Cloudflare just had a large outage which brought down significant portions of the internet. They have written up a useful summary of the design errors that led to the outage. When something similar happened recently to aws, I wrote a detailed analysis of what went wrong with some pointers to what else might be going wrong in that process.
Today, I’m not going to model in such detail, but there are some questions raised by a system-theoretic model of the system which I did not find the answers to in accident summary Cloudflare published, and which I would like to know the answers to if I were to put Cloudflare between me and my users.
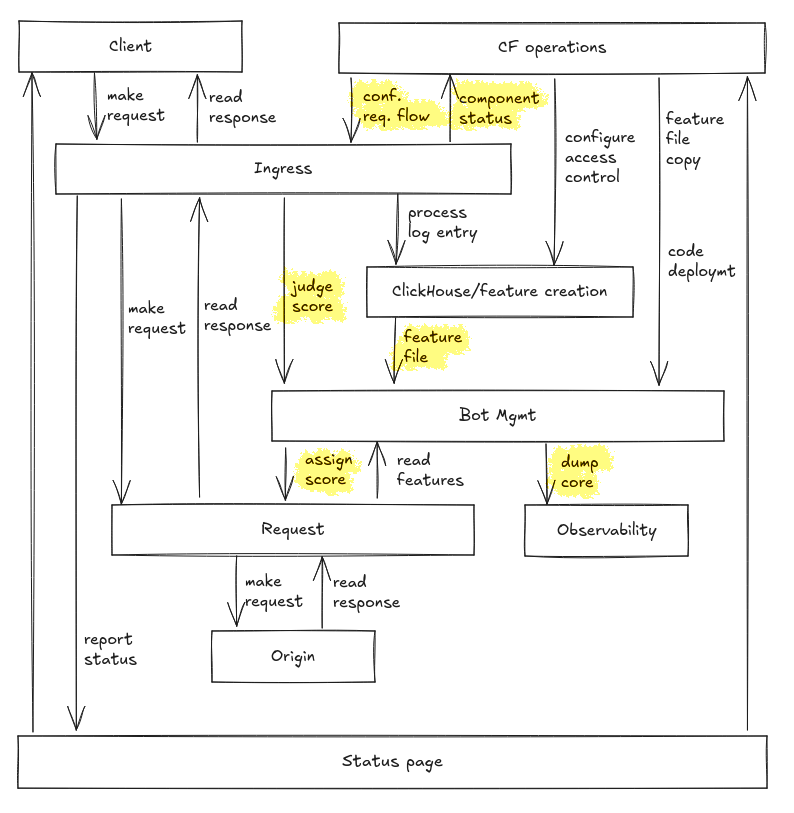
In summary, the blog post and the fixes suggested by Cloudflare mention a lot of control paths, but very few feedback paths. This is confusing to me, because it seems like the main problems in this accident were not due to lacking control.
The initial protocol mismatch in the features file is a feedback problem (getting an overview of internal protocol conformance), and during the accident they had the necessary control actions to fix the issue: copy an older features file. The reason they couldn’t do so right away was they had no idea what was going on.
Thus, the critical two questions are
- Does the Cloudflare organisation deliberately design the human–computer interfaces used by their operators?
- Does Cloudflare actively think about how their operators can get a better understanding of the ways in which the system works, and doesn’t work?
The blog post suggests no.
There are more questions for those interested in details. First off, this is a simplified control model as best as I can piece it together in a few minutes. We’ll focus on the highlighted control actions because they were most proximate to the accident in question.

Storming through the stpa process very sloppily, we’ll come up with several questions which are not brought up by the report. Maybe some of these questions are obviously answered in a Cloudflare control panel or help document. I’m not in the market right now so I won’t do that research. But if any of my readers are thinking about adopting Cloudflare, these are things they might want to consider!
- What happens if Bot Management takes too long to assign a score? Does the request by default pass on to the origin after a timeout, or is the request default denied? Is there no timeout, and Cloudflare holds the request until the client is tired of waiting?
- Depending on how Bot Management is built and how it interacts with timeouts, can it assign a score to a request that is gone from the system, i.e. has already been passed on to the origin or even produced a response back to the client? What are the effects of that?
- What happens if Bot Management tries to read features from a request that is gone from the system?
- Can Ingress call for a score judgment when Bot Management is not running? What are the effects of that? What happens if Ingress thinks Bot Management did not assign a score even though it did?
- How are requests treated when there’s a problem processing them – are they passed through or rejected?
- The feature file is a protocol used to communicate between services. Is this protocol (and any other such protocols) well-specified? Are engineers working on both sides of the communication aware of that? How does Cloudflare track compliance of internal protocol implementations?
- How long can Bot Management run with an outdated features file before someone is made aware? Is there a way for Bot Management to not pick up a created features file? Will the features file generator be made aware?
- Can the feature file generator create a feature file that is not signalful of bottiness? Can Bot Management tell some of these cases apart and choose not to apply a score derived from such features? Does the feature file generator get that feedback?
- What is the process by which Cloudflare operators can reconfigure request flow, e.g. toggle out misbehaving components? But perhaps more critically, what sort of information would they be basing such decisions on?
- What is the feedback path to Cloudflare operators from the observability tools that annotate core dumps with debugging information? They consume significant resources, but are there results mostly dumped somewhere nobody looks?
- Aside from the coincidentally unavailable status page, what other pieces of misleading information did Cloudflare operators have to deal with? How can that be reduced?
I don’t know. I wish technical organisations would be more thorough in investigating accidents.