(评论)
(comments)
原始链接: https://news.ycombinator.com/item?id=38505211

在了解注意力机制及其从传统循环神经网络(RNN)到近年来常用的 Transformer 架构的进一步资源方面,以下是一些建议:
1.“上下文嵌入调查”:https://arxiv.org/abs/2003.07278
本文对在向量空间中表示单词和短语以捕获含义和上下文的技术进行了广泛的调查。 它涵盖了一系列方法,包括词袋、doc2Vec、Skip-gram 和全局向量。 尽管最初引入注意力机制并不涉及嵌入,但理解嵌入对于理解 Transformer 模型的演变至关重要。
2. Yoon Kim 等人的“手写数字识别循环神经网络研究”。 本文对 Transformer 与递归神经网络进行了比较,特别是对于手写数字识别任务。 与经典 RNN 相比,Transformer 方法显着提高了识别的准确性。
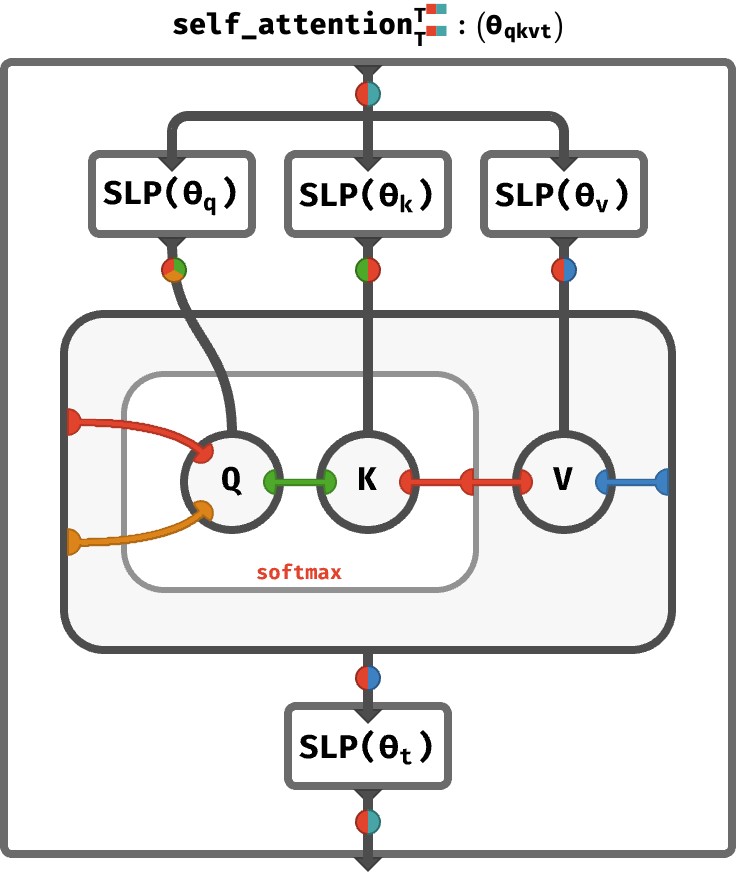
3.“自注意力生成比编码器-解码器架构更好的表示”,作者:Donghui Zhang 等人。 提供了比较编码器与具有自注意力的解码器的见解。
关于简化神经网络的类似可视化工具,除了前面提到的 Okdalto 之外:
1. Mark Guzdar 的“Netron:可视化和分析神经网络拓扑”可在此 GitHub 存储库中找到:https://github.com/markguzdar/netron
Netron 使用户能够分析经过训练的神经网络的拓扑结构,并生成这些结构内单个神经元的高分辨率图像。
2.“TensorFlow Playground”直接在浏览器中提供实时实验功能。 用户可以通过使用简单的示例来探索 TensorFlow.js。
3.“PyTorch Visualizer”支持与 Jupyter Notebook 的互操作性,用于调试目的或在线演示机会。 它对 iFrames 的使用与 SPADES 兼容。
然而,关于运行上述工具时可能出现的错误,这可能表明特定浏览器或版本不支持WebGL API。 正如一些专家建议的那样,检查 WebGL2 扩展是否处于活动状态可以解决该问题,因为某些来源
{kind=link}
For those reading it and going through each step, if by chance you get stuck on why 48 elements are in the first array, please refer to the model.py on minGPT [1]
It's an architectural decision that it will be great to mention in the article since people without too much context might lose it
[1] https://github.com/karpathy/minGPT/blob/master/mingpt/model....
reply