Backpressure is one of those things that can make or break a distributed system, and is handled in an amazing way by a lot of tech around us.
I recently got the chance to interact with it while building my real time leaderboard, where I had to account for this to enable clients have the best possible experience.
So what is it, really?
There’s two competing definitions.
- A technique used to regulate the transmission of messages (or events, packets).
- The capability of producers of messages to overload consumers. (Reference to Baeldung’s blog)
Though both are correct, I prefer the second definition and will use that throughout this post.

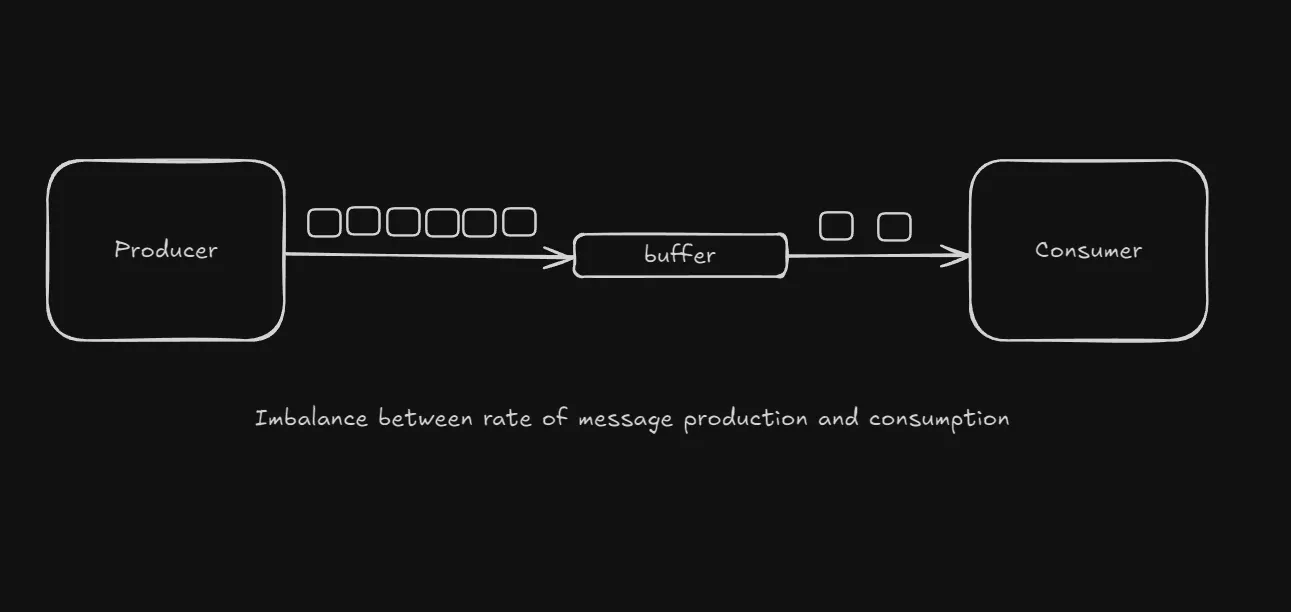
Backpressure happens when your system can’t keep up with the amount of work being thrown at it.
Why is this an issue?
Here’s a small list of issues that can occur if backpressure isn’t handled correctly.
- OOM errors (client killed due to huge memory usage on buffers)
- Dropped messages (buffer capacity reached - drops incoming automatically)
- Low throughput (resources are wasted trying to keep up)
- Network waste
- Latency increase
- Producers getting blocked (in case of Go channels)
When does backpressure occur?
Let’s first define the system in which backpressure will be encountered, then do a code prototype and discuss strategies for resolving it.
There’s three components to this system
- Producer creates and initiates send of the message to the consumer.
- Messaging system which receives messages from the producer and forwards them to the consumer. (This part may not be present separately, can also be the network buffers of the system.)
- Consumer receives messages from the messaging system and processes them.
Things work fine if the rate at which messages are created by the producer is less than or equal to the rate at which messages are processed by the consumer. If the creation rate exceeds the rate of consumption, we have a problem.
I like to think of this in terms of playing games like Tetris, at first the blocks arrive slowly and you’re able to process (move and rotate) them easily. As time goes on, the rate at which these blocks arrive speeds up and overwhelms you and at some point it’s game over.
How to fix it?
There’s a bunch of ways this can be handled, depending on the system constraints.
1. Slow down producer
Consumer sends a signal to the producer to slow down. This can be applied where the rate of messages can be controlled, and consumer should be given control of it.
In Go this can be implemented through the use of a channel to signal when the message rate should drop.

Slow down producers
TCP does something similar, which is discussed below.
Tradeoffs
- Complexity overhead for feedback integration. In Go this is quite simple, add an extra channel to send a slow down signal, keep sending messages till the rate of messages received is good enough to work with.
- It might not always be possible to slow down producers, as control of rate of messages produced might be out of our control.
2. Drop existing messages
If the messages existing in the queue are not as important as the ones that are being sent by the producer, the existing messages can be dropped. The exact strategy of dropping (drop oldest, drop all, priority based etc.) depends.

Drop existing messages
This is the approach I’ve used in my real time leaderboard, as the final state matters and not the intermediate states. If the producer is throttled instead, the leaderboard sent to consumers will be of older intervals for all the clients. Instead skipping on a few intermediates (which haven’t been received by client) and directly sending the final state to slow clients is a better solution.
Tradeoffs
- Loss of data that is already queued to be processed. This works if it’s a case where final data matters more than incoming (or priority based), but in systems where messages are critical, this cannot be applied.
3. Drop incoming messages
Probably the simplest method, to not accept any more messages from the producer until the space has freed up, without explicitly telling it to slow down. In producers this can be combined with retries and checks - if retries exceed a certain limit throttling can be done without any communication.

Drop incoming messages
Tradeoffs
- Similar to the previous fix, we might not always have the luxury of dropping incoming messages - data may be critical enough that we’re unable to drop any.
- Retries can be added to the producer - keep sending messages if ack not received instead of a fire and forget thing (at least once delivery, this is more of a nuance than anything).
4. Increase consumers
An example of this is an async task queue for processing documents (or scalable notification system, similar function).

Scale out workers (autoscaling essentially)
There will be a pool of workers which can be scaled up or down based on the amount of messages being received, an intermediate consumer may be used to just assign the messages (tasks) to the workers.
Tradeoffs
- This works when messages can be processed in parallel, but breaks down if some serial notion is required (otherwise you need other ways to enforce ordering, locks, things get complicated).
Note: Not all systems can increase consumers dynamically. For example, Nginx uses a predefined worker pool size, so it handles backpressure differently.
How I dealt with backpressure in the real-time leaderboard
In my real time leaderboard, I used channels and goroutines in a manner similar to the Actor Pattern. Each client connected to the server would have a goroutine associated with it, and a separate buffered channel would be created on which only that client would receive messages. The broadcaster goroutine would iterate through these channels and send messages to each buffered channel.
The key constraints for this system were:
- Final state mattered, not intermediate states, clients just needed the most recent leaderboard.
- Multiple clients with variable speeds, some could consume updates in real time while others lagged.
Even one client being blocked would mean that others do not get updates.
Because of this, I chose the drop existing messages strategy, skipping intermediate updates for slower clients and only delivering the latest state.
Warpstream reference
Warpstream is a diskless, Apache Kafka streaming platform which has a great blog on this topic, which I referred to for enhancing my understanding on it.
It has a more comprehensive view on backpressure, somewhat more aligned with keeping a steady, uniform stream of data incoming to the system rather than just dealing with a high influx rate.
Dealing with rejection (in distributed systems)
How TCP deals with backpressure
TCP uses flow control and congestion control, both of which use backpressure in some capacity.
In flow control, the receiver capacity is understood by the producer (sender) in order to slow down when the rate of messages is too high.
Flow control is implemented using the sliding window protocol in TCP. This has the receiver sending it’s available window size to the sender (piggybacked on the ack for packets received), which regulates it’s rate of sending based on the protocol given the window size it receives. More on that here.
TCP messages don’t go at a constant rate, they have slow starts, followed by a high rate of messages (increasing) till a threshold is reached (congestion avoidance) then a third phase called congestion detection. This is used in congestion control, which helps to limit flow of packets at each node of the network, as opposed to at the end receiver.
What other systems implement this
Backpressure is a recurring theme in distributed systems. It shows up quite prominently in
- Kafka
- gRPC streaming
- Sidekiq