We've released version 0.4.2 of zlib-rs, featuring a number of substantial performance improvements. We are now (to our knowledge) the fastest api-compatible zlib implementation for decompression, and beat the competition in the most important compression cases too.
We've built a dashboard that shows the performance of the current main branch compared to other implementations, and tracks our performance over time to catch any regressions and visualize our progress.
This post compares zlib-rs to the latest zlib-ng and, for decompression, also to zlib-chromium. These are the leading C zlib implementations that focus on performance. We'll soon write a blog post with more technical details, and only cover the most impactful changes briefly.
Decompression
Last time, we benchmarked using the target-cpu=native flag. That gave the best results for our implementation, but was not entirely fair because our rust implementation could assume that certain SIMD capabilities would be available, while zlib-ng had to check for them at runtime.
We have now made some changes so that we can efficiently select the most optimal implementation at runtime too.
Multiversioning
Picking the best version of a function is known as multiversioning. We have a baseline implementation that works on all CPUs, and then some number of specialized versions that use SIMD instructions or other features that may or may not be available on a particular CPU. The challenge is to always pick the optimal implementation, but with minimal runtime cost. That means we want to do the runtime check as few times as possible, and then perform a large chunk of work.
Today, multiversioning is not natively supported in rust. There are proposals for adding it (which we're very excited about!), but for now, we have to implement it manually which unfortunately involves some unsafe code. We'll write more about this soon (for the impatient, the relevant code is here).
DFA optimizations
The C code is able to use switch implicit fallthroughs to generate very efficient code. Rust does not have an equivalent of this mechanism, and this really slowed us down when data comes in in small chunks.
Nikita Popov suggested we try the -Cllvm-args=-enable-dfa-jump-thread option, which recovers most of the performance here. It performs a kind of jump threading for deterministic finite automata, and our decompression logic matches this pattern.
LLVM does not currently enable this flag by default, but that is the plan eventually. We're also looking into supporting this optimization in rustc itself, and making it more fine-grained than just blindly applying it to a whole project and hoping for the best.
These efforts are a part of a proposed project goal and Trifecta Tech Foundation's code generation initiative.
Benchmarks
As far as we know, we're the fastest api-compatible zlib implementation today for decompression. Not only do we beat zlib-ng by a fair margin, we're also faster than the implementation used in chromium.
Like before, our benchmark is decompressing a compressed version of silesia-small.tar, feeding the state machine the input in power-of-2 sized chunks. Small chunk sizes simulate the streaming use case, larger chunk sizes model cases where the full input is availabe.
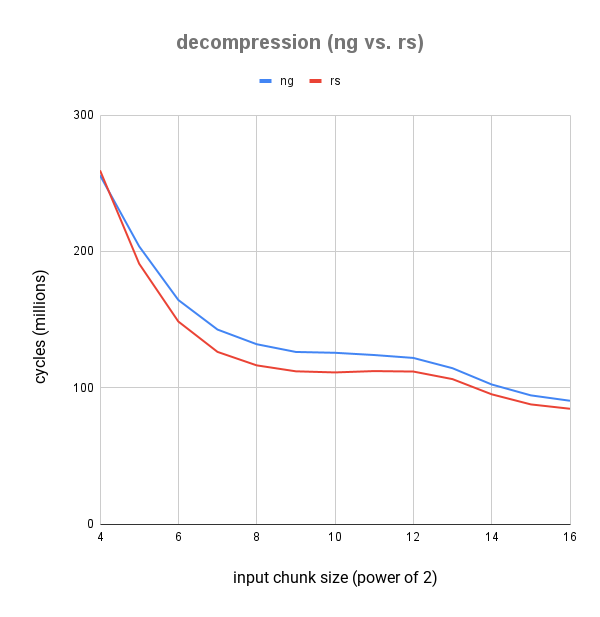
versus zlib-ng

We're now significantly faster than zlib-ng for all but the smallest chunk size. A chunk size of 2^4 = 16 bytes is very unlikely to be relevant for performance in practice because the input can just be buffered and then decompressed in larger chunks.
We are however significantly faster than zlib-ng at the more relevant chunk sizes: well over 10% for inputs of 1kb, and over 6% for inputs of 65kb.
| chunk size | zlib-ng | zlib-rs | Δ |
|---|---|---|---|
| 4 | 255.77M ± 179.04K | 259.40M ± 492.87K | 💩 +1.40% |
| 5 | 203.64M ± 305.47K | 190.91M ± 343.64K | 🚀 -6.67% |
| 6 | 164.30M ± 131.44K | 148.51M ± 193.07K | 🚀 -10.63% |
| 7 | 142.62M ± 156.88K | 126.24M ± 113.62K | 🚀 -12.98% |
| 8 | 131.87M ± 210.99K | 116.36M ± 116.36K | 🚀 -13.33% |
| 9 | 126.19M ± 227.14K | 111.99M ± 100.79K | 🚀 -12.68% |
| 10 | 125.58M ± 150.70K | 111.18M ± 111.18K | 🚀 -12.95% |
| 11 | 123.94M ± 136.34K | 112.16M ± 201.89K | 🚀 -10.50% |
| 12 | 121.81M ± 109.63K | 111.82M ± 89.45K | 🚀 -8.94% |
| 13 | 114.27M ± 114.27K | 106.27M ± 138.15K | 🚀 -7.53% |
| 14 | 102.34M ± 133.04K | 95.13M ± 95.13K | 🚀 -7.57% |
| 15 | 94.35M ± 132.09K | 87.72M ± 96.49K | 🚀 -7.56% |
| 16 | 90.40M ± 108.48K | 84.53M ± 84.53K | 🚀 -6.94% |
versus chromium
For decompression, the zlib implementation used in the chromium project (found here, which we use via a modified version of libz-sys) is often faster than zlib-ng. However, we also beat it at this benchmark for the most relevant chunk sizes.

Interestingly, zlib-chromium is mostly faster for the smaller chunk sizes, while for larger chunk sizes performance is fairly comparable to zlib-ng.
| chunk size | zlib-chromium | zlib-rs | Δ |
|---|---|---|---|
| 4 | 227.39M ± 363.82K | 259.40M ± 492.87K | 💩 +12.34% |
| 5 | 181.29M ± 471.36K | 190.91M ± 343.64K | 💩 +5.04% |
| 6 | 146.09M ± 160.70K | 148.51M ± 193.07K | 💩 +1.63% |
| 7 | 126.91M ± 164.98K | 126.24M ± 113.62K | 🚀 -0.53% |
| 8 | 118.13M ± 94.51K | 116.36M ± 116.36K | 🚀 -1.53% |
| 9 | 114.83M ± 91.86K | 111.99M ± 100.79K | 🚀 -2.53% |
| 10 | 113.20M ± 90.56K | 111.18M ± 111.18K | 🚀 -1.82% |
| 11 | 114.20M ± 102.78K | 112.16M ± 201.89K | 🚀 -1.81% |
| 12 | 114.55M ± 103.10K | 111.82M ± 89.45K | 🚀 -2.44% |
| 13 | 108.87M ± 87.09K | 106.27M ± 138.15K | 🚀 -2.44% |
| 14 | 99.55M ± 129.41K | 95.13M ± 95.13K | 🚀 -4.64% |
| 15 | 92.35M ± 157.00K | 87.72M ± 96.49K | 🚀 -5.28% |
| 16 | 90.01M ± 180.02K | 84.53M ± 84.53K | 🚀 -6.48% |
Compression
We've been chipping away at compression too (shoutout to Brian Pane, who contributed numerous PRs in this area), but see more mixed results.

On x86_64 linux, we are faster for some of the compression levels that matter most, about 6% at the default level of 6, and over 10% at the "best compression" level 9. But we're still slightly slower for most of the other levels when comparing to zlib-ng.
| compression level | ng | rs | Δ |
|---|---|---|---|
| 0 | 15.07M ± 272.75K | 14.83M ± 260.97K | 🚀 -1.63% |
| 1 | 250.09M ± 300.11K | 258.71M ± 388.06K | 💩 +3.33% |
| 2 | 436.59M ± 698.54K | 465.33M ± 418.80K | 💩 +6.18% |
| 3 | 523.10M ± 156.93K | 542.28M ± 325.37K | 💩 +3.54% |
| 4 | 623.40M ± 436.38K | 648.43M ± 324.22K | 💩 +3.86% |
| 5 | 773.30M ± 463.98K | 711.81M ± 427.09K | 🚀 -8.64% |
| 6 | 939.52M ± 469.76K | 884.79M ± 442.39K | 🚀 -6.19% |
| 7 | 1.23G ± 1.48M | 1.24G ± 617.75K | 💩 +0.38% |
| 8 | 1.59G ± 159.22K | 1.60G ± 1.92M | 💩 +0.48% |
| 9 | 1.94G ± 970.95K | 1.71G ± 512.66K | 🚀 -13.64% |
For most users, decompression is the most relevant operation, and even for compression we're a lot faster than stock zlib. Nevertheless, we'll continue to try and improve compression performance.
Conclusion
zlib-rs can be used both in C projects and as a rust crate in rust projects. For rust projects, we recommend using the 1.1.0 release of the flate2 crate with the zlib-rs feature flag. For use in C projects, zlib-rs can be built as a C dynamic library (see instructions) and used in any project that uses zlib today.
Our implementation is mostly done, and clearly performs extremely well. However, we're missing some less commonly used API functions related to gzip files that would make us a complete drop-in replacement in all cases.
To complete the work and improve performance and e.g. packaging, we're seeking funding for the amount of €95.000. See the workplan for details.
Please contact us if you are interested in financially supporting zlib-rs.