The Apple M2, introduced in 2022, and the Apple M4, launched in 2024, are both ARM-based system-on-chip (SoC) designs featuring unified memory architecture. That is, they use the same memory for both graphics (GPU) and main computations (CPU). The M2 processor relies on LPDDR5 memory whereas the M4 relies on LPDDR5X which should provide slightly more bandwidth.
The exact bandwidth you get from an Apple system depends on your configuration. But I am interested in single-core random access performance. To measure this performance, I construct a large array of indexes. These indexes form a random loop: starting from any element, if you read its value, treat it as an index, move to this index and so forth, you will visit each and every element in the large array. This type of benchmark is often described as ‘pointer chasing’ since it simulates what happens when your software is filled with pointers to data structures which themselves are made of pointers, and so forth.
When loading any value from memory, there is a latency of many cycles. Thankfully, modern processors can sustain many such loads at the same time. How many depends on the processor but modern processors can sustain tens of memory requests at any given time. This phenomenon is part of what we call memory-level parallelism : the ability of the memory subsystem to sustain many tasks at once.
Thus we can split the pointer-chasing benchmark into channels. Instead of starting at just one place, you can start at two locations at once, one at the ‘beginning’ and the other at the midpoint. And so forth. I refer the number of such divisions as a ‘channel’. So it is one channel, two channels and so forth. Obviously, the more channels you have, the faster you can go. From how fast you can go, you can estimate the effective bandwidth by assuming that each hit in the array is equivalent to loading a cache line (128 bytes).
I run my benchmarks on two processors (Apple M2 and Apple M4). I have to limit the number of channels since beyond a certain point, there is too much noise. A maximum of 28 channels works well.
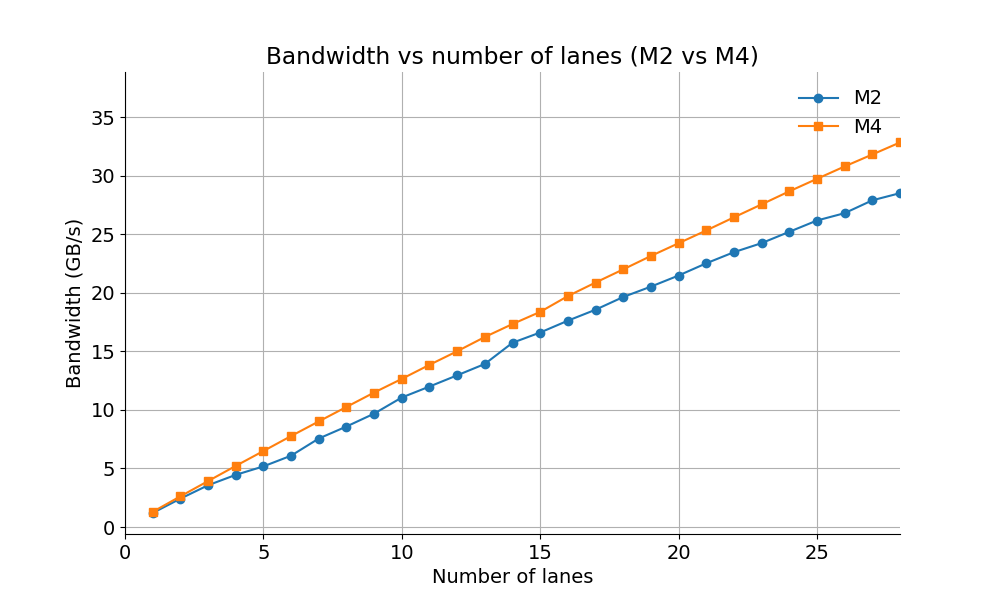
Maybe unsurprisingly, I find that the difference between the M4 and the M2 is not enormous (about 15%). Both processors can visibly sustain 28 channels.