As I was whining yesterday, it’s perplexingly difficult to find a (semi-)programmatic way of determining whether an author has written a new book. Or even manually in some cases. The best advice is, like, “Follow them on Goodreads” or something?
But I wondered whether I could finally find something useful for an LLM to do? Sure, LLMs are plagiarism machines that use all of the world’s energy, but what can it do for me? So I signed up for the Perplexity AI, and an hour later:
Yes, I’m a prompt engineer now.
I’ve gotta give it to Perplexity — signing up for the API, adding some money and getting it to spew some data at me was totally painless. I created a little library called perplexity.el (and put it on Microsoft Github), but it’s totally trivial: It just does a url-retrieve request with some headers set, and you get JSON back.
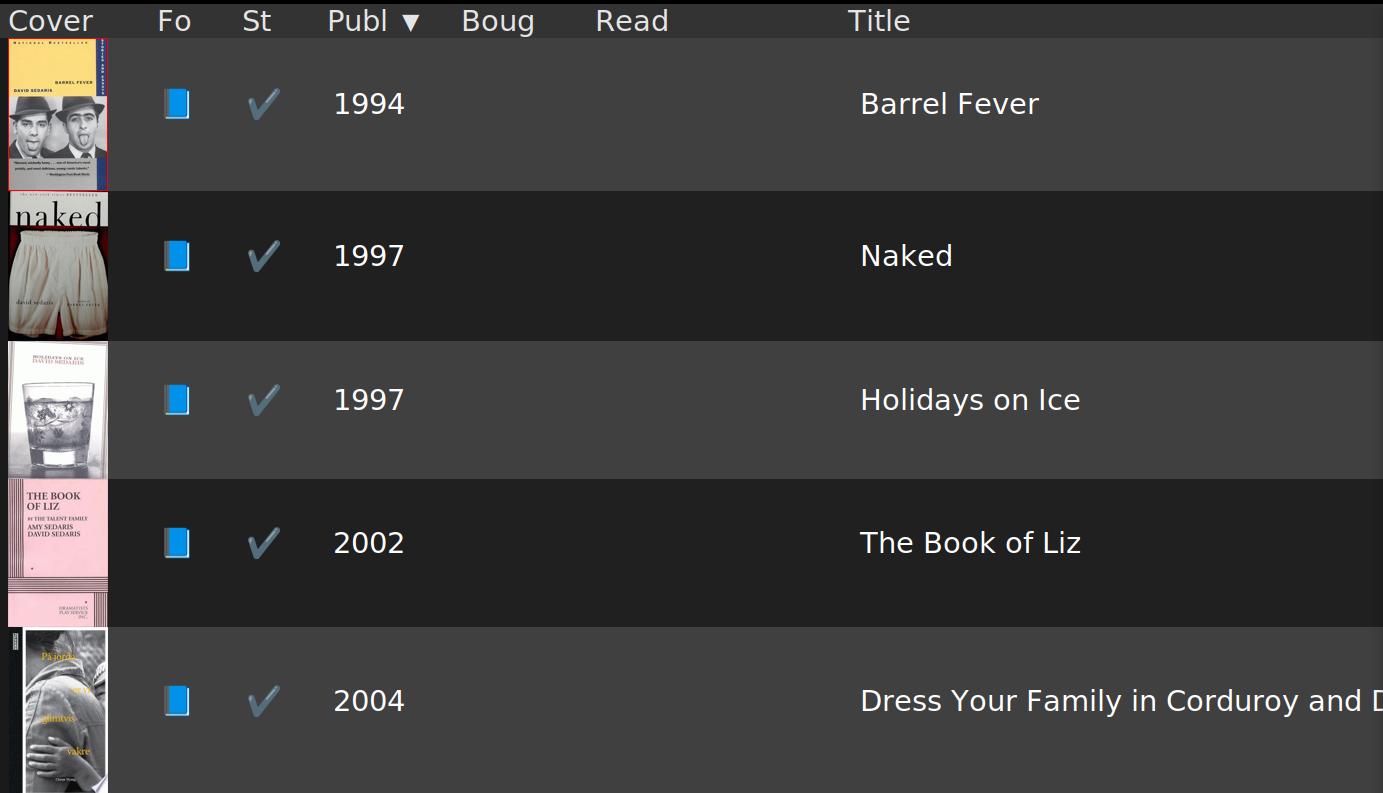
So in the screenshot above, it’s listing all the books by David Sedaris it knows about, and also helpfully what kind of book it is.

That’s OK, and it’s of course trivial to just use that to list books that are newer than the last book I have from him. So I guess I could use this to automatically get all new books from the authors I’m interested in.
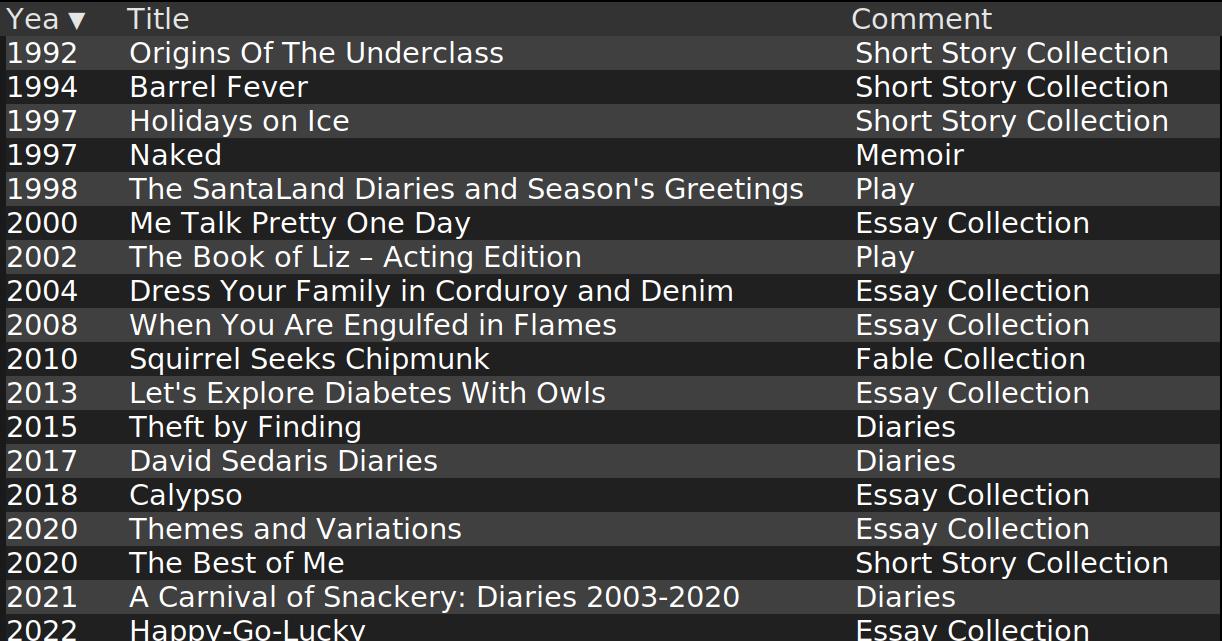
I also did a variation where I asked “list all the books by this author, but exclude books on this list:”, and then list all the books I already have by this author.
And as you can see, that, er, kinda changed what it’s outputting? Now it’s including a lots of plays that it didn’t before?
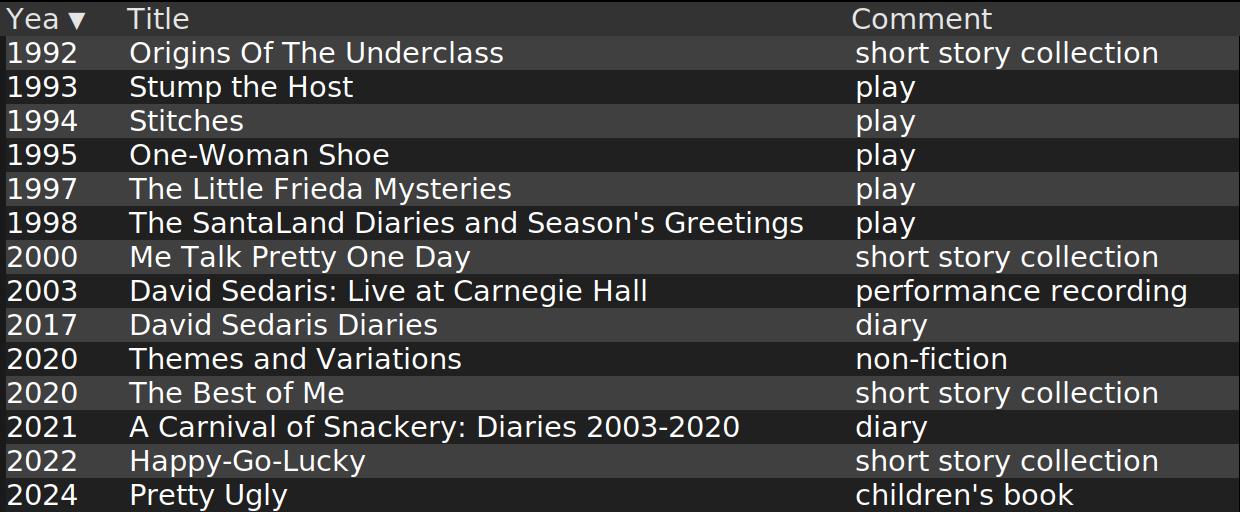
Typically enough, LLMs give different answers every time I ask, so this isn’t, you know, data to be relied on in any way. Sure, it’d be better if it was actual data instead of hallucinations and LLM navel lint, but it’s better than nothing.
The response times from Perplexity are all over the place — sometimes it responds within a couple seconds, and sometimes it takes a minute, but whatchagonnado.
Let’s test another author:
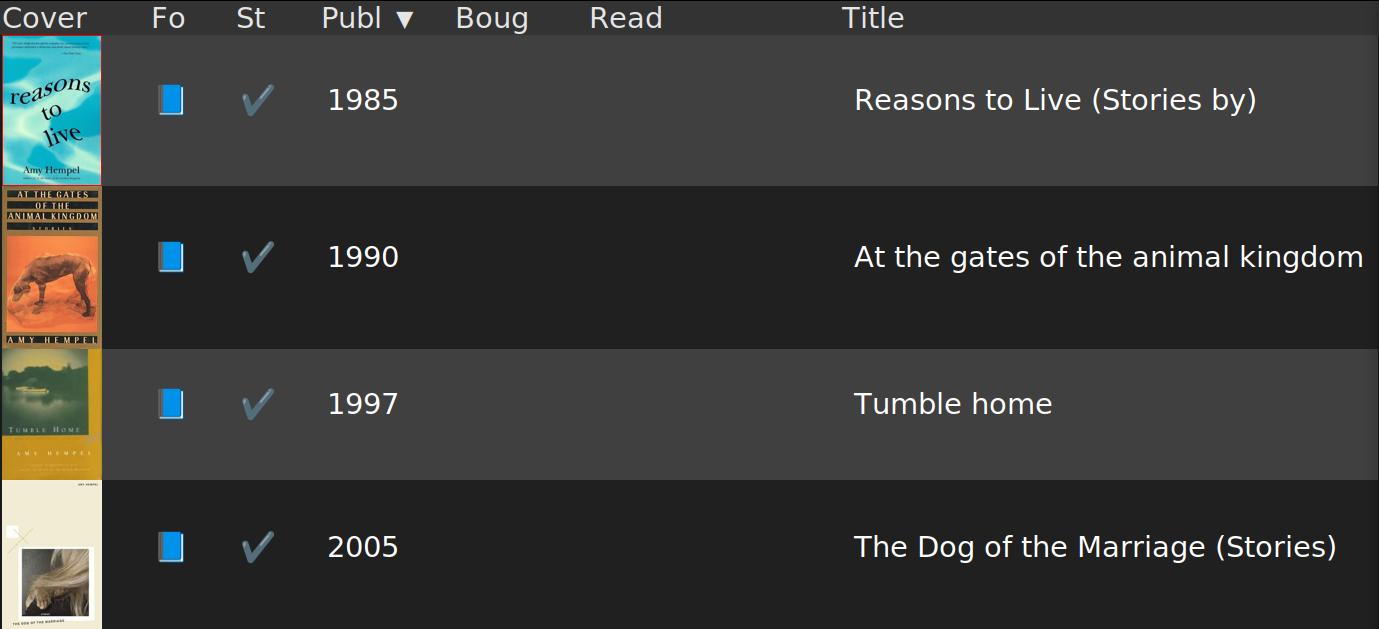
Amy Hempel. She’s awesome. I hit the m command (to list “missing” books), and:

All those three are books that exist! And that I don’t have.
I tried asking it again, and then it only listed two of these books — the non-repeatability of the results is annoying, but again, LLMs are toys, and if you get anything useful out of them, that’s nice, but your expectations can’t be low enough.
For giggles, let’s try this a “list missing books” on Megan Whalen a few times:
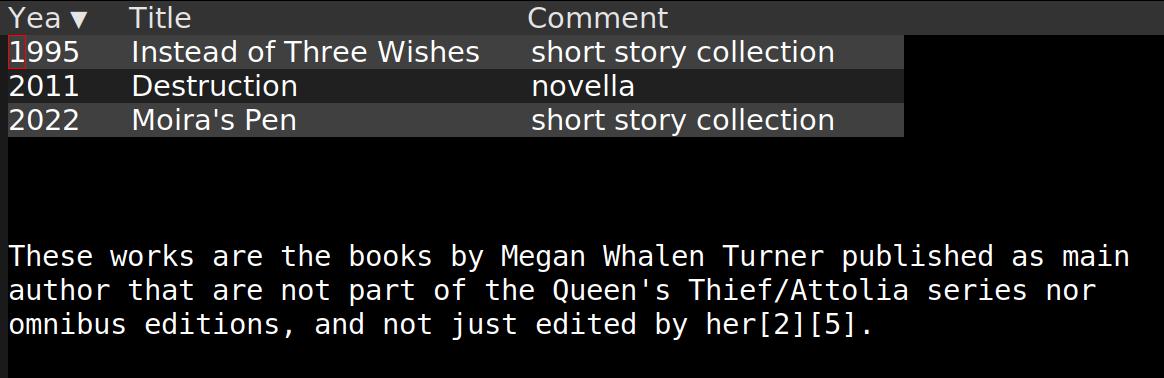
1st.

2nd.

3rd.
Oh well. I tried adjusting the temperature, but no go. I guess I could run the query several times and aggregate the results, but it’s already pretty slow…
After using this for a handful of authors, I’m now deep in debt. OK, perhaps not from the API usage, but because I’ve bought, like, fifteen books while just testing things out here…
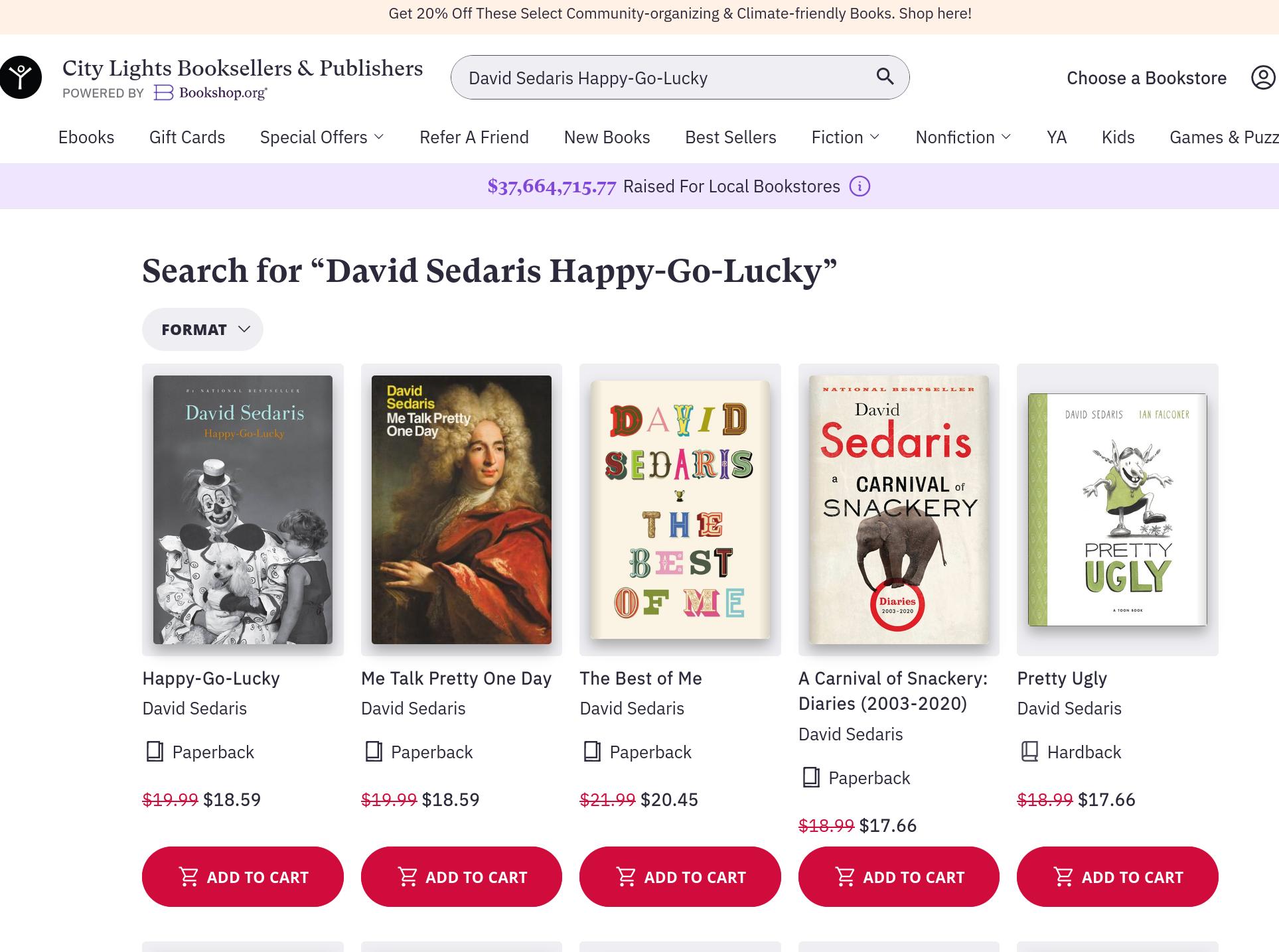
I’ve added convenient commands to the search buffer to go to bookshop.org so that I can shop, as well as Goodreads to check whether the books actually exist. (They mostly do, but there are of course some hallucinations.)

And now I can also do that thing I wanted where there are certain authors that I track, and then query Perplexity for books they’ve released the last few years. Let’s see, I’ve marked a few authors, and:

Let’s repeat that:
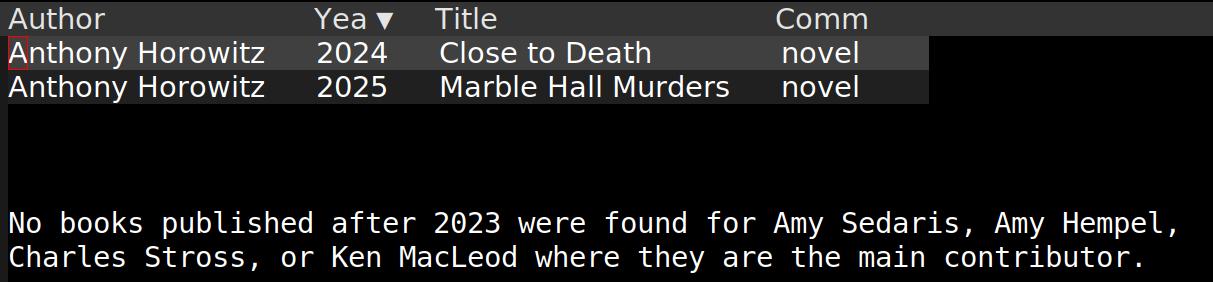
And again:
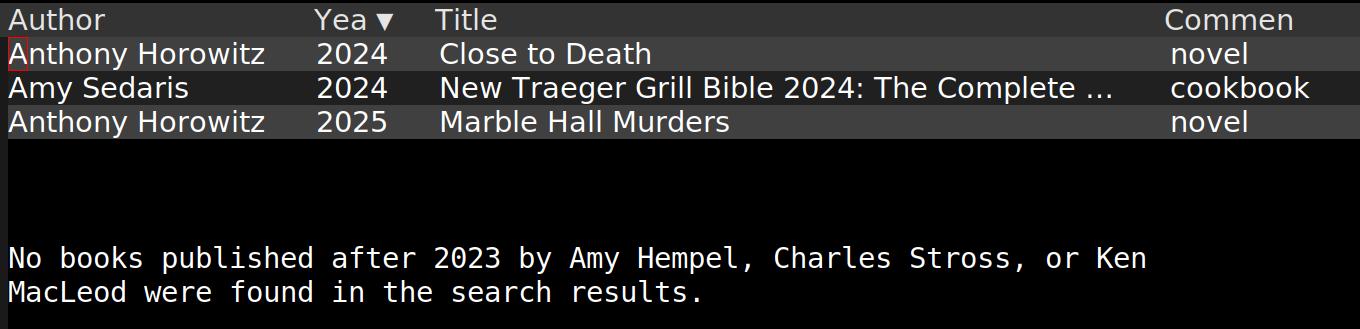
*sigh*
Heh, if I remove Anthony Horowitz, I get:

Sure, sure… If I have just Stross and MacLeod, I get:

OK OK OK.
Is there a way to make Perplexity try, like, harder? (This is with Sonar Pro.) The prompts are in the package.
[Edit an hour later: OK, I guess I get it… Perplexity is based on web searches, and it just doesn’t like to do a lot of searches? So I’m going to have to loop through each tracked author and then aggregate the results.]
But… it does actually kinda look like even I managed to find something actually useful to use an LLM for, even if it’s literally janky? Actually?
Whodathunk.