Apr 14th, 2025
Lev Kokotov
PgDog is a network proxy and it can see every byte sent between Postgres and the clients. It understands SQL and can infer where queries should go, without requiring changes to application code.
In this article, we discuss how we handle the Postgres wire protocol and manipulate it to serve queries to multiple databases at the same time.
Protocol basics
Postgres has two ways to send queries over the network:
- Simple protocol
- Extended protocol
The simple protocol is called like that on purpose: it’s very simple. It has just one message, called Query which contains everything the server needs to execute it:
'Q' | \x00\x00\x00& | SELECT * FROM users WHERE id = 25\0
Postgres messages have a standard format. Each message starts with a single ASCII letter (1 byte), identifying the message type. It’s followed by a 32-bit signed integer, indicating the length of the payload, in bytes, with 4 bytes added for itself. The payload is unique for each message.
To route a query, PgDog needs to understand two things:
- Does the query read or write data?
- Does it contain a sharding key, and if so, what is it’s value?
To make this work, we need some help. To answer the first question, we could, theoretically, just look at the first word, and if it’s a “SELECT”, assume read intent. While this would work in most cases, we’ll miss some obvious ones, like CTEs.
The tricky part is finding the sharding key. For this, we need to actually interpret the query using a tool that understands SQL syntax. That’s called a parser, and luckily the Rust ecosystem already has a great library, called pg_query. The parser produces an Abstract Syntax Tree, a data structure we can read to find what we need:
let ast = pg_query::parse("SELECT * FROM users WHERE id = 25");
pg_query is special. It doesn’t actually implement parsing SQL. It works by extracting C source code directly from Postgres and wraps it with a nice Rust interface. This allows PgDog to understand all queries that Postgres can.
PgDog is all about sharding Postgres. Once we locate the sharding key in a query, we have to figure out what to do with it. Let’s do a quick detour into Postgres partitions.
The sharding function
Picking the right sharding function is critical. It’s not something you can easily change later. One thing I learned from doing this at Instacart: pick a sharding function which is available in multiple places. Let me explain.
In the real world, whatever you build, won’t be the only way to ingest or read data to/from your system. Either you don’t want to touch production (yet) or you just need to move some things around ad-hoc, you want engineers to be able to pre-process data in advance and have multiple ways to talk to your system.
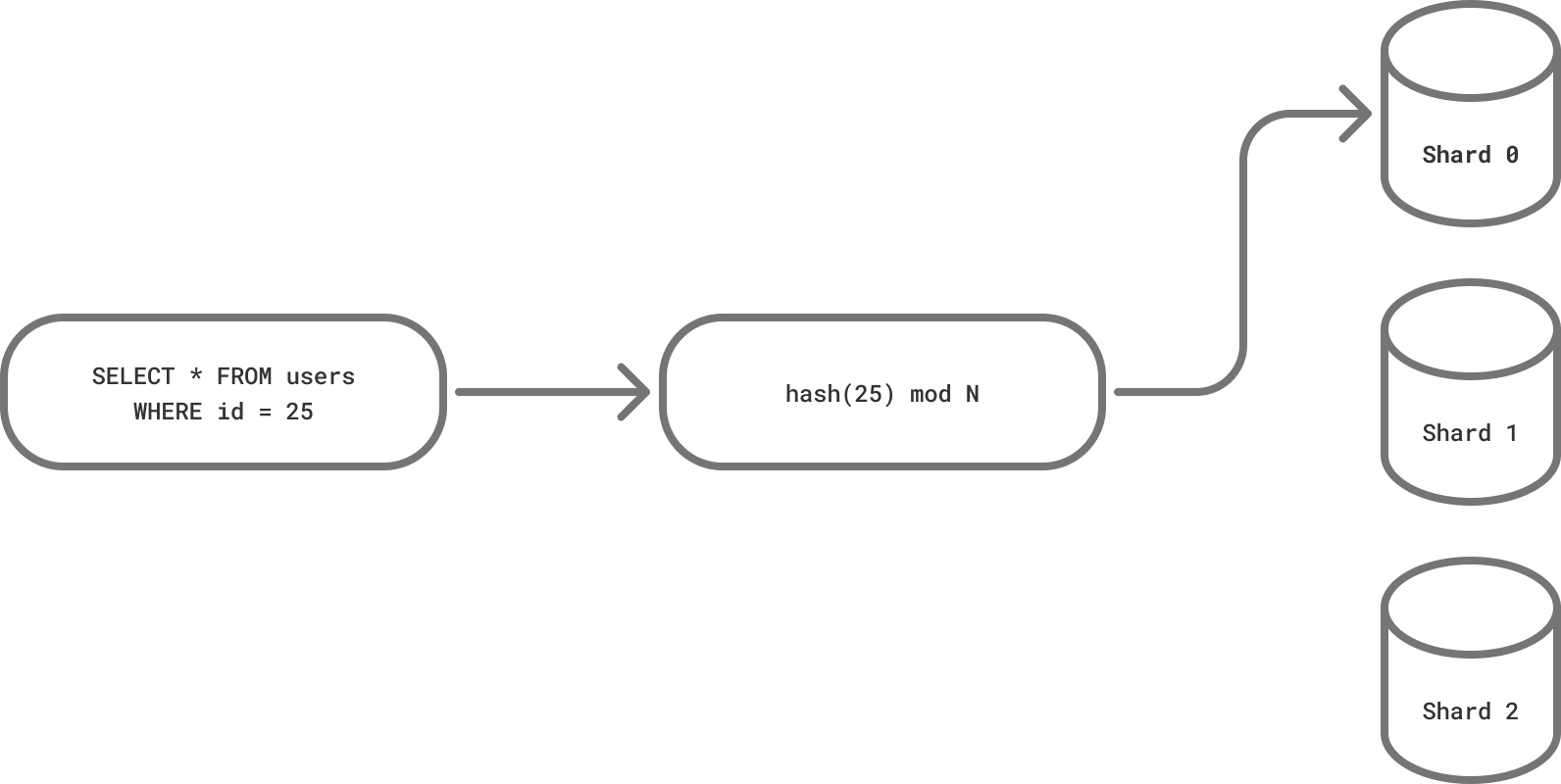
For this reason, PgDog doesn’t implement a custom sharding function. It’s using the hashing function used in Postgres declarative partitions:
CREATE TABLE users (id BIGINT, email VARCHAR)
PARTITION BY HASH(id);
If you know the number of shards, you can create the same number of data partitions and just COPY data into the table. If you’re using FOREIGN tables with postgres_fdw, you can interact with your sharded database directly.
To make this work in PgDog, we took a page from the pg_query playbook. We could have implemented the function ourselves, but it’s much better to just take the code from Postgres and wrap it with a Rust interface.
Rust makes this pretty easy. Using the cc (C/C++ compiler) library and by copy/pasting some code, we have a working FFI interface to hashfn.c straight out of the Postgres source code tree. All we need is the right data to pass in, and apply the modulo operation to get the shard number.
Our example has only one filter: id = 25. This is the simplest case, but it’s also the most common one. Getting this value from SQL, using pg_query, is straightforward. Once we have it, we can pass it to the sharding function and we have a shard number.

UPDATE and DELETE queries work the same way. They all have (an optional) WHERE-clause, and if it has a filter with our sharding key, we can handle it. If it doesn’t, the query is sent to all shards (more on that below).
More complex examples, like IN (1, 2, 3) or id != 25 can be handled as well. For the former, we can hash all values and route the query to the matching shards. For the latter, we can do the opposite. Some cases of course won’t work, e.g., WHERE id < 25. That’s too many values to hash and this query will hit all shards anyway.
INSERT statements are a bit more interesting and come in two variants:
The first one specifies the column order, so we can just extract the sharding key directly. The second doesn’t, so we have to fetch the schema from Postgres and infer the column order. This is slightly more involved, but still a solvable problem. Not something we’re handling yet, but it’s on the roadmap.
ORMs like Rails and Django tend to be explicit and provide fully-qualified columns and table names for all queries. This makes our job easier, but we can’t always rely on everyone using an ORM and we certainly don’t want to impose arbitrary limitations on our users.
Simple protocol is simple, but things get more interesting if the client uses prepared statements and the extended protocol.
Extended protocol
The extended protocol has several messages. For our purposes, we are interested in just two:
Parsewhich has the query and parameter placeholdersBindwhich contains the parameter values
Separating the two allows Postgres to parse the query once and execute it multiple times with different parameters. This is great for query performance and to avoid SQL injection attacks, but it requires us to do a couple extra steps to get what we need:

If prepared statements are used, clients typically send one Parse message per query. PgDog parses it and stores the AST in its memory cache. The statements are disambiguated at the global level, so even if multiple clients send the same one, they are evaluated only once.
This optimization is critical to make this fast in production. Parsing SQL isn’t free and we only do it when we have to. The message itself is saved in a memory buffer, while PgDog waits for the actual parameter values to arrive.
Bind message(s) follow for each execution of the statement. If the statement is anonymous (unnamed), we only get one Bind message. In either case, we know where the sharding key is located, based on the numbered parameters in the query.
With the sharding key hashed, we can forward both messages to a Postgres server connection and begin executing the query.
Both simple and extended protocols require PgDog to build an internal state of the connection and keep track of messages that flow through. As long as we keep the protocol in sync, we can manipulate what Postgres receives and what messages are sent back to the client. This becomes relevant when we start talking to multiple servers at once.
Cross-shard queries
Postgres query response contains multiple messages. They are, in order of appearance:
RowDescription, which contains column names and their data typesDataRowhas the actual values, with one message for each row in the result setCommandCompleteindicates the query finished running and how many rows were affectedReadyForQueryindicates the server is ready for the next query

Since PgDog is an independent proxy, Postgres servers have no idea they are executing a multi-shard query. Each server connection will return all of these messages in that order. However, except the DataRow message, the client expects only one message of each kind.
Each message in this pipeline is handled differently. For RowDescription, only the last one is returned. All shards are expected to have the same schema, so these messages should be identical between shards. If they are not, the data types must be compatible, e.g., VARCHAR and TEXT.
There are a few more nuances here. For example, if databases have custom data types created by extensions, like pgvector or PostGIS, their OIDs won’t match across different Postgres databases, and we need to make sure clients are only aware of one set. If text encoding is used (it is, by default), mixing BIGINT and INTEGER can work, although I wouldn’t recommend it. While languages like Ruby and Python don’t distinguish between the two, languages like Rust and Java definitely do.
DataRow messages are handled in two possible ways. If the query has an ORDER BY clause, the messages are buffered. Once all of them are received, they are sorted accordingly and returned in the right order to the client. If the rows aren’t ordered, PgDog sends them to the client immediately, in whatever order it receives them from the servers.

This is where the understanding of SQL starts to take shape. Extracting column values is great, but we need to do more to make sure the query is executed correctly. PgDog isn’t a full coordinator yet, but more features are added every week.
CommandComplete message is rewritten to reflect the correct row count. We do this by parsing its contents and summing the number of rows across all messages we received from all shards. ReadyForQuery is forwarded as-is (only the last message) and the cross-shard query is complete.
Protocol manipulation works on both sides of the conversation. PgDog doesn’t stop at manipulating server messages. It goes further and can modify client messages to create a powerful cross-shard data ingestion pipeline.
Distributed COPY
The fastest way to write data into Postgres is to use COPY. It’s a special command that can read CSV, text or binary data and write it directly into a table. It can be used to bulk ingest records and to move data between DBs.
COPY users (id, email) FROM STDIN CSV HEADER;
id,email
65,[email protected]
25,[email protected]
Postgres clients send this command using two messages:
Queryto send the COPY command itself- A series of
CopyDatamessages that contain the actual rows
In a sharded database, this command requires special handling. For each row, PgDog extracts the sharding key, hashes it, and routes it to the right server:

Clients typically send data in chunks, irrespective of encoding boundaries. For example, each CopyData message created by psql is 4096 bytes long and can break CSV records. To make this work, PgDog handles partial CSV records and streaming binary data by buffering one complete row at a time. CopyData messages coming out of PgDog always contain one single and complete row.
Performance
Distributed COPY, in theory, can linearly scale ingestion speeds for sharded Postgres. With each new shard, the speed of ingestion should increase by 1/N where N is the number of shards. Since PgDog is using Tokio and multiple threads, it’s possible to run it on a machine with multiple CPUs and parallelize the hashing and manipulation of data rows. A single ingestion pipeline can push gigabytes of data per second into Postgres, while maintaining schema and data integrity.
Next steps
PgDog is just getting started. While it can manipulate the frontend/backend wire protocol used by clients and Postgres servers, we are going further and applying the same technique to manipulate logical replication streams.
Since PgDog does all this at the network layer, it can run anywhere including managed clouds like AWS RDS, and works with Postgres clones like Aurora, AlloyDB and Cockroach.
If this is interesting, get in touch! We are looking for early adopters and design partners. We always appreciate a star on GitHub.