec2 uv2_delta = uv2 - pos[2].pos;
min_delta = min(min_delta, uv2_delta);
max_delta = max(max_delta, uv2_delta);
}
int min_delta2 = min(min_delta.x, min_delta.y);
int max_delta2 = max(max_delta.x, max_delta.y);
// The UV offset must be in range of [0, 2^SUBPIXEL_BITS - 1].
// This guarantees snapping with NEAREST.
// 8 is ideal. That means pixel centers during interpolation
// will land exactly in the center of the texel.
// In theory we could allow LINEAR if uv delta was
// exactly 8 for all vertices.
if (min_delta2 < 0 || max_delta2 >= (1 << SUBPIXEL_BITS))
return ColorFeedbackMode::Sliced;
// Perf go brrrrrrr.
return ColorFeedbackMode::Pixel;
if (feedback_mode == ColorFeedbackMode::Pixel)
{
mark_render_pass_has_texture_feedback(ctx.tex0.desc);
// Special index indicating on-tile feedback.
// We could add a different sentinel for depth feedback.
// 1024k CLUT instances and 32 sub-banks. Fits in 15 bits.
// Use bit 15 MSB to mark feedback texture.
return (1u << (TEX_TEXTURE_INDEX_BITS - 1u)) |
(render_pass.clut_instance * 32 + uint32_t(ctx.tex0.desc.CSA));
}
It’s comfortably full-speed on PCSX2 here, despite the copious number of barriers, but paraLLEl-GS is reasonably close perf-wise, actually. At 8x SSAA.

Overall, we get away with 18 render pass barriers instead of 500+ which was the case without this optimization. You may notice the interlacing artifacts on the swirlies. Silly game has a progressive scan output, but downsamples it on its own to a field before hitting CRTC, hnnnnng 🙁 Redirecting framebuffer locations in CRTC might work as a per-game hack, but either way, I still need to consider a better de-interlacer. Some games actually render explicitly in fields (640×224), which is very annoying.
This scene in the MGS2 intro also exposes some funny edge cases with sampling.

To get the camo effect, it’s sampling its own framebuffer as a texture, with overlapping coordinates, but not pixel aligned, so this raises some serious questions about caching behavior. PCSX2 doesn’t seem to add any barriers here, and I kinda had to do the same thing. It looks fine to me compared to software renderer at least.
if (feedback_mode == ColorFeedbackMode::Sliced)
{
// If game explicitly clamps the rect to a small region,
// it's likely doing well-defined feedbacks.
// E.g. Tales of Abyss main menu ping-pong blurs.
// This code is quite flawed,
// and I'm not sure what the correct solution is yet.
if (desc.clamp.desc.WMS == CLAMPBits::REGION_CLAMP &&
desc.clamp.desc.WMT == CLAMPBits::REGION_CLAMP)
{
ivec4 clamped_uv_bb(
int(desc.clamp.desc.MINU),
int(desc.clamp.desc.MINV),
int(desc.clamp.desc.MAXU),
int(desc.clamp.desc.MAXV));
ivec4 hazard_bb(
std::max<int>(clamped_uv_bb.x, bb.x),
std::max<int>(clamped_uv_bb.y, bb.y),
std::min<int>(clamped_uv_bb.z, bb.z),
std::min<int>(clamped_uv_bb.w, bb.w));
cache_texture = hazard_bb.x > hazard_bb.z ||
hazard_bb.y > hazard_bb.w;
}
else
{
// Questionable,
// but it seems almost impossible to do this correctly and fast.
// Need to emulate the PS2 texture cache exactly,
// which is just insane.
// This should be fine.
cache_texture = false;
}
}
If we’re in a mode where texture points directly to the frame buffer we should relax the hazard tracking a bit to avoid 2000+ barriers. This is clearly spooky since Tales of Abyss’s bloom effect as shown earlier depends on this to be well behaved, but in that case, at least it uses REGION_CLAMP to explicitly mark the ping-pong behavior. I’m not sure what the proper solution is here.
The only plausible solution to true bit-accuracy with real hardware is to emulate the caches directly, one pixel at a time. You can kiss performance good bye in that case.
One of the worst stress tests I’ve found so far has to be Shadow of the Collosus. Just in the intro, we can make the GPU kneel down to 24 FPS with maximum blend accuracy on PCSX2, at just 2x upscale! Even with normal blending accuracy, it is extremely heavy during the intro cinematic.

At 8x SSAA, perf is still looking pretty good for paraLLEl-GS, but it’s clearly sweating now.

We’re actually still CPU bound on the geometry processing. Optimizing the CPU code hasn’t been a huge priority yet. There’s unfortunately a lot of code that has to run per-primitive, where hazards can happen around every corner that has to be dealt with somehow. I do some obvious optimizations, but it’s obviously not as well-oiled as PCSX2 in that regard.

Deck?
It seems fast enough to comfortably do 4x SSAA. Maybe not in SotC, but … hey. 😀
What now?
For now, the only real way to test this is through GS dumps. There’s a hack-patch for PCSX2 that lets you dump out a raw GS trace, which can be replayed. This works via mkfifo as a crude hack to test in real-time, but some kind of integration into an emulator needs to happen at some point if this is to turn into something that’s useful for end users.
There’s guaranteed to be a million bugs lurking since the PS2 library is ridiculously large and there’s only so much I can be arsed to test myself. At least, paraLLEl-GS has now become my preferred way to play PS2 games, so I can say mission complete.
A potential use case for this is due to its standalone library nature, it may be useful as very old-school rendering API for the old greybeards around that still yearn for the day of PS2 programming for whatever reason :p