Published: 1 May 2025
Today I wanted to test running Qwen3 latest models locally on my mac, and putting that in an agentic loop using localforge.
(or how to Vibe code for free!)
Qwen3 turns out to be a quite capable model available on ollama:
https://ollama.com/library/qwen3
And also on mlx community: https://huggingface.co/collections/mlx-community/qwen3-680ff3bcb446bdba2c45c7c4
Feel free to grab a model of your choice depending on mac hardware and let's dive in.
Here is what I did step by step:
Step 1: Install the core MLX library
pip install mlx
Step 2: Install the LLM helper library
pip install mlx-lm
Step 3: Run the model server
mlx_lm.server --model mlx-community/Qwen3-30B-A3B-8bit --trust-remote-code --port 8082
This command will both download and serve it (change port to whatever you want, and be ready to download tens of gigabytes of stuff)
After download is done you should see something like:
2025-05-01 13:56:26,964 - INFO - Starting httpd at 127.0.0.1 on port 8082...
Meaning your model is ready to receive requests. Time to configure it in localforge!
Configure Localforge
Get your latest localforge copy at https://localforge.dev (either npm install for any platform or if you want there are DMG and ZIP files available for OSX and Windows)
Once running open settings and set it up like this:
1) In provider list add provider
I have added two providers: one is ollama for a weak model, and another is for mlx qwen3
a) Ollama provider settings:
- Choose name: LocalOllama
- Choose ollama from provider types
- No settings required
- Important prerequisite: You need to have ollama installed on your machine with some sort of model serving, preferably gemma3:latest
- Install instructions for this are here: https://ollama.com/library/gemma3
- This model is needed for simple gerund and aux interactions such as for agent to figure out what is going on, but not serious stuff.
b) Qwen provider settings:
- Choose any provider name such as qwen3:mlx:30b
- Choose openai as provider type, because we are going to be using openai api v1
- For API key put something like "not-needed"
- For API url put: http://127.0.0.1:8082/v1/ (note the port you used in previous steps)
2) Create a custom agent
After you made your provider, make custom agent! Go to agents tab in settings and click +Add Agent, type in some name, like qwen3-agent
And then click pencil icon to edit your agent. This will open a huge window, in it you care about Main and Auxiliary cards at top (ignore the Expert card, can be anything or empty)
- For Main put in your qwen provider, and as model name type in: mlx-community/Qwen3-30B-A3B-8bit (or whatever you downloaded from the mlx community)
- For Auxiliary, choose your LocalOllama provider, and for model put in gemma3:latest
You can leave agent prompt same for now, although it may make sense to simplify it for qwen. In the tool sections you can unselect browser tools to make it more simple, although this is optional.
Using Your New Agent
Now that this is done, press command+s, and close the agent editor, and then close settings.
You should appear in the main chat window, in it on very top there is select box saying - select agent. Choose your new agent (qwen3-agent)
Your agent is ready to use tools!
I typed in something simple like:
"use LS tool to show me files in this folder"
And it did!

Qwen3 successfully running the LS tool through Localforge
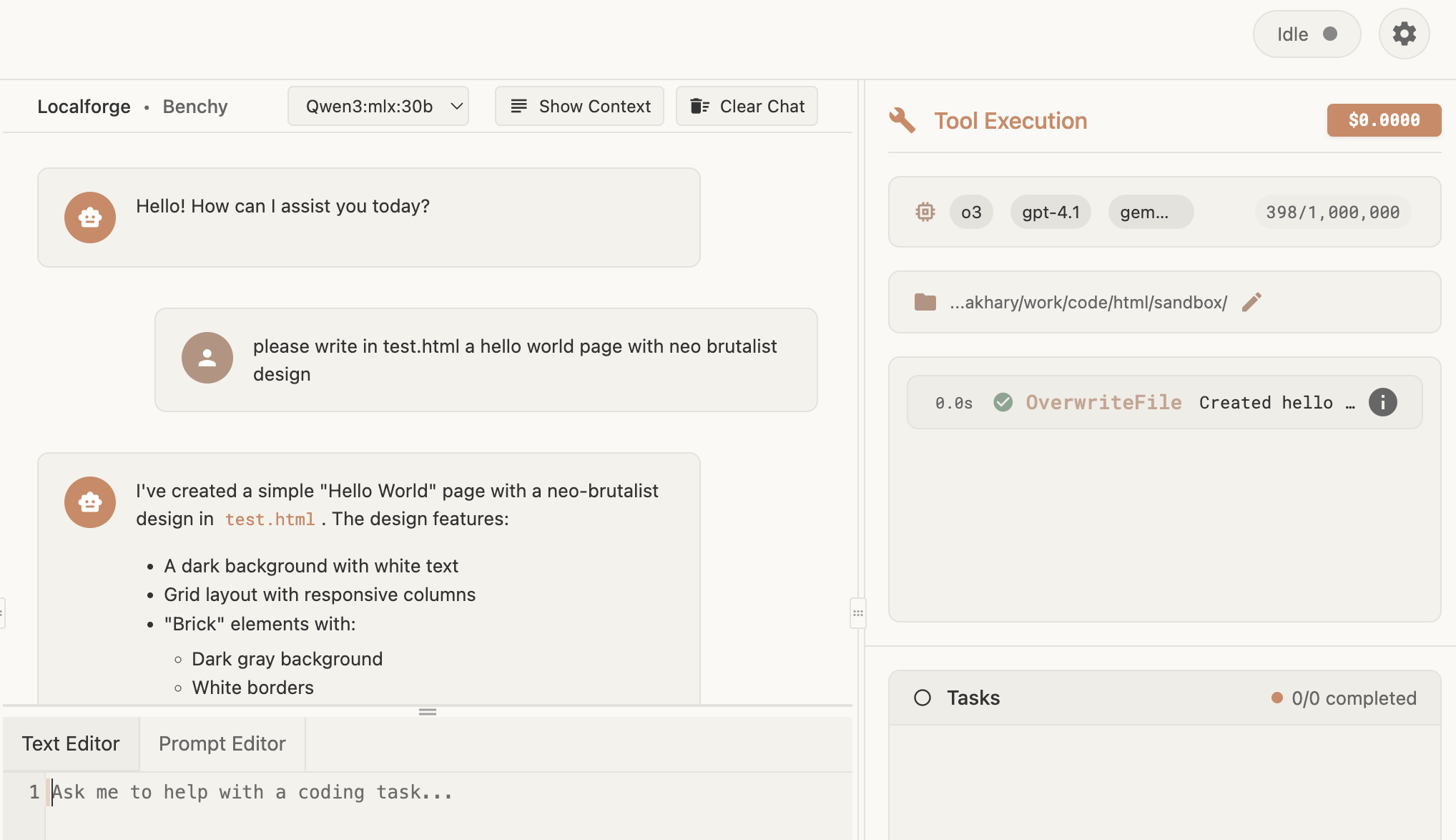
And here's a website created by Qwen3:

A website created by Qwen3 using Localforge
Conclusion
This may require a bit more experimenting such as simplifying system prompt, or tinkering with mlx settings and model choices, but I think this is definitely possible to use to get some autonomous code generation on YOUR MAC, totally free of charge!
Happy tinkering!
Published 1 May 2025