June 23, 2025
TL;DR Spegel is a proof-of-concept terminal web browser that feeds HTML through an LLM and renders the result as markdown directly in your terminal.
Two weekends ago, after my family had gone to sleep, I found myself unsupervised with a laptop and an itch to build something interesting. A couple of hours later, I had a minimal web browser running in my terminal (no JavaScript, GET requests only) that transformed web content based on my custom prompts.
Then, a few days later, Google released Gemini 2.5 Pro Lite, significantly faster inference speed, suddenly my little weekend hack became a tad more practical.
Personalisation
Adapting content to suit individual needs isn’t a new idea, think about translating books or summarising lengthy articles. However, this used to be slow and expensive. LLMs have changed this dramatically, making these transformations quick and easy.
Spegel ("mirror" in Swedish) lets you explore web content through personalized views using your own prompts. A single page can have multiple views, maybe one simplifying everything down to ELI5 or another highlighting key actions. It's entirely up to you and your prompting skills.
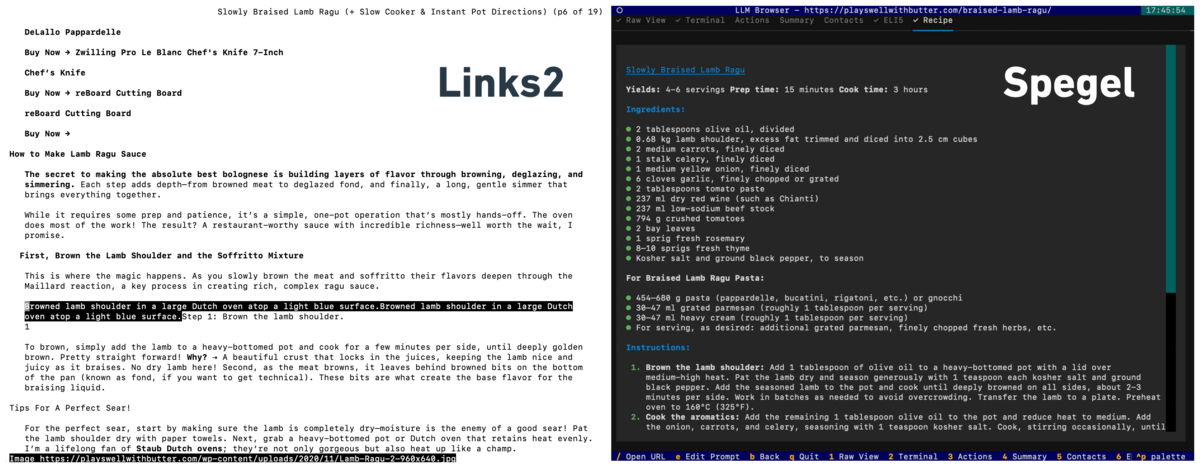
Sometimes you don't want to read through someone's life story just to get to a recipe.
 That said, this is a great recipe
That said, this is a great recipe
Example configuration
[[views]]
id = "recipe"
name = "Recipe"
hotkey = "7"
order = "7"
enabled = true
auto_load = false
description = "Get to the point in recipes"
icon = "🍳"
prompt = """Parse a recipe and extract only the essential parts.
Format the output like this:
# Ingredients
* 1 tbsp salt
* 400 g beef
# Steps
1. Preheat the oven to 200°C (Gas Mark 6).
2. Wash and chop the carrots.
-----
**Instructions:**
* Use **metric units** (not imperial).
* inches -> cm
* pounds -> kg
* cups -> dl
* Keep the output **clean and minimal** no extra commentary, tips, or nutrition facts.
* Include the servings."""
How it works
The pipeline is straightforward.

Spegel fetches HTML content, processes it through an LLM using prompts stored in a config file (~/.spegel.toml), and outputs markdown rendered via Textual. Prompts and views can be adjusted live during a browsing session.
This was my first experience using Textual for a TUI, and it's been delightful, possibly too delightful, as I found myself adding a few unnecessary interface elements just because it was easy.
One gotcha was ensuring only completed lines (ending in newline characters) were streamed; otherwise, the markdown renderer would parse incomplete markdown and fail to recover formatting
buffer: str = ""
async for chunk in llm_client.stream(full_prompt, ""):
if not chunk:
continue
buffer += chunk
while "\n" in buffer:
line, buffer = buffer.split("\n", 1)
yield line + "\n"
if buffer:
yield buffer
Other terminal browsers
There are a lot of great terminal browsers out there, Lynx and Links2 are close to my heart. There are also modern attempts like Browsh that can even render graphs using half-block Unicode characters (▄█).

Spegel isn’t meant to replace these, it’s more of an exploration or proof-of-concept. It currently doesn't support POST requests (though I have some ideas on handling <form> elements by creating on-the-fly UIs).
But most modern websites aren’t designed with terminal browsing in mind. They rely on CSS and JS, making them cumbersome in small terminal windows, full of clutter and noise. Spegel tries to clear away distractions, providing content tailored more closely to your needs.
Try it
Spegel is still in the early stages, so expect some rough edges, but it’s usable and kind of fun to play with.
Install it via pip:
Then just run it with a URL:
spegel simedw.com # or your favourite website
Don't forget to configure your own ~/.spegel.toml, (example)
Want to check out the source or contribute? It’s all on GitHub: