or at least the open versions of it. I have this very stupid rule. A couple of years ago I decided to turn this blog into a podcast. At the time, I decided to make up a stupid rule: whatever model I use to clone my voice and generate article transcripts needs to be an open model.
Why? Because - as you might have figured by now - I like to make my life hard. The last version of the podcast generation engine was running on F5-TTS. It was fine. I still got some funny messages from people showing me the model completely hallucinating or squeaking here and there. But a year later - I was pretty sure there would be something incredibly better out there.
Now I’m not so sure.
The first step was to look for the best TTS models out there. Thankfully, Artificial Analysis now publishes a leaderboard with the “best” text-to-speech models. After filtering by my stupid rule of open models, we get the below ranking.
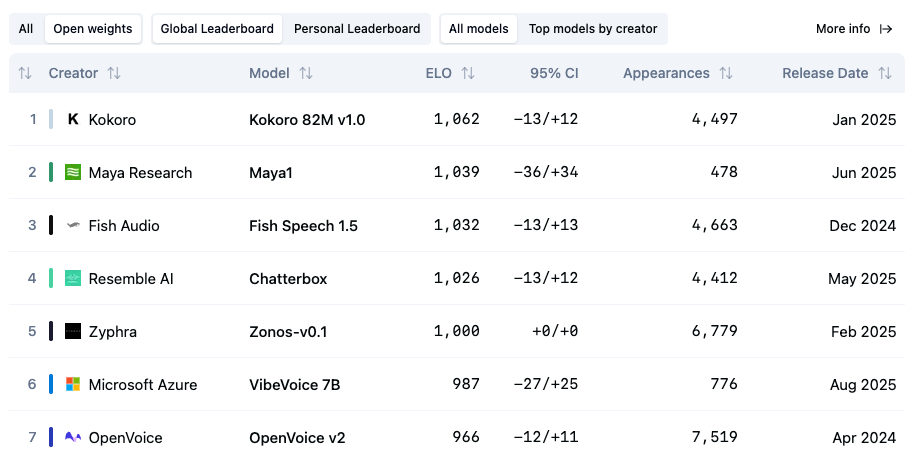
At the top of the leaderboard is Kokoro. Kokoro is an amazing model! Especially for a modest 82 Million (!) parameters and a mere 360 MB (!). However, like many models in this leaderboard - I can’t use it - since it doesn’t support voice cloning.
I started by looking at some of the stuff from Fish Audio. Their codebase seems to now support their new S1-mini model. When testing it, most of the emotion markers did not work - or were only available in their closed version. The breaks and long pauses either. Also, the chunking parameter is completely unused throughout the codebase - so not sure why it’s there. It’s a common business model nowadays: announce a state of the art open model just to attract attention to your real, and the incredible powerful gated model you have to pay for.
My second-best option on the list was Chatterbox. This wave of TTS models comes with major limitations. They're all restricted to short character counts - around 1,000–2,000 characters, sometimes even less. Ask them to generate anything longer, and the voice starts hallucinating or speeds up uncontrollably.
Chatterbox (latest version)
The transcript generation process is straightforward. First, text gets extracted from my RSS feed and pre-processed by an LLM to make it more "readable". The LLM generates a transcript, a short summary, and a list of links for the show notes. We then chunk the transcript and fire that off to a bunch of parallel Modal containers where we run the Chatterbox TTS model. Once we get everything back, we stitch the wav files together, and voilà! The episode is ready. The hosting is an S3 bucket. Really, that’s what you are paying your podcast host for - it’s a lucrative business!
I also made some improvements to the podcast generation side of things. First of all, the podcast is now also available on Spotify. Additionally, I fixed the show notes to now include nice clickable links in almost every podcast player. Looking at you Apple and your CDATA requirements!
Some thoughts on the Chatterbox model. It’s definitely better than F5-TTS. But there are however, some common annoyances with almost every open-source voice cloning model. The first is the limited duration of the generated speech. Anything over 1000 characters starts hallucinating. The second is lack of control. Some models have emotion tags, others have <pause> indicators. But almost every single one of these has been massively unreliable. To the point where I am splitting my text in a sentence per line and shipping that off to the TTS model to make things a bit more reliable.
So yes, from one side, TTS has come a long way. But when compared to other proprietary systems, TTS still sucks.
Note: The rss to podcast pipeline is open source and available if you want to re-use it in this GitHub repo.