David Sacks, the White House's AI and crypto czar, told Fox News on Tuesday that there is "substantial evidence" Chinese AI startup DeepSeek "distilled" knowledge from OpenAI's models—an act he likened to IP theft. This poses a massive national security risk and might be critical for US AI firms to tighten IP protections.
"There is substantial evidence that what DeepSeek did here is they distilled the knowledge out of OpenAI's model. I don't think OpenAI is very happy about this. One thing you will see over the next few months is that our leading AI companies will take steps to prevent distillation," Sacks said.
On Wednesday, OpenAI confirmed to the Financial Times that evidence of "distillation" was found in how the Chinese AI startup used the OpenAI application programming interface (API) to siphon large amounts of data for building its model.
"The issue is when you [take it out of the platform and] are doing it to create your own model for your own purposes," a source close to OpenAI told FT. They noted distillation is a breach of OpenAI's terms of service.
Bloomberg reported that OpenAI's partner Microsoft was also investigating distillation concerns and found evidence that DeepSeek researchers violated OpenAI's terms of service last year.
Meanwhile, DeepSeek's research even admits its R1 model is based on other open-source systems:
"We demonstrate that the reasoning patterns of larger models can be distilled into smaller models, resulting in better performance compared to the reasoning patterns discovered through RL on small models. The open source DeepSeek-R1, as well as its API, will benefit the research community to distill better smaller models in the future."
AI experts told FT that DeepSeek's model generated responses that indicated it had been trained on OpenAI's GPT-4.
DeepSeek claimed its latest model was only trained on 2,048 Nvidia H800 GPUs over two months, costing about $5.5 million, with 2.8 million GPU hours, far less than rival models by MAG7 companies that spent years and tens of billions of dollars.
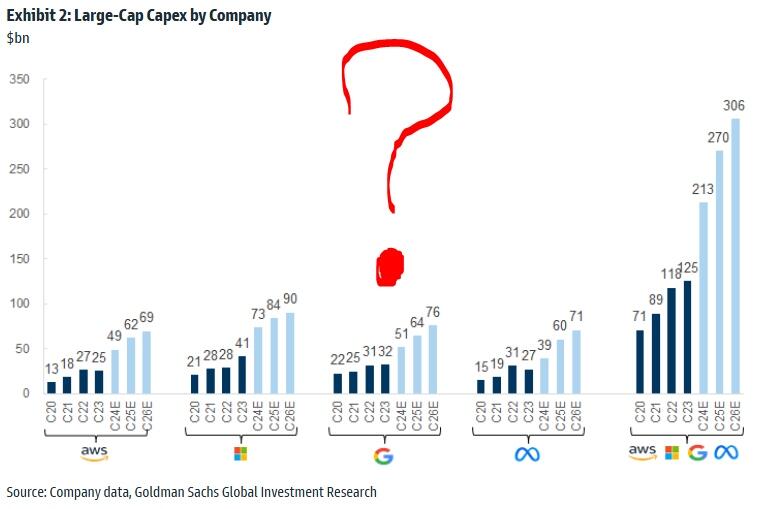
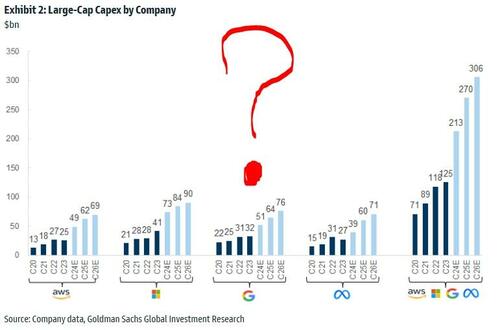
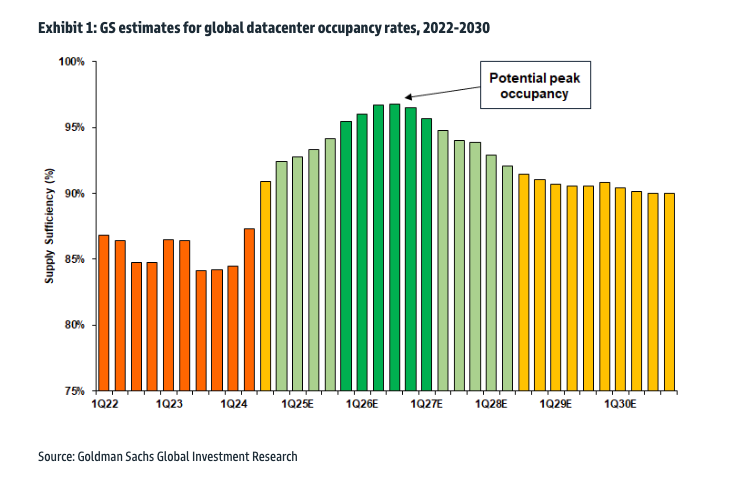
On Monday, Goldman's Rich Privorotsky told clients that DeepSeek's model is allegedly "40-50x more efficient than other large language models," and this "naturally raises the question of whether so much data center capacity is necessary."
Ironically, DeepSeek's IP theft of OpenAI's model through distillation comes as the US startup faces lawsuits for scraping training data from media outlets and other sources.
Interesting view...
. . .